 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Heatmap-Style Jigsaw Puzzles Provides Good Pretraining for 2D Human Pose Estimation
Dec 13, 2020
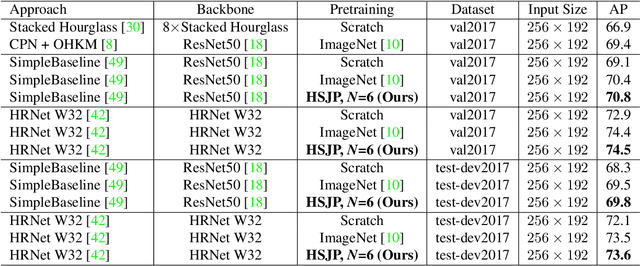

The target of 2D human pose estimation is to locate the keypoints of body parts from input 2D images. State-of-the-art methods for pose estimation usually construct pixel-wise heatmaps from keypoints as labels for learning convolution neural networks, which are usually initialized randomly or using classification models on ImageNet as their backbones. We note that 2D pose estimation task is highly dependent on the contextual relationship between image patches, thus we introduce a self-supervised method for pretraining 2D pose estimation networks. Specifically, we propose Heatmap-Style Jigsaw Puzzles (HSJP) problem as our pretext-task, whose target is to learn the location of each patch from an image composed of shuffled patches. During our pretraining process, we only use images of person instances in MS-COCO, rather than introducing extra and much larger ImageNet dataset. A heatmap-style label for patch location is designed and our learning process is in a non-contrastive way. The weights learned by HSJP pretext task are utilised as backbones of 2D human pose estimator, which are then finetuned on MS-COCO human keypoints dataset. With two popular and strong 2D human pose estimators, HRNet and SimpleBaseline, we evaluate mAP score on both MS-COCO validation and test-dev datasets. Our experiments show that downstream pose estimators with our self-supervised pretraining obtain much better performance than those trained from scratch, and are comparable to those using ImageNet classification models as their initial backbones.
DNANet: De-Normalized Attention Based Multi-Resolution Network for Human Pose Estimation
Oct 21, 2019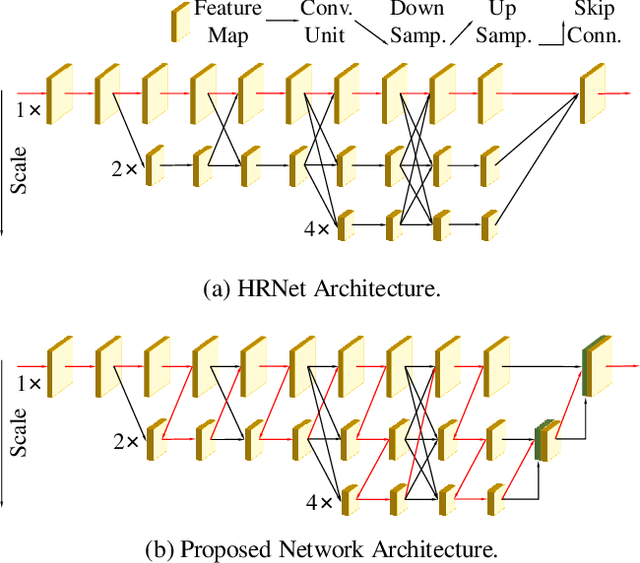
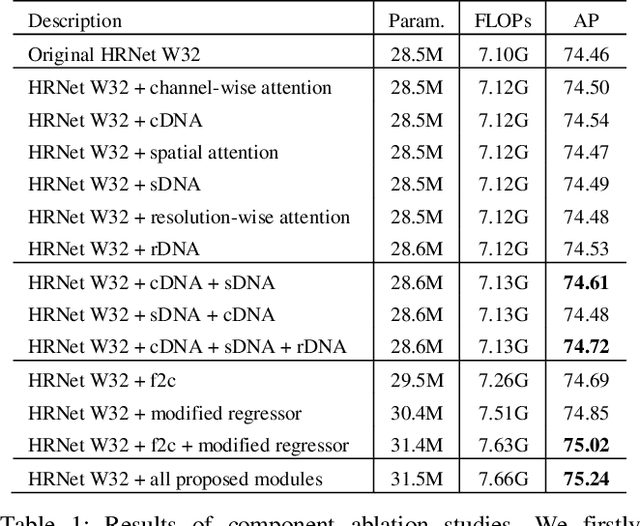
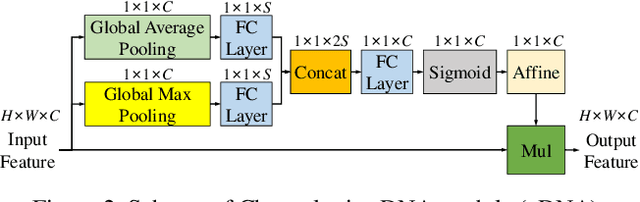
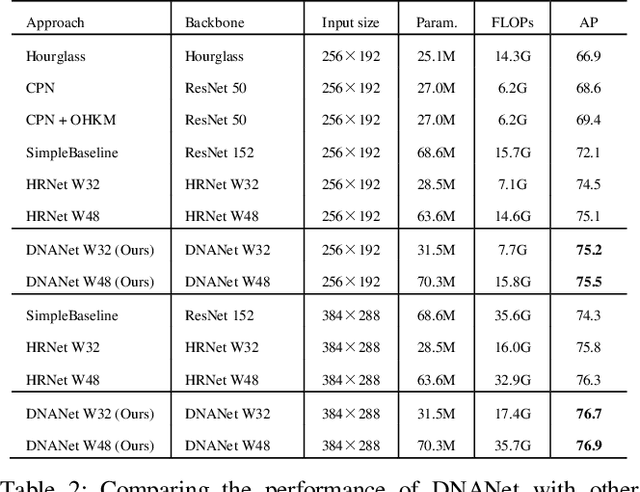
Recently, multi-resolution networks (such as Hourglass, CPN, HRNet, etc.) have achieved significant performance on the task of human pose estimation by combining features from various resolutions. In this paper, we propose a novel type of attention module, namely De-Normalized Attention (DNA) to deal with the feature attenuations of conventional attention modules. Our method extends the original HRNet with spatial, channel-wise and resolution-wise DNAs, which aims at evaluating the importance of features from different locations, channels and resolutions to enhance the network capability for feature representation. We also propose to add fine-to-coarse connections across high-to-low resolutions in-side each layer of HRNet to increase the maximum depth of network topology. In addition, we propose to modify the keypoint regressor at the end of HRNet for accurate keypoint heatmap prediction. The effectiveness of our proposed network is demonstrated on COCO keypoint detection dataset, achieving state-of-the-art performance at 77.6 AP score on COCO val2017 dataset without using extra keypoint training data. Our paper will be accompanied with publicly available codes at GitHub.