 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural2Speech: A Transfer Learning Framework for Neural-Driven Speech Reconstruction
Oct 07, 2023Reconstructing natural speech from neural activity is vital for enabling direct communication via brain-computer interfaces. Previous efforts have explored the conversion of neural recordings into speech using complex deep neural network (DNN) models trained on extensive neural recording data, which is resource-intensive under regular clinical constraints. However, achieving satisfactory performance in reconstructing speech from limited-scale neural recordings has been challenging, mainly due to the complexity of speech representations and the neural data constraints. To overcome these challenges, we propose a novel transfer learning framework for neural-driven speech reconstruction, called Neural2Speech, which consists of two distinct training phases. First, a speech autoencoder is pre-trained on readily available speech corpora to decode speech waveforms from the encoded speech representations. Second, a lightweight adaptor is trained on the small-scale neural recordings to align the neural activity and the speech representation for decoding. Remarkably, our proposed Neural2Speech demonstrates the feasibility of neural-driven speech reconstruction even with only 20 minutes of intracranial data, which significantly outperforms existing baseline methods in terms of speech fidelity and intelligibility.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Denoised Internal Models: a Brain-Inspired Autoencoder against Adversarial Attacks
Nov 21, 2021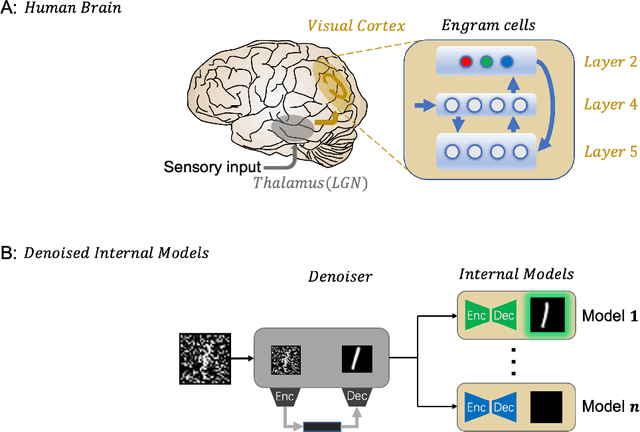
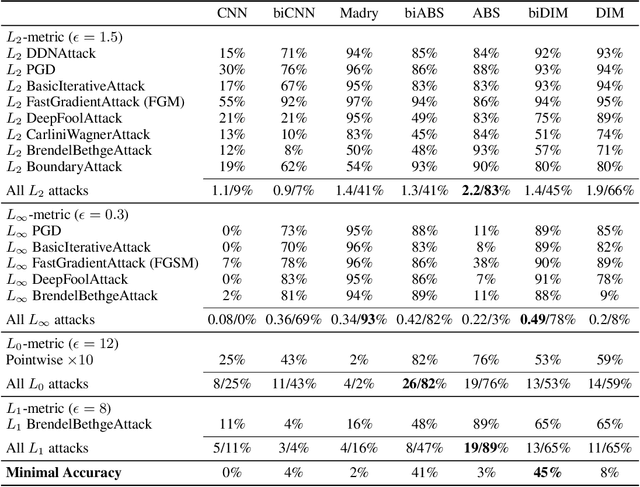
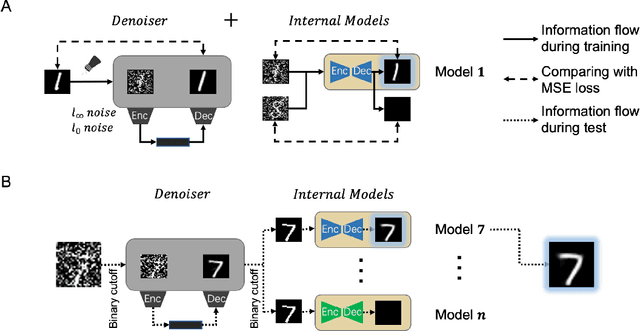
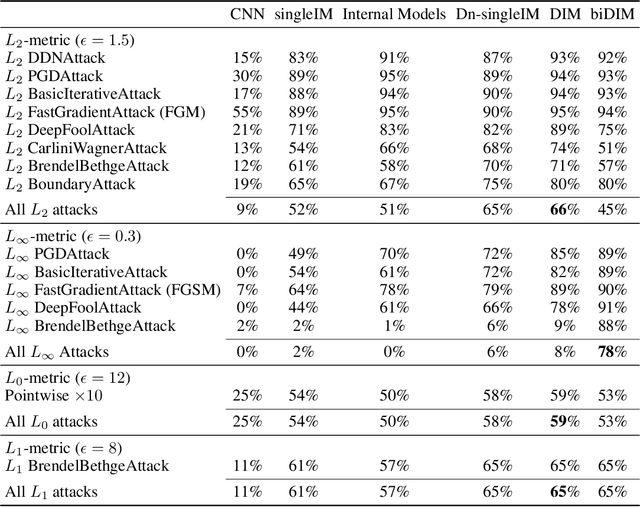
Despite its great success, deep learning severely suffers from robustness; that is, deep neural networks are very vulnerable to adversarial attacks, even the simplest ones. Inspired by recent advances in brain science, we propose the Denoised Internal Models (DIM), a novel generative autoencoder-based model to tackle this challenge. Simulating the pipeline in the human brain for visual signal processing, DIM adopts a two-stage approach. In the first stage, DIM uses a denoiser to reduce the noise and the dimensions of inputs, reflecting the information pre-processing in the thalamus. Inspired from the sparse coding of memory-related traces in the primary visual cortex, the second stage produces a set of internal models, one for each category. We evaluate DIM over 42 adversarial attacks, showing that DIM effectively defenses against all the attacks and outperforms the SOTA on the overall robustness.