 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Learning for End-to-End Automatic Speech Recognition
Paper and Code
May 11, 2020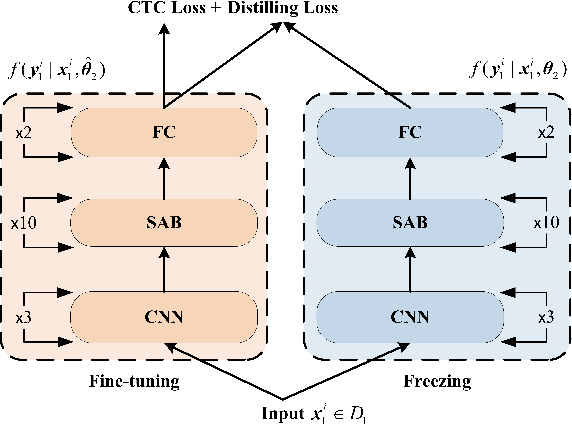
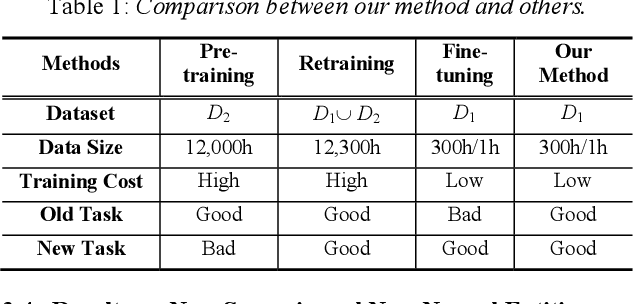
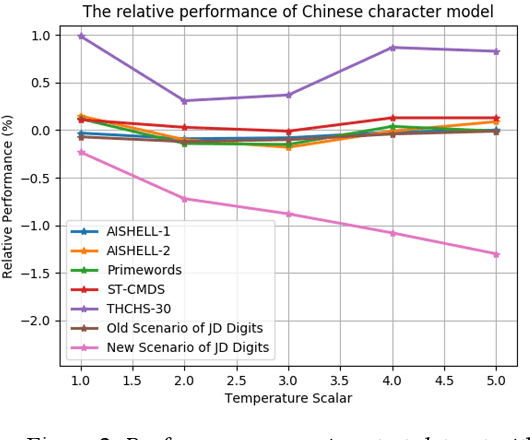
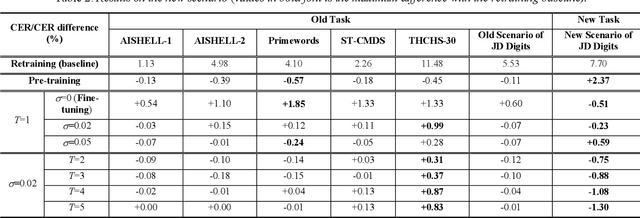
We propose an incremental learning for end-to-end Automatic Speech Recognition (ASR) to extend the model's capacity on a new task while retaining the performance on existing ones. The proposed method is effective without accessing to the old dataset to address the issues of high training cost and old dataset unavailability. To achieve this, knowledge distillation is applied as a guidance to retain the recognition ability from the previous model, which is then combined with the new ASR task for model optimization. With an ASR model pre-trained on 12,000h Mandarin speech, we test our proposed method on 300h new scenario task and 1h new named entities task. Experiments show that our method yields 3.25% and 0.88% absolute Character Error Rate (CER) reduction on the new scenario, when compared with the pre-trained model and the full-data retraining baseline, respectively. It even yields a surprising 0.37% absolute CER reduction on the new scenario than the fine-tuning. For the new named entities task, our method significantly improves the accuracy compared with the pre-trained model, i.e. 16.95% absolute CER reduction. For both of the new task adaptions, the new models still maintain a same accuracy with the baseline on the old tasks.