 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAC: Pronunciation-Aware Contextualized Large Language Model-based Automatic Speech Recognition
Sep 16, 2025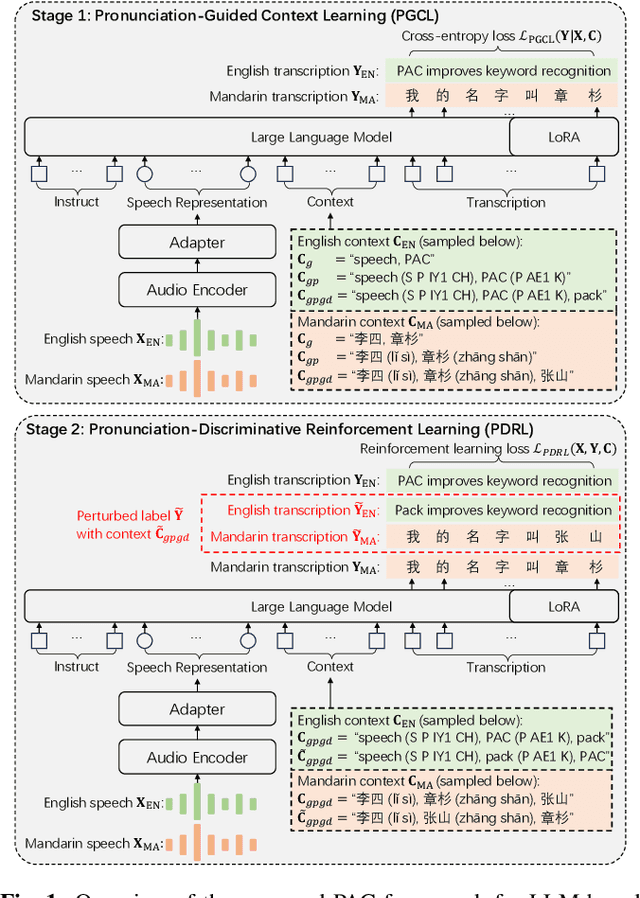
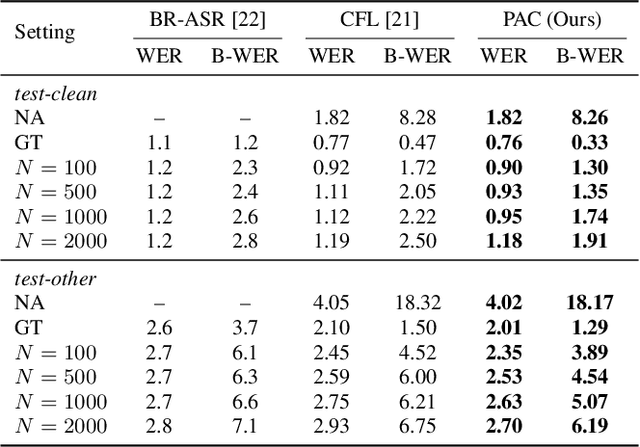
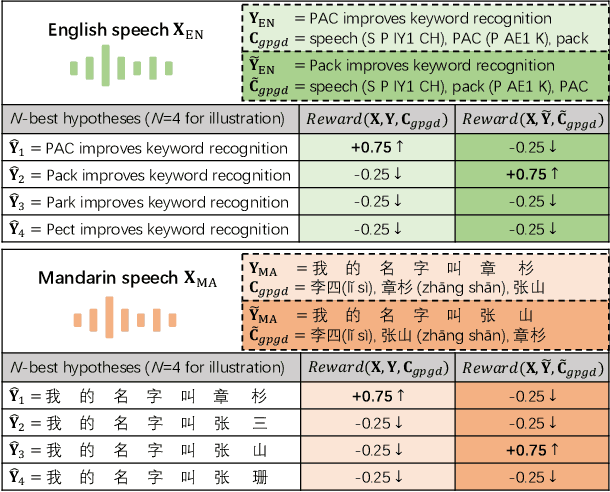
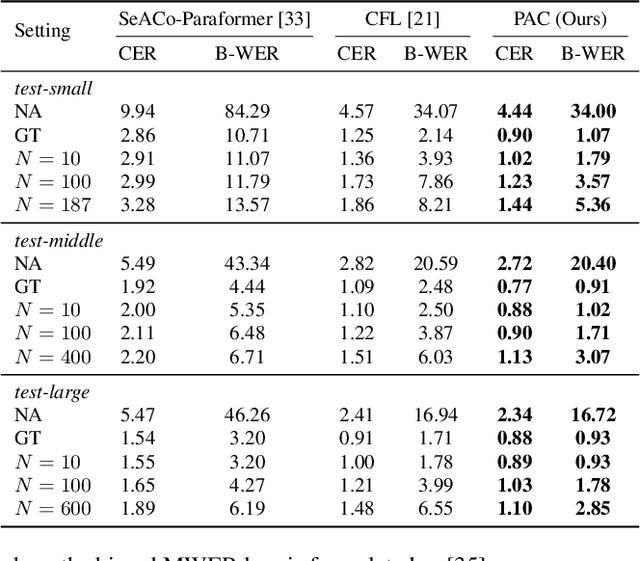
This paper presents a Pronunciation-Aware Contextualized (PAC) framework to address two key challenges in Large Language Model (LLM)-based Automatic Speech Recognition (ASR) systems: effective pronunciation modeling and robust homophone discrimination. Both are essential for raw or long-tail word recognition. The proposed approach adopts a two-stage learning paradigm. First, we introduce a pronunciation-guided context learning method. It employs an interleaved grapheme-phoneme context modeling strategy that incorporates grapheme-only distractors, encouraging the model to leverage phonemic cues for accurate recognition. Then, we propose a pronunciation-discriminative reinforcement learning method with perturbed label sampling to further enhance the model\'s ability to distinguish contextualized homophones. Experimental results on the public English Librispeech and Mandarin AISHELL-1 datasets indicate that PAC: (1) reduces relative Word Error Rate (WER) by 30.2% and 53.8% compared to pre-trained LLM-based ASR models, and (2) achieves 31.8% and 60.5% relative reductions in biased WER for long-tail words compared to strong baselines, respectively.
UME: Upcycling Mixture-of-Experts for Scalable and Efficient Automatic Speech Recognition
Dec 23, 2024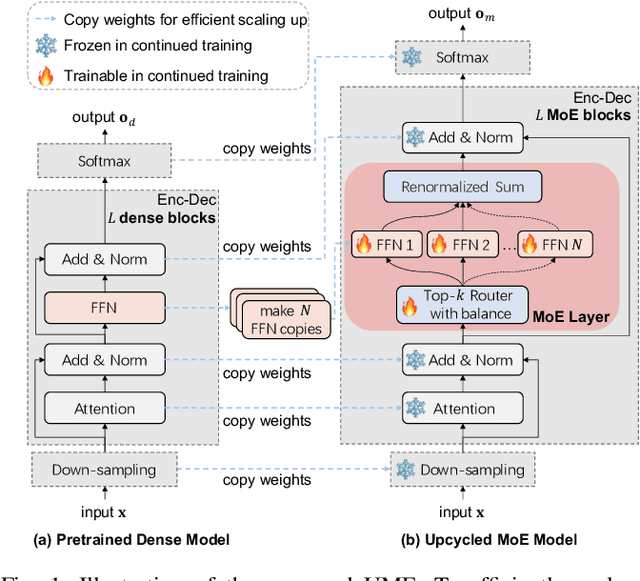
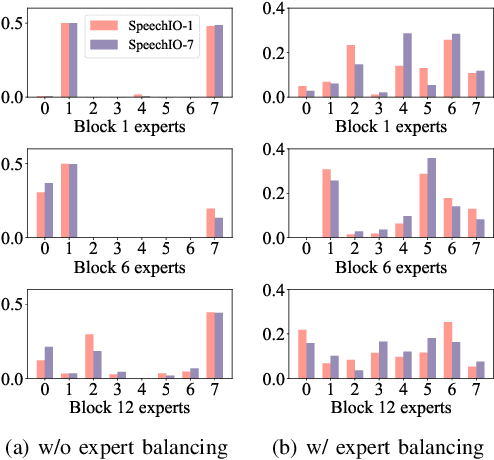

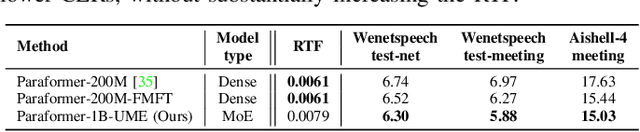
Recent advancements in scaling up models have significantly improved performance in Automatic Speech Recognition (ASR) tasks. However, training large ASR models from scratch remains costly. To address this issue, we introduce UME, a novel method that efficiently Upcycles pretrained dense ASR checkpoints into larger Mixture-of-Experts (MoE) architectures. Initially, feed-forward networks are converted into MoE layers. By reusing the pretrained weights, we establish a robust foundation for the expanded model, significantly reducing optimization time. Then, layer freezing and expert balancing strategies are employed to continue training the model, further enhancing performance. Experiments on a mixture of 170k-hour Mandarin and English datasets show that UME: 1) surpasses the pretrained baseline by a margin of 11.9% relative error rate reduction while maintaining comparable latency; 2) reduces training time by up to 86.7% and achieves superior accuracy compared to training models of the same size from scratch.
Neural2Speech: A Transfer Learning Framework for Neural-Driven Speech Reconstruction
Oct 07, 2023Reconstructing natural speech from neural activity is vital for enabling direct communication via brain-computer interfaces. Previous efforts have explored the conversion of neural recordings into speech using complex deep neural network (DNN) models trained on extensive neural recording data, which is resource-intensive under regular clinical constraints. However, achieving satisfactory performance in reconstructing speech from limited-scale neural recordings has been challenging, mainly due to the complexity of speech representations and the neural data constraints. To overcome these challenges, we propose a novel transfer learning framework for neural-driven speech reconstruction, called Neural2Speech, which consists of two distinct training phases. First, a speech autoencoder is pre-trained on readily available speech corpora to decode speech waveforms from the encoded speech representations. Second, a lightweight adaptor is trained on the small-scale neural recordings to align the neural activity and the speech representation for decoding. Remarkably, our proposed Neural2Speech demonstrates the feasibility of neural-driven speech reconstruction even with only 20 minutes of intracranial data, which significantly outperforms existing baseline methods in terms of speech fidelity and intelligibility.
Do self-supervised speech and language models extract similar representations as human brain?
Oct 07, 2023



Speech and language models trained through self-supervised learning (SSL) demonstrate strong alignment with brain activity during speech and language perception. However, given their distinct training modalities, it remains unclear whether they correlate with the same neural aspects. We directly address this question by evaluating the brain prediction performance of two representative SSL models, Wav2Vec2.0 and GPT-2, designed for speech and language tasks. Our findings reveal that both models accurately predict speech responses in the auditory cortex, with a significant correlation between their brain predictions. Notably, shared speech contextual information between Wav2Vec2.0 and GPT-2 accounts for the majority of explained variance in brain activity, surpassing static semantic and lower-level acoustic-phonetic information. These results underscore the convergence of speech contextual representations in SSL models and their alignment with the neural network underlying speech perception, offering valuable insights into both SSL models and the neural basis of speech and language processing.
OTF: Optimal Transport based Fusion of Supervised and Self-Supervised Learning Models for Automatic Speech Recognition
Jun 05, 2023



Self-Supervised Learning (SSL) Automatic Speech Recognition (ASR) models have shown great promise over Supervised Learning (SL) ones in low-resource settings. However, the advantages of SSL are gradually weakened when the amount of labeled data increases in many industrial applications. To further improve the ASR performance when abundant labels are available, we first explore the potential of combining SL and SSL ASR models via analyzing their complementarity in recognition accuracy and optimization property. Then, we propose a novel Optimal Transport based Fusion (OTF) method for SL and SSL models without incurring extra computation cost in inference. Specifically, optimal transport is adopted to softly align the layer-wise weights to unify the two different networks into a single one. Experimental results on the public 1k-hour English LibriSpeech dataset and our in-house 2.6k-hour Chinese dataset show that OTF largely outperforms the individual models with lower error rates.
UFO2: A unified pre-training framework for online and offline speech recognition
Oct 26, 2022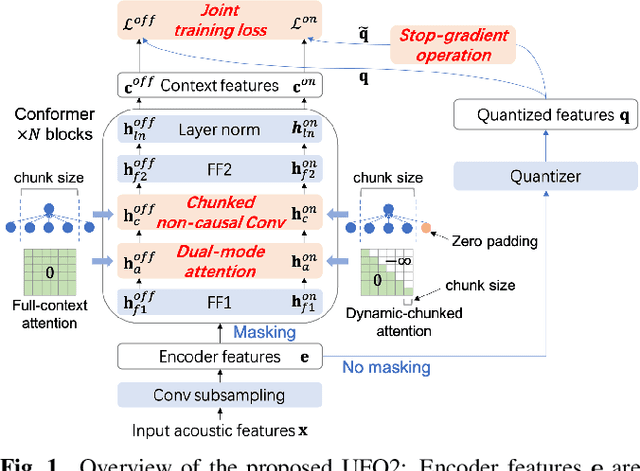
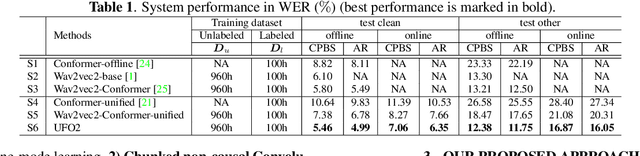

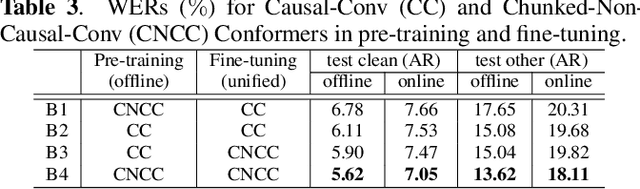
In this paper, we propose a Unified pre-training Framework for Online and Offline (UFO2) Automatic Speech Recognition (ASR), which 1) simplifies the two separate training workflows for online and offline modes into one process, and 2) improves the Word Error Rate (WER) performance with limited utterance annotating. Specifically, we extend the conventional offline-mode Self-Supervised Learning (SSL)-based ASR approach to a unified manner, where the model training is conditioned on both the full-context and dynamic-chunked inputs. To enhance the pre-trained representation model, stop-gradient operation is applied to decouple the online-mode objectives to the quantizer. Moreover, in both the pre-training and the downstream fine-tuning stages, joint losses are proposed to train the unified model with full-weight sharing for the two modes. Experimental results on the LibriSpeech dataset show that UFO2 outperforms the SSL-based baseline method by 29.7% and 18.2% relative WER reduction in offline and online modes, respectively.
SCaLa: Supervised Contrastive Learning for End-to-End Automatic Speech Recognition
Oct 08, 2021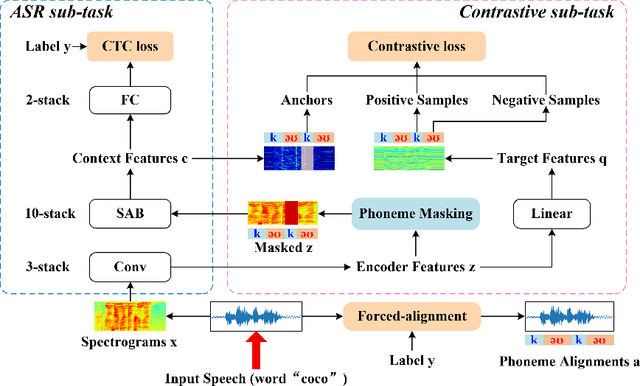
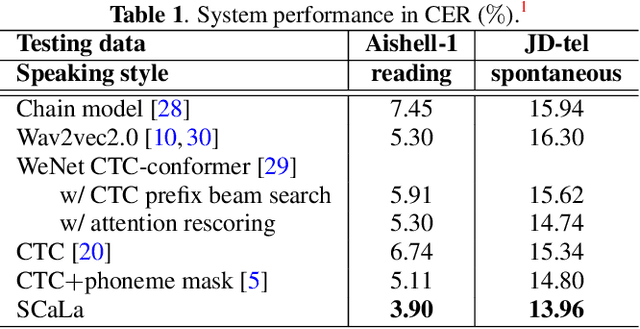
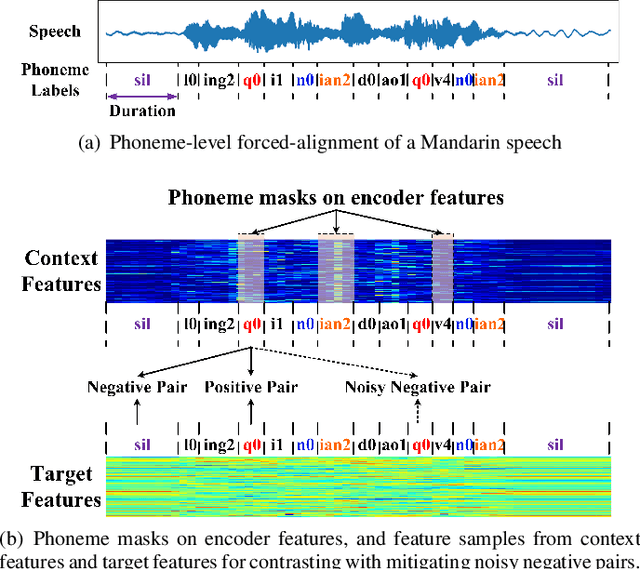
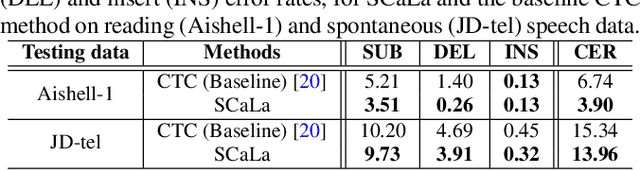
End-to-end Automatic Speech Recognition (ASR) models are usually trained to reduce the losses of the whole token sequences, while neglecting explicit phonemic-granularity supervision. This could lead to recognition errors due to similar-phoneme confusion or phoneme reduction. To alleviate this problem, this paper proposes a novel framework of Supervised Contrastive Learning (SCaLa) to enhance phonemic information learning for end-to-end ASR systems. Specifically, we introduce the self-supervised Masked Contrastive Predictive Coding (MCPC) into the fully-supervised setting. To supervise phoneme learning explicitly, SCaLa first masks the variable-length encoder features corresponding to phonemes given phoneme forced-alignment extracted from a pre-trained acoustic model, and then predicts the masked phonemes via contrastive learning. The phoneme forced-alignment can mitigate the noise of positive-negative pairs in self-supervised MCPC. Experimental results conducted on reading and spontaneous speech datasets show that the proposed approach achieves 2.84% and 1.38% Character Error Rate (CER) reductions compared to the baseline, respectively.
Incremental Learning for End-to-End Automatic Speech Recognition
May 11, 2020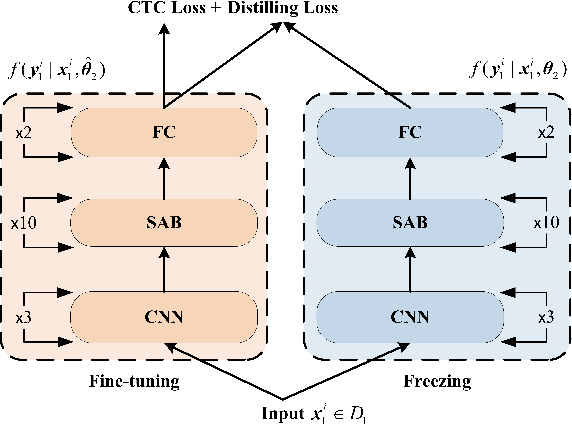
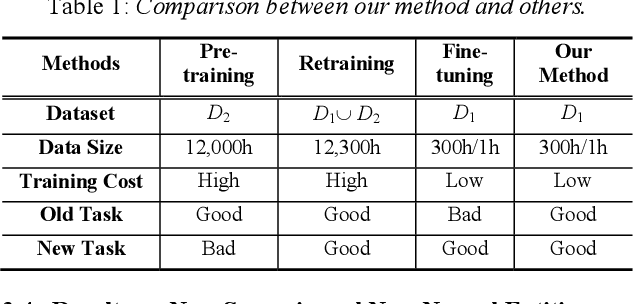
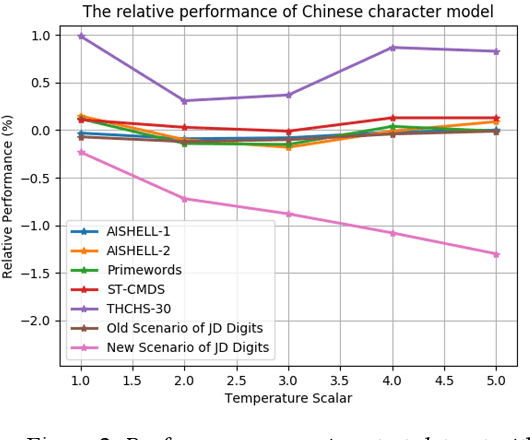
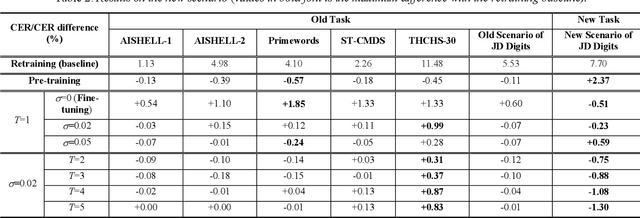
We propose an incremental learning for end-to-end Automatic Speech Recognition (ASR) to extend the model's capacity on a new task while retaining the performance on existing ones. The proposed method is effective without accessing to the old dataset to address the issues of high training cost and old dataset unavailability. To achieve this, knowledge distillation is applied as a guidance to retain the recognition ability from the previous model, which is then combined with the new ASR task for model optimization. With an ASR model pre-trained on 12,000h Mandarin speech, we test our proposed method on 300h new scenario task and 1h new named entities task. Experiments show that our method yields 3.25% and 0.88% absolute Character Error Rate (CER) reduction on the new scenario, when compared with the pre-trained model and the full-data retraining baseline, respectively. It even yields a surprising 0.37% absolute CER reduction on the new scenario than the fine-tuning. For the new named entities task, our method significantly improves the accuracy compared with the pre-trained model, i.e. 16.95% absolute CER reduction. For both of the new task adaptions, the new models still maintain a same accuracy with the baseline on the old tasks.
Research on Modeling Units of Transformer Transducer for Mandarin Speech Recognition
Apr 26, 2020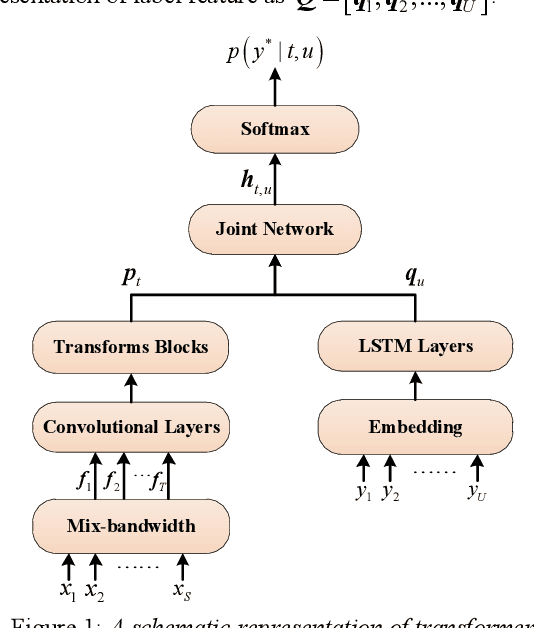
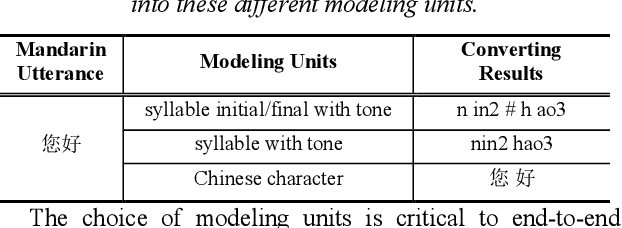
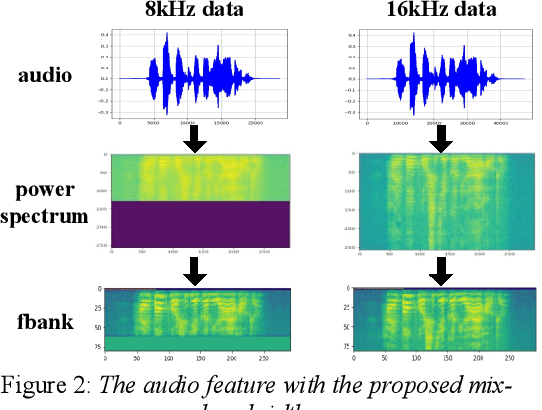

Modeling unit and model architecture are two key factors of Recurrent Neural Network Transducer (RNN-T) in end-to-end speech recognition. To improve the performance of RNN-T for Mandarin speech recognition task, a novel transformer transducer with the combination architecture of self-attention transformer and RNN is proposed. And then the choice of different modeling units for transformer transducer is explored. In addition, we present a new mix-bandwidth training method to obtain a general model that is able to accurately recognize Mandarin speech with different sampling rates simultaneously. All of our experiments are conducted on about 12,000 hours of Mandarin speech with sampling rate in 8kHz and 16kHz. Experimental results show that Mandarin transformer transducer using syllable with tone achieves the best performance. It yields an average of 14.4% and 44.1% relative Word Error Rate (WER) reduction when compared with the models using syllable initial/final with tone and Chinese character, respectively. Also, it outperforms the model based on syllable initial/final with tone with an average of 13.5% relative Character Error Rate (CER) reduction.
DNANet: De-Normalized Attention Based Multi-Resolution Network for Human Pose Estimation
Oct 21, 2019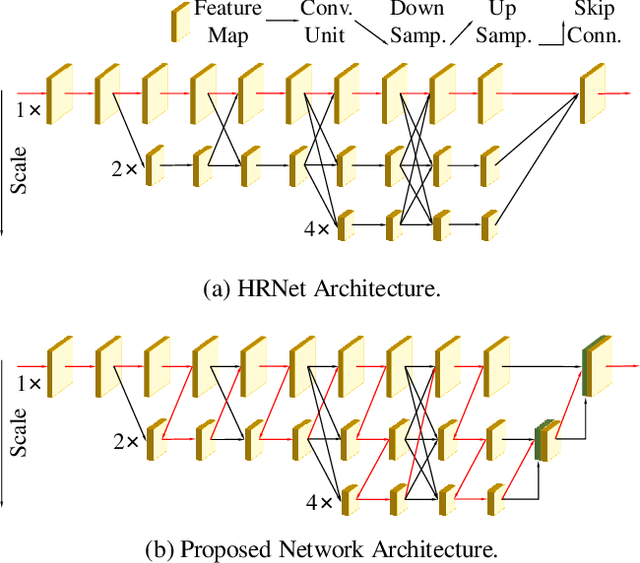
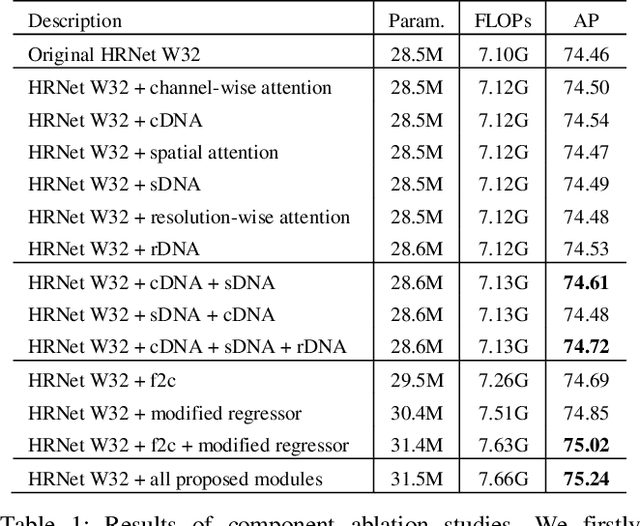
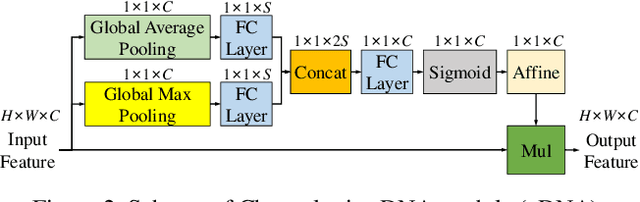
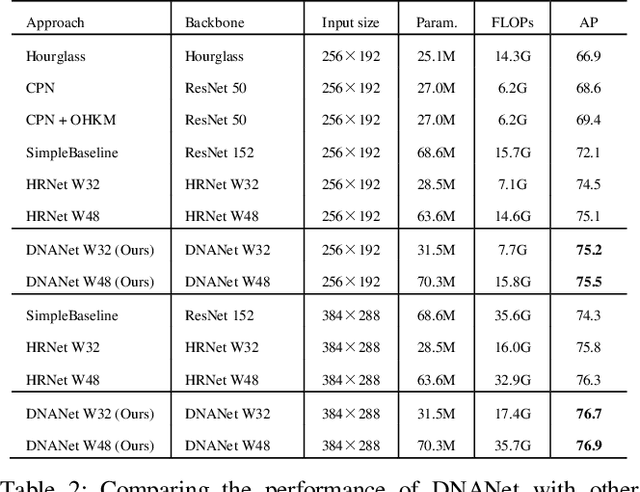
Recently, multi-resolution networks (such as Hourglass, CPN, HRNet, etc.) have achieved significant performance on the task of human pose estimation by combining features from various resolutions. In this paper, we propose a novel type of attention module, namely De-Normalized Attention (DNA) to deal with the feature attenuations of conventional attention modules. Our method extends the original HRNet with spatial, channel-wise and resolution-wise DNAs, which aims at evaluating the importance of features from different locations, channels and resolutions to enhance the network capability for feature representation. We also propose to add fine-to-coarse connections across high-to-low resolutions in-side each layer of HRNet to increase the maximum depth of network topology. In addition, we propose to modify the keypoint regressor at the end of HRNet for accurate keypoint heatmap prediction. The effectiveness of our proposed network is demonstrated on COCO keypoint detection dataset, achieving state-of-the-art performance at 77.6 AP score on COCO val2017 dataset without using extra keypoint training data. Our paper will be accompanied with publicly available codes at GitHub.