 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTestExplora: Benchmarking LLMs for Proactive Bug Discovery via Repository-Level Test Generation
Feb 11, 2026Given that Large Language Models (LLMs) are increasingly applied to automate software development, comprehensive software assurance spans three distinct goals: regression prevention, reactive reproduction, and proactive discovery. Current evaluations systematically overlook the third goal. Specifically, they either treat existing code as ground truth (a compliance trap) for regression prevention, or depend on post-failure artifacts (e.g., issue reports) for bug reproduction-so they rarely surface defects before failures. To bridge this gap, we present TestExplora, a benchmark designed to evaluate LLMs as proactive testers within full-scale, realistic repository environments. TestExplora contains 2,389 tasks from 482 repositories and hides all defect-related signals. Models must proactively find bugs by comparing implementations against documentation-derived intent, using documentation as the oracle. Furthermore, to keep evaluation sustainable and reduce leakage, we propose continuous, time-aware data collection. Our evaluation reveals a significant capability gap: state-of-the-art models achieve a maximum Fail-to-Pass (F2P) rate of only 16.06%. Further analysis indicates that navigating complex cross-module interactions and leveraging agentic exploration are critical to advancing LLMs toward autonomous software quality assurance. Consistent with this, SWEAgent instantiated with GPT-5-mini achieves an F2P of 17.27% and an F2P@5 of 29.7%, highlighting the effectiveness and promise of agentic exploration in proactive bug discovery tasks.
Closing the Loop: Universal Repository Representation with RPG-Encoder
Feb 03, 2026Current repository agents encounter a reasoning disconnect due to fragmented representations, as existing methods rely on isolated API documentation or dependency graphs that lack semantic depth. We consider repository comprehension and generation to be inverse processes within a unified cycle: generation expands intent into implementation, while comprehension compresses implementation back into intent. To address this, we propose RPG-Encoder, a framework that generalizes the Repository Planning Graph (RPG) from a static generative blueprint into a unified, high-fidelity representation. RPG-Encoder closes the reasoning loop through three mechanisms: (1) Encoding raw code into the RPG that combines lifted semantic features with code dependencies; (2) Evolving the topology incrementally to decouple maintenance costs from repository scale, reducing overhead by 95.7%; and (3) Operating as a unified interface for structure-aware navigation. In evaluations, RPG-Encoder establishes state-of-the-art localization performance on SWE-bench Verified with 93.7% Acc@5 and exceeds the best baseline by over 10% in localization accuracy on SWE-bench Live Lite. These results highlight our superior fine-grained precision in complex codebases. Furthermore, it achieves 98.5% reconstruction coverage on RepoCraft, confirming RPG's high-fidelity capacity to mirror the original codebase and closing the loop between intent and implementation.
X-Coder: Advancing Competitive Programming with Fully Synthetic Tasks, Solutions, and Tests
Jan 11, 2026Competitive programming presents great challenges for Code LLMs due to its intensive reasoning demands and high logical complexity. However, current Code LLMs still rely heavily on real-world data, which limits their scalability. In this paper, we explore a fully synthetic approach: training Code LLMs with entirely generated tasks, solutions, and test cases, to empower code reasoning models without relying on real-world data. To support this, we leverage feature-based synthesis to propose a novel data synthesis pipeline called SynthSmith. SynthSmith shows strong potential in producing diverse and challenging tasks, along with verified solutions and tests, supporting both supervised fine-tuning and reinforcement learning. Based on the proposed synthetic SFT and RL datasets, we introduce the X-Coder model series, which achieves a notable pass rate of 62.9 avg@8 on LiveCodeBench v5 and 55.8 on v6, outperforming DeepCoder-14B-Preview and AReal-boba2-14B despite having only 7B parameters. In-depth analysis reveals that scaling laws hold on our synthetic dataset, and we explore which dimensions are more effective to scale. We further provide insights into code-centric reinforcement learning and highlight the key factors that shape performance through detailed ablations and analysis. Our findings demonstrate that scaling high-quality synthetic data and adopting staged training can greatly advance code reasoning, while mitigating reliance on real-world coding data.
NMPC-based Motion Planning with Adaptive Weighting for Dynamic Object Interception
Nov 19, 2025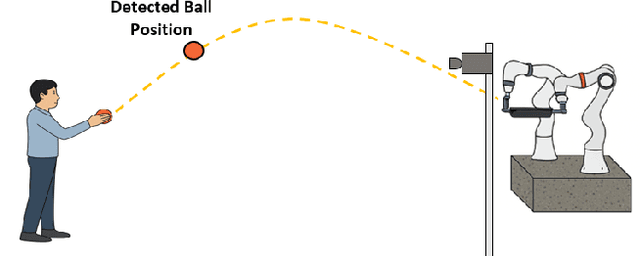

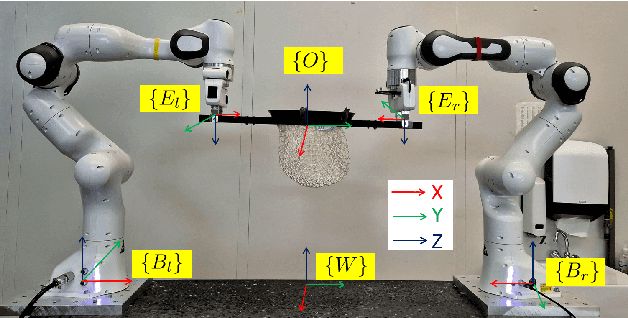
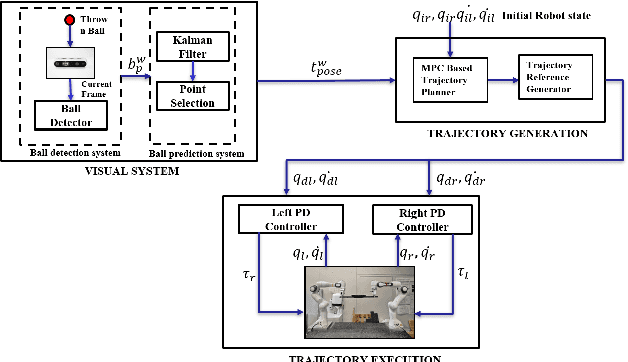
Catching fast-moving objects serves as a benchmark for robotic agility, posing significant coordination challenges for cooperative manipulator systems holding a catcher, particularly due to inherent closed-chain constraints. This paper presents a nonlinear model predictive control (MPC)-based motion planner that bridges high-level interception planning with real-time joint space control, enabling dynamic object interception for systems comprising two cooperating arms. We introduce an Adaptive- Terminal (AT) MPC formulation featuring cost shaping, which contrasts with a simpler Primitive-Terminal (PT) approach relying heavily on terminal penalties for rapid convergence. The proposed AT formulation is shown to effectively mitigate issues related to actuator power limit violations frequently encountered with the PT strategy, yielding trajectories and significantly reduced control effort. Experimental results on a robotic platform with two cooperative arms, demonstrating excellent real time performance, with an average planner cycle computation time of approximately 19 ms-less than half the 40 ms system sampling time. These results indicate that the AT formulation achieves significantly improved motion quality and robustness with minimal computational overhead compared to the PT baseline, making it well-suited for dynamic, cooperative interception tasks.
RPG: A Repository Planning Graph for Unified and Scalable Codebase Generation
Sep 19, 2025



Large language models excel at function- and file-level code generation, yet generating complete repositories from scratch remains a fundamental challenge. This process demands coherent and reliable planning across proposal- and implementation-level stages, while natural language, due to its ambiguity and verbosity, is ill-suited for faithfully representing complex software structures. To address this, we introduce the Repository Planning Graph (RPG), a persistent representation that unifies proposal- and implementation-level planning by encoding capabilities, file structures, data flows, and functions in one graph. RPG replaces ambiguous natural language with an explicit blueprint, enabling long-horizon planning and scalable repository generation. Building on RPG, we develop ZeroRepo, a graph-driven framework for repository generation from scratch. It operates in three stages: proposal-level planning and implementation-level refinement to construct the graph, followed by graph-guided code generation with test validation. To evaluate this setting, we construct RepoCraft, a benchmark of six real-world projects with 1,052 tasks. On RepoCraft, ZeroRepo produces repositories averaging nearly 36K LOC, roughly 3.9$\times$ the strongest baseline (Claude Code) and about 64$\times$ other baselines. It attains 81.5% functional coverage and a 69.7% pass rate, exceeding Claude Code by 27.3 and 35.8 percentage points, respectively. Further analysis shows that RPG models complex dependencies, enables progressively more sophisticated planning through near-linear scaling, and enhances LLM understanding of repositories, thereby accelerating agent localization.
Doing good by fighting fraud: Ethical anti-fraud systems for mobile payments
Jun 29, 2021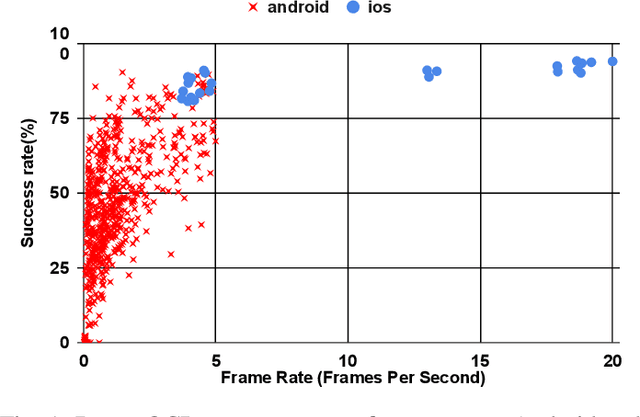
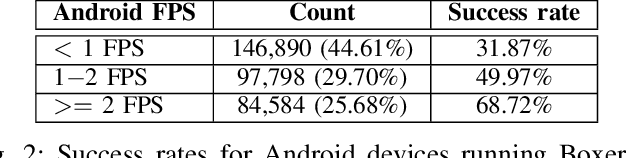
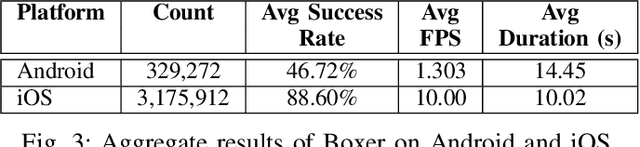
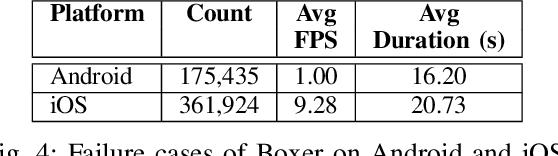
App builders commonly use security challenges, a form of step-up authentication, to add security to their apps. However, the ethical implications of this type of architecture has not been studied previously. In this paper, we present a large-scale measurement study of running an existing anti-fraud security challenge, Boxer, in real apps running on mobile devices. We find that although Boxer does work well overall, it is unable to scan effectively on devices that run its machine learning models at less than one frame per second (FPS), blocking users who use inexpensive devices. With the insights from our study, we design Daredevil, anew anti-fraud system for scanning payment cards that work swell across the broad range of performance characteristics and hardware configurations found on modern mobile devices. Daredevil reduces the number of devices that run at less than one FPS by an order of magnitude compared to Boxer, providing a more equitable system for fighting fraud. In total, we collect data from 5,085,444 real devices spread across 496 real apps running production software and interacting with real users.
Editing Conditional Radiance Fields
Jun 04, 2021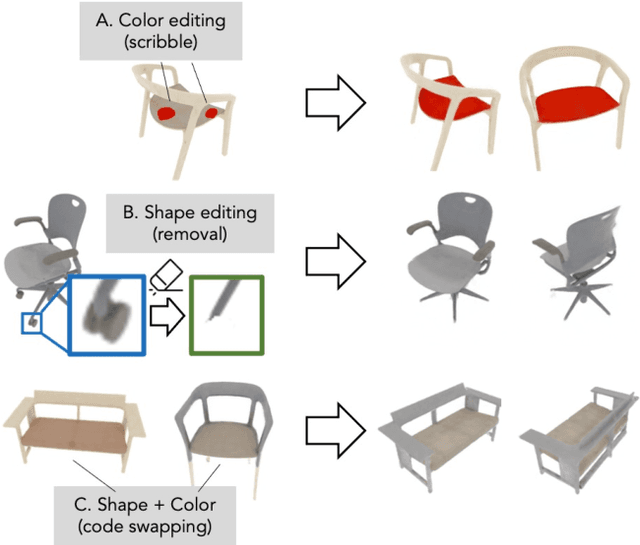
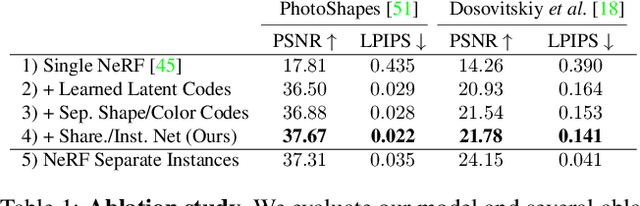
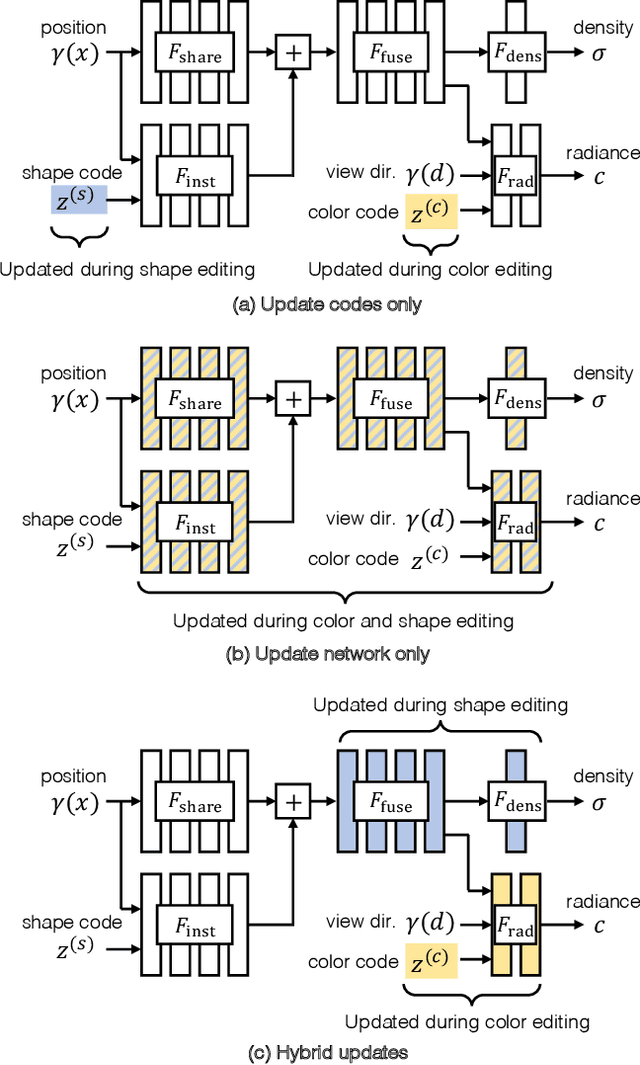

A neural radiance field (NeRF) is a scene model supporting high-quality view synthesis, optimized per scene. In this paper, we explore enabling user editing of a category-level NeRF - also known as a conditional radiance field - trained on a shape category. Specifically, we introduce a method for propagating coarse 2D user scribbles to the 3D space, to modify the color or shape of a local region. First, we propose a conditional radiance field that incorporates new modular network components, including a shape branch that is shared across object instances. Observing multiple instances of the same category, our model learns underlying part semantics without any supervision, thereby allowing the propagation of coarse 2D user scribbles to the entire 3D region (e.g., chair seat). Next, we propose a hybrid network update strategy that targets specific network components, which balances efficiency and accuracy. During user interaction, we formulate an optimization problem that both satisfies the user's constraints and preserves the original object structure. We demonstrate our approach on various editing tasks over three shape datasets and show that it outperforms prior neural editing approaches. Finally, we edit the appearance and shape of a real photograph and show that the edit propagates to extrapolated novel views.
TopoTxR: A Topological Biomarker for Predicting Treatment Response in Breast Cancer
May 13, 2021
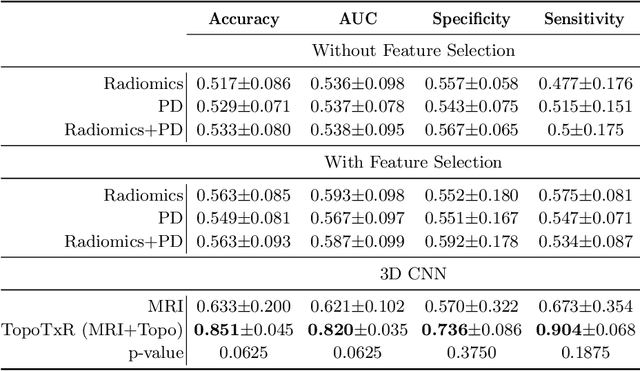
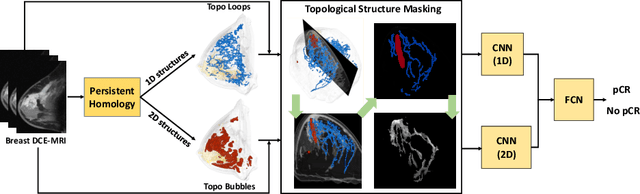
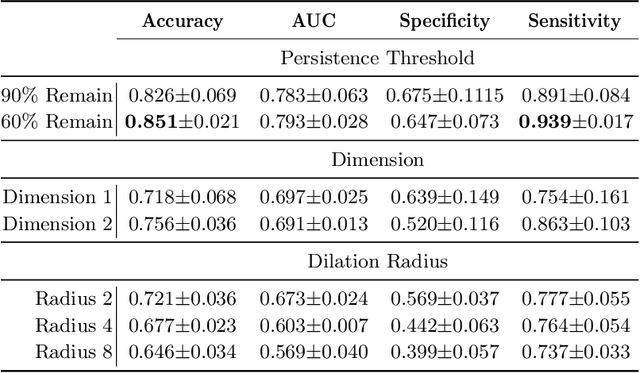
Characterization of breast parenchyma on dynamic contrast-enhanced magnetic resonance imaging (DCE-MRI) is a challenging task owing to the complexity of underlying tissue structures. Current quantitative approaches, including radiomics and deep learning models, do not explicitly capture the complex and subtle parenchymal structures, such as fibroglandular tissue. In this paper, we propose a novel method to direct a neural network's attention to a dedicated set of voxels surrounding biologically relevant tissue structures. By extracting multi-dimensional topological structures with high saliency, we build a topology-derived biomarker, TopoTxR. We demonstrate the efficacy of TopoTxR in predicting response to neoadjuvant chemotherapy in breast cancer. Our qualitative and quantitative results suggest differential topological behavior of breast tissue on treatment-na\"ive imaging, in patients who respond favorably to therapy versus those who do not.
Rewriting a Deep Generative Model
Jul 30, 2020
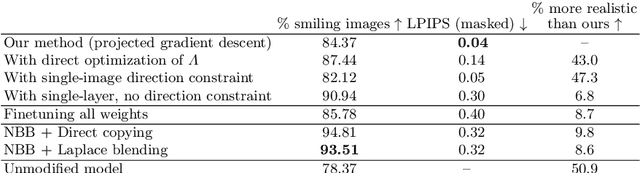
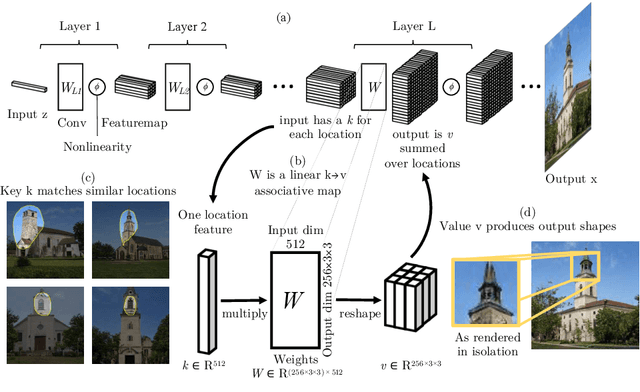
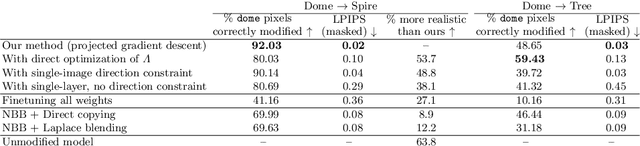
A deep generative model such as a GAN learns to model a rich set of semantic and physical rules about the target distribution, but up to now, it has been obscure how such rules are encoded in the network, or how a rule could be changed. In this paper, we introduce a new problem setting: manipulation of specific rules encoded by a deep generative model. To address the problem, we propose a formulation in which the desired rule is changed by manipulating a layer of a deep network as a linear associative memory. We derive an algorithm for modifying one entry of the associative memory, and we demonstrate that several interesting structural rules can be located and modified within the layers of state-of-the-art generative models. We present a user interface to enable users to interactively change the rules of a generative model to achieve desired effects, and we show several proof-of-concept applications. Finally, results on multiple datasets demonstrate the advantage of our method against standard fine-tuning methods and edit transfer algorithms.
Diverse Image Generation via Self-Conditioned GANs
Jun 18, 2020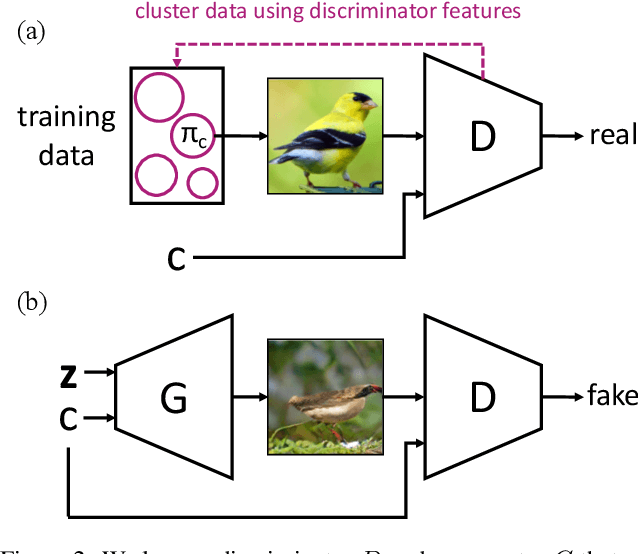
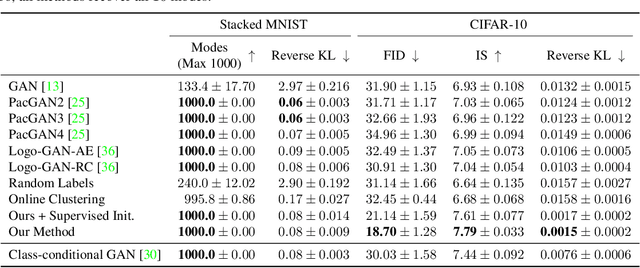
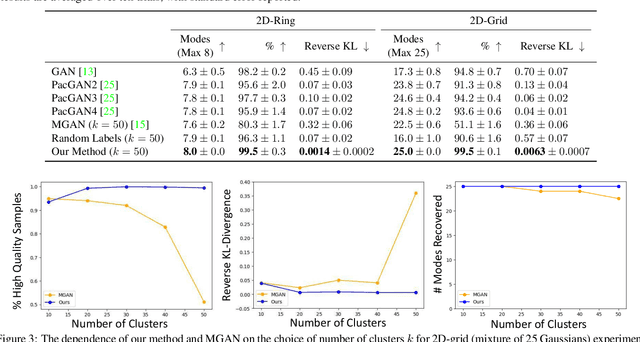
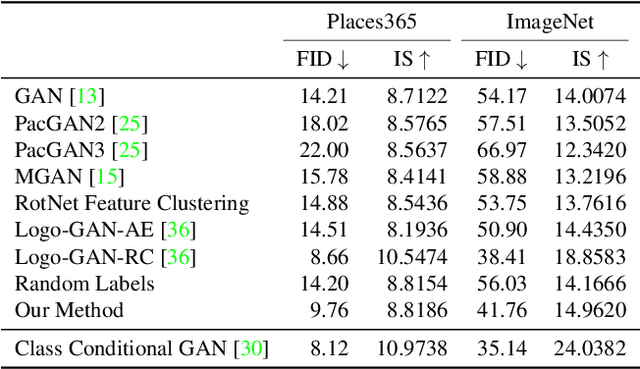
We introduce a simple but effective unsupervised method for generating realistic and diverse images. We train a class-conditional GAN model without using manually annotated class labels. Instead, our model is conditional on labels automatically derived from clustering in the discriminator's feature space. Our clustering step automatically discovers diverse modes, and explicitly requires the generator to cover them. Experiments on standard mode collapse benchmarks show that our method outperforms several competing methods when addressing mode collapse. Our method also performs well on large-scale datasets such as ImageNet and Places365, improving both image diversity and standard quality metrics, compared to previous methods.