 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Loop: Universal Repository Representation with RPG-Encoder
Feb 03, 2026Current repository agents encounter a reasoning disconnect due to fragmented representations, as existing methods rely on isolated API documentation or dependency graphs that lack semantic depth. We consider repository comprehension and generation to be inverse processes within a unified cycle: generation expands intent into implementation, while comprehension compresses implementation back into intent. To address this, we propose RPG-Encoder, a framework that generalizes the Repository Planning Graph (RPG) from a static generative blueprint into a unified, high-fidelity representation. RPG-Encoder closes the reasoning loop through three mechanisms: (1) Encoding raw code into the RPG that combines lifted semantic features with code dependencies; (2) Evolving the topology incrementally to decouple maintenance costs from repository scale, reducing overhead by 95.7%; and (3) Operating as a unified interface for structure-aware navigation. In evaluations, RPG-Encoder establishes state-of-the-art localization performance on SWE-bench Verified with 93.7% Acc@5 and exceeds the best baseline by over 10% in localization accuracy on SWE-bench Live Lite. These results highlight our superior fine-grained precision in complex codebases. Furthermore, it achieves 98.5% reconstruction coverage on RepoCraft, confirming RPG's high-fidelity capacity to mirror the original codebase and closing the loop between intent and implementation.
11Plus-Bench: Demystifying Multimodal LLM Spatial Reasoning with Cognitive-Inspired Analysis
Aug 27, 2025For human cognitive process, spatial reasoning and perception are closely entangled, yet the nature of this interplay remains underexplored in the evaluation of multimodal large language models (MLLMs). While recent MLLM advancements show impressive performance on reasoning, their capacity for human-like spatial cognition remains an open question. In this work, we introduce a systematic evaluation framework to assess the spatial reasoning abilities of state-of-the-art MLLMs relative to human performance. Central to our work is 11Plus-Bench, a high-quality benchmark derived from realistic standardized spatial aptitude tests. 11Plus-Bench also features fine-grained expert annotations of both perceptual complexity and reasoning process, enabling detailed instance-level analysis of model behavior. Through extensive experiments across 14 MLLMs and human evaluation, we find that current MLLMs exhibit early signs of spatial cognition. Despite a large performance gap compared to humans, MLLMs' cognitive profiles resemble those of humans in that cognitive effort correlates strongly with reasoning-related complexity. However, instance-level performance in MLLMs remains largely random, whereas human correctness is highly predictable and shaped by abstract pattern complexity. These findings highlight both emerging capabilities and limitations in current MLLMs' spatial reasoning capabilities and provide actionable insights for advancing model design.
OTF: Optimal Transport based Fusion of Supervised and Self-Supervised Learning Models for Automatic Speech Recognition
Jun 05, 2023



Self-Supervised Learning (SSL) Automatic Speech Recognition (ASR) models have shown great promise over Supervised Learning (SL) ones in low-resource settings. However, the advantages of SSL are gradually weakened when the amount of labeled data increases in many industrial applications. To further improve the ASR performance when abundant labels are available, we first explore the potential of combining SL and SSL ASR models via analyzing their complementarity in recognition accuracy and optimization property. Then, we propose a novel Optimal Transport based Fusion (OTF) method for SL and SSL models without incurring extra computation cost in inference. Specifically, optimal transport is adopted to softly align the layer-wise weights to unify the two different networks into a single one. Experimental results on the public 1k-hour English LibriSpeech dataset and our in-house 2.6k-hour Chinese dataset show that OTF largely outperforms the individual models with lower error rates.
UFO2: A unified pre-training framework for online and offline speech recognition
Oct 26, 2022In this paper, we propose a Unified pre-training Framework for Online and Offline (UFO2) Automatic Speech Recognition (ASR), which 1) simplifies the two separate training workflows for online and offline modes into one process, and 2) improves the Word Error Rate (WER) performance with limited utterance annotating. Specifically, we extend the conventional offline-mode Self-Supervised Learning (SSL)-based ASR approach to a unified manner, where the model training is conditioned on both the full-context and dynamic-chunked inputs. To enhance the pre-trained representation model, stop-gradient operation is applied to decouple the online-mode objectives to the quantizer. Moreover, in both the pre-training and the downstream fine-tuning stages, joint losses are proposed to train the unified model with full-weight sharing for the two modes. Experimental results on the LibriSpeech dataset show that UFO2 outperforms the SSL-based baseline method by 29.7% and 18.2% relative WER reduction in offline and online modes, respectively.
Table2Charts: Learning Shared Representations for Recommending Charts on Multi-dimensional Data
Aug 24, 2020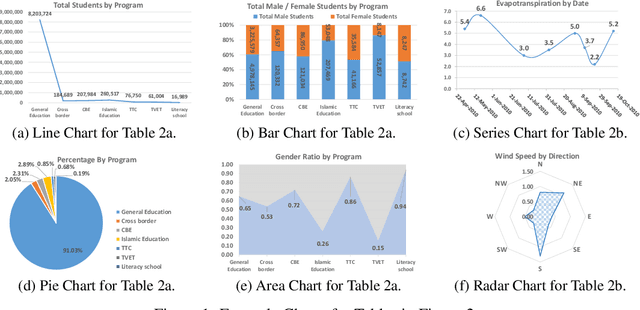
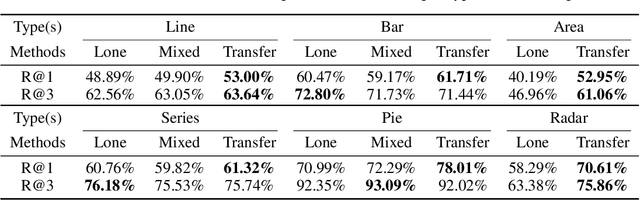
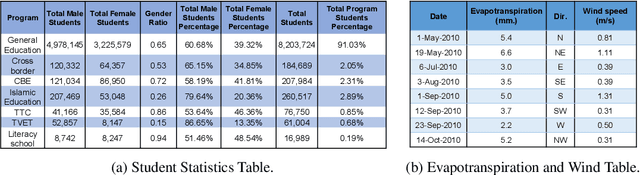
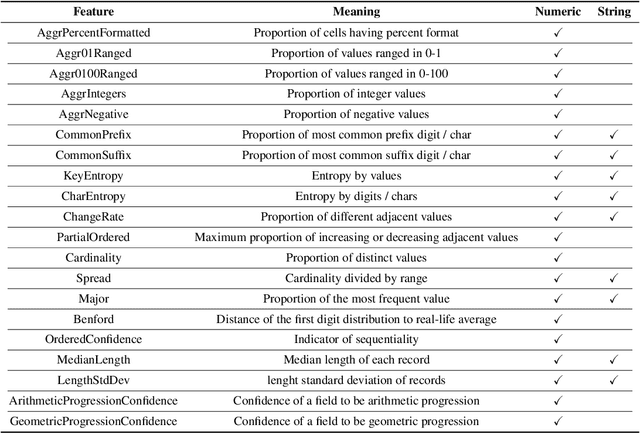
It is common for people to create different types of charts to explore a multi-dimensional dataset (table). However, to build an intelligent assistant that recommends commonly composed charts, the fundamental problems of "multi-dialect" unification, imbalanced data and open vocabulary exist. In this paper, we propose Table2Charts framework which learns common patterns from a large corpus of (table, charts) pairs. Based on deep Q-learning with copying mechanism and heuristic searching, Table2Charts does table-to-sequence generation, where each sequence follows a chart template. On a large spreadsheet corpus with 196k tables and 306k charts, we show that Table2Charts could learn a shared representation of table fields so that tasks on different chart types could mutually enhance each other. Table2Charts has >0.61 recall at top-3 and >0.49 recall at top-1 for both single-type and multi-type chart recommendation tasks.