 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHist2Style: Histogram-Guided Stylization with Bilateral Grids
Jun 01, 2026Photorealistic style transfer aims to match the color and tone of an input image to that of a style target while preserving the content and details of the original scene. Although existing large image models can facilitate these kinds of appearance edits, their high computational demands, potential for hallucinations, and limited user control make them unsuitable for high-resolution, real-time workflows. We introduce Hist2Style, a bilateral-grid formulation for fast, edge-aware stylization that preserves visual fidelity by constraining operations to locally affine transforms in bilateral space. Our model distills a large image editing model into a lightweight network by training on a large supervised corpus generated with language and vision-language models, targeting spatially varying color edits. The network conditions on a histogram-based embedding of the style target to provide an interpretable interface for adjusting the output style by modifying the target color distribution. Overall, Hist2Style maintains content structure by construction, avoids hallucinations, and supports real-time, high-resolution photorealistic stylization with interactive user-controllable color and tone adjustments.
Linear Image Generation by Synthesizing Exposure Brackets
Apr 22, 2026The life of a photo begins with photons striking the sensor, whose signals are passed through a sophisticated image signal processing (ISP) pipeline to produce a display-referred image. However, such images are no longer faithful to the incident light, being compressed in dynamic range and stylized by subjective preferences. In contrast, RAW images record direct sensor signals before non-linear tone mapping. After camera response curve correction and demosaicing, they can be converted into linear images, which are scene-referred representations that directly reflect true irradiance and are invariant to sensor-specific factors. Since image sensors have better dynamic range and bit depth, linear images contain richer information than display-referred ones, leaving users more room for editing during post-processing. Despite this advantage, current generative models mainly synthesize display-referred images, which inherently limits downstream editing. In this paper, we address the task of text-to-linear-image generation: synthesizing a high-quality, scene-referred linear image that preserves full dynamic range, conditioned on a text prompt, for professional post-processing. Generating linear images is challenging, as pre-trained VAEs in latent diffusion models struggle to simultaneously preserve extreme highlights and shadows due to the higher dynamic range and bit depth. To this end, we represent a linear image as a sequence of exposure brackets, each capturing a specific portion of the dynamic range, and propose a DiT-based flow-matching architecture for text-conditioned exposure bracket generation. We further demonstrate downstream applications including text-guided linear image editing and structure-conditioned generation via ControlNet.
Lucky High Dynamic Range Smartphone Imaging
Apr 21, 2026While the human eye can perceive an impressive twenty stops of dynamic range, smartphone camera sensors remain limited to about twelve stops despite decades of research. A variety of high dynamic range (HDR) image capture and processing techniques have been proposed, and, in practice, they can extend the dynamic range by 3-5 stops for handheld photography. This paper proposes an approach that robustly captures dynamic range using a handheld smartphone camera and lightweight networks suitable for running on mobile devices. Our method operates indirectly on linear raw pixels in bracketed exposures. Every pixel in the final HDR image is a convex combination of input pixels in the neighborhood, adjusted for exposure, and thus avoids hallucination artifacts typical of recent deep image synthesis networks. We validate our system on both synthetic imagery and unseen real bracketed images -- we confirm zero-shot generalization of the method to smartphone camera captures. Our iterative inference architecture is capable of processing an arbitrary number of bracketed input photos, and we show examples from capture stacks containing 3--9 images. Our training process relies only on synthetic captures yet generalizes to unseen real photos from several cameras. Moreover, we show that this training scheme improves other SOTA methods over their pretrained counterparts.
DA-VAE: Plug-in Latent Compression for Diffusion via Detail Alignment
Mar 23, 2026Reducing token count is crucial for efficient training and inference of latent diffusion models, especially at high resolution. A common strategy is to build high-compression image tokenizers with more channels per token. However, when trained only for reconstruction, high-dimensional latent spaces often lose meaningful structure, making diffusion training harder. Existing methods address this with extra objectives such as semantic alignment or selective dropout, but usually require costly diffusion retraining. Pretrained diffusion models, however, already exhibit a structured, lower-dimensional latent space; thus, a simpler idea is to expand the latent dimensionality while preserving this structure. We therefore propose \textbf{D}etail-\textbf{A}ligned VAE, which increases the compression ratio of a pretrained VAE with only lightweight adaptation of the pretrained diffusion backbone. DA-VAE uses an explicit latent layout: the first $C$ channels come directly from the pretrained VAE at a base resolution, while an additional $D$ channels encode higher-resolution details. A simple detail-alignment mechanism encourages the expanded latent space to retain the structure of the original one. With a warm-start fine-tuning strategy, our method enables $1024 \times 1024$ image generation with Stable Diffusion 3.5 using only $32 \times 32$ tokens, $4\times$ fewer than the original model, within 5 H100-days. It further unlocks $2048 \times 2048$ generation with SD3.5, achieving a $6\times$ speedup while preserving image quality. We also validate the method and its design choices quantitatively on ImageNet.
Learning to Refocus with Video Diffusion Models
Dec 24, 2025



Focus is a cornerstone of photography, yet autofocus systems often fail to capture the intended subject, and users frequently wish to adjust focus after capture. We introduce a novel method for realistic post-capture refocusing using video diffusion models. From a single defocused image, our approach generates a perceptually accurate focal stack, represented as a video sequence, enabling interactive refocusing and unlocking a range of downstream applications. We release a large-scale focal stack dataset acquired under diverse real-world smartphone conditions to support this work and future research. Our method consistently outperforms existing approaches in both perceptual quality and robustness across challenging scenarios, paving the way for more advanced focus-editing capabilities in everyday photography. Code and data are available at https://learn2refocus.github.io
Classic Video Denoising in a Machine Learning World: Robust, Fast, and Controllable
Apr 04, 2025Denoising is a crucial step in many video processing pipelines such as in interactive editing, where high quality, speed, and user control are essential. While recent approaches achieve significant improvements in denoising quality by leveraging deep learning, they are prone to unexpected failures due to discrepancies between training data distributions and the wide variety of noise patterns found in real-world videos. These methods also tend to be slow and lack user control. In contrast, traditional denoising methods perform reliably on in-the-wild videos and run relatively quickly on modern hardware. However, they require manually tuning parameters for each input video, which is not only tedious but also requires skill. We bridge the gap between these two paradigms by proposing a differentiable denoising pipeline based on traditional methods. A neural network is then trained to predict the optimal denoising parameters for each specific input, resulting in a robust and efficient approach that also supports user control.
FeatUp: A Model-Agnostic Framework for Features at Any Resolution
Mar 15, 2024
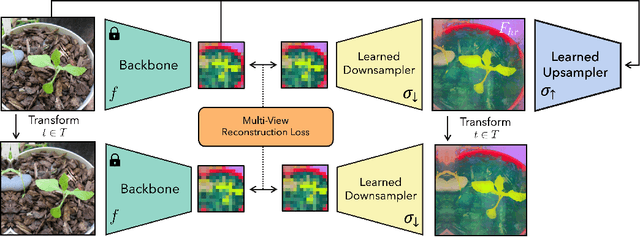


Deep features are a cornerstone of computer vision research, capturing image semantics and enabling the community to solve downstream tasks even in the zero- or few-shot regime. However, these features often lack the spatial resolution to directly perform dense prediction tasks like segmentation and depth prediction because models aggressively pool information over large areas. In this work, we introduce FeatUp, a task- and model-agnostic framework to restore lost spatial information in deep features. We introduce two variants of FeatUp: one that guides features with high-resolution signal in a single forward pass, and one that fits an implicit model to a single image to reconstruct features at any resolution. Both approaches use a multi-view consistency loss with deep analogies to NeRFs. Our features retain their original semantics and can be swapped into existing applications to yield resolution and performance gains even without re-training. We show that FeatUp significantly outperforms other feature upsampling and image super-resolution approaches in class activation map generation, transfer learning for segmentation and depth prediction, and end-to-end training for semantic segmentation.
DriveTrack: A Benchmark for Long-Range Point Tracking in Real-World Videos
Dec 15, 2023
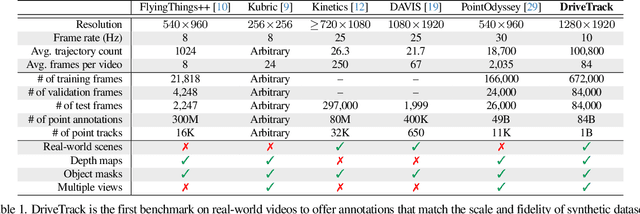

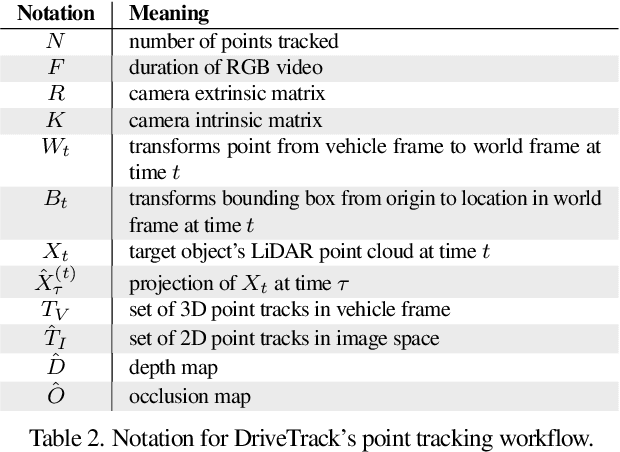
This paper presents DriveTrack, a new benchmark and data generation framework for long-range keypoint tracking in real-world videos. DriveTrack is motivated by the observation that the accuracy of state-of-the-art trackers depends strongly on visual attributes around the selected keypoints, such as texture and lighting. The problem is that these artifacts are especially pronounced in real-world videos, but these trackers are unable to train on such scenes due to a dearth of annotations. DriveTrack bridges this gap by building a framework to automatically annotate point tracks on autonomous driving datasets. We release a dataset consisting of 1 billion point tracks across 24 hours of video, which is seven orders of magnitude greater than prior real-world benchmarks and on par with the scale of synthetic benchmarks. DriveTrack unlocks new use cases for point tracking in real-world videos. First, we show that fine-tuning keypoint trackers on DriveTrack improves accuracy on real-world scenes by up to 7%. Second, we analyze the sensitivity of trackers to visual artifacts in real scenes and motivate the idea of running assistive keypoint selectors alongside trackers.
Fast View Synthesis of Casual Videos
Dec 04, 2023Novel view synthesis from an in-the-wild video is difficult due to challenges like scene dynamics and lack of parallax. While existing methods have shown promising results with implicit neural radiance fields, they are slow to train and render. This paper revisits explicit video representations to synthesize high-quality novel views from a monocular video efficiently. We treat static and dynamic video content separately. Specifically, we build a global static scene model using an extended plane-based scene representation to synthesize temporally coherent novel video. Our plane-based scene representation is augmented with spherical harmonics and displacement maps to capture view-dependent effects and model non-planar complex surface geometry. We opt to represent the dynamic content as per-frame point clouds for efficiency. While such representations are inconsistency-prone, minor temporal inconsistencies are perceptually masked due to motion. We develop a method to quickly estimate such a hybrid video representation and render novel views in real time. Our experiments show that our method can render high-quality novel views from an in-the-wild video with comparable quality to state-of-the-art methods while being 100x faster in training and enabling real-time rendering.
Unsupervised Semantic Segmentation by Distilling Feature Correspondences
Mar 16, 2022
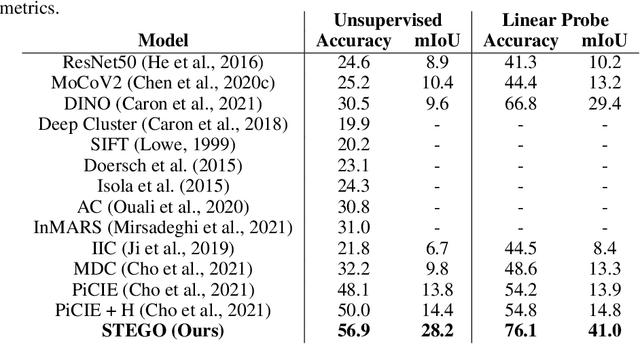

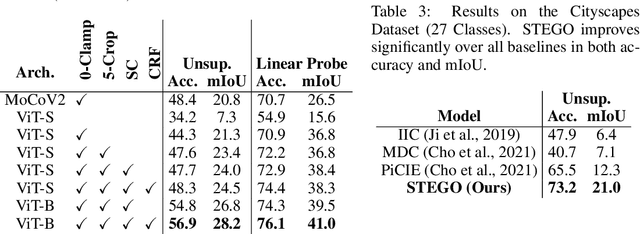
Unsupervised semantic segmentation aims to discover and localize semantically meaningful categories within image corpora without any form of annotation. To solve this task, algorithms must produce features for every pixel that are both semantically meaningful and compact enough to form distinct clusters. Unlike previous works which achieve this with a single end-to-end framework, we propose to separate feature learning from cluster compactification. Empirically, we show that current unsupervised feature learning frameworks already generate dense features whose correlations are semantically consistent. This observation motivates us to design STEGO ($\textbf{S}$elf-supervised $\textbf{T}$ransformer with $\textbf{E}$nergy-based $\textbf{G}$raph $\textbf{O}$ptimization), a novel framework that distills unsupervised features into high-quality discrete semantic labels. At the core of STEGO is a novel contrastive loss function that encourages features to form compact clusters while preserving their relationships across the corpora. STEGO yields a significant improvement over the prior state of the art, on both the CocoStuff ($\textbf{+14 mIoU}$) and Cityscapes ($\textbf{+9 mIoU}$) semantic segmentation challenges.