 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bias-Free Training Paradigm for More General AI-generated Image Detection
Dec 23, 2024Successful forensic detectors can produce excellent results in supervised learning benchmarks but struggle to transfer to real-world applications. We believe this limitation is largely due to inadequate training data quality. While most research focuses on developing new algorithms, less attention is given to training data selection, despite evidence that performance can be strongly impacted by spurious correlations such as content, format, or resolution. A well-designed forensic detector should detect generator specific artifacts rather than reflect data biases. To this end, we propose B-Free, a bias-free training paradigm, where fake images are generated from real ones using the conditioning procedure of stable diffusion models. This ensures semantic alignment between real and fake images, allowing any differences to stem solely from the subtle artifacts introduced by AI generation. Through content-based augmentation, we show significant improvements in both generalization and robustness over state-of-the-art detectors and more calibrated results across 27 different generative models, including recent releases, like FLUX and Stable Diffusion 3.5. Our findings emphasize the importance of a careful dataset curation, highlighting the need for further research in dataset design. Code and data will be publicly available at https://grip-unina.github.io/B-Free/
FakeInversion: Learning to Detect Images from Unseen Text-to-Image Models by Inverting Stable Diffusion
Jun 12, 2024Due to the high potential for abuse of GenAI systems, the task of detecting synthetic images has recently become of great interest to the research community. Unfortunately, existing image-space detectors quickly become obsolete as new high-fidelity text-to-image models are developed at blinding speed. In this work, we propose a new synthetic image detector that uses features obtained by inverting an open-source pre-trained Stable Diffusion model. We show that these inversion features enable our detector to generalize well to unseen generators of high visual fidelity (e.g., DALL-E 3) even when the detector is trained only on lower fidelity fake images generated via Stable Diffusion. This detector achieves new state-of-the-art across multiple training and evaluation setups. Moreover, we introduce a new challenging evaluation protocol that uses reverse image search to mitigate stylistic and thematic biases in the detector evaluation. We show that the resulting evaluation scores align well with detectors' in-the-wild performance, and release these datasets as public benchmarks for future research.
* Project page: https://fake-inversion.github.io
TruFor: Leveraging all-round clues for trustworthy image forgery detection and localization
Dec 21, 2022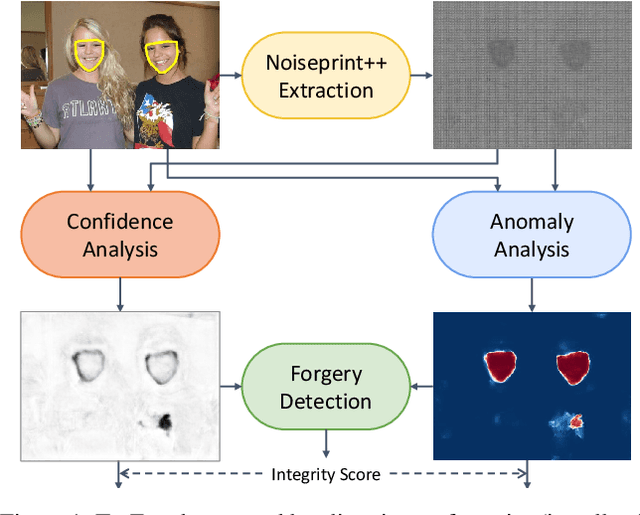
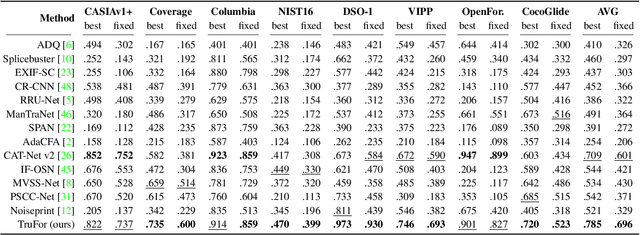

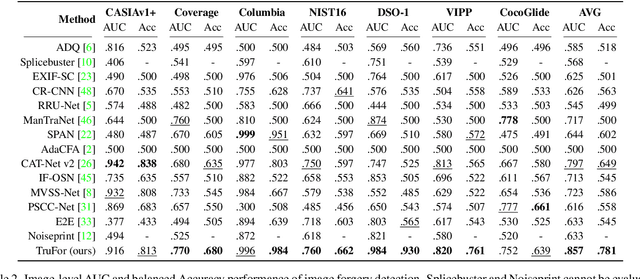
In this paper we present TruFor, a forensic framework that can be applied to a large variety of image manipulation methods, from classic cheapfakes to more recent manipulations based on deep learning. We rely on the extraction of both high-level and low-level traces through a transformer-based fusion architecture that combines the RGB image and a learned noise-sensitive fingerprint. The latter learns to embed the artifacts related to the camera internal and external processing by training only on real data in a self-supervised manner. Forgeries are detected as deviations from the expected regular pattern that characterizes each pristine image. Looking for anomalies makes the approach able to robustly detect a variety of local manipulations, ensuring generalization. In addition to a pixel-level localization map and a whole-image integrity score, our approach outputs a reliability map that highlights areas where localization predictions may be error-prone. This is particularly important in forensic applications in order to reduce false alarms and allow for a large scale analysis. Extensive experiments on several datasets show that our method is able to reliably detect and localize both cheapfakes and deepfakes manipulations outperforming state-of-the-art works. Code will be publicly available at https://grip-unina.github.io/TruFor/
NewsStories: Illustrating articles with visual summaries
Aug 14, 2022
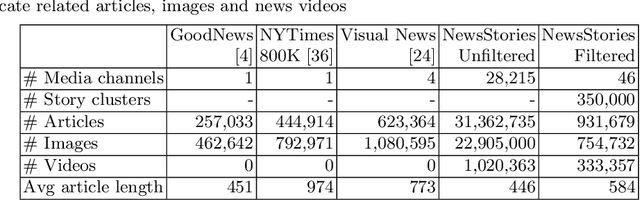
Recent self-supervised approaches have used large-scale image-text datasets to learn powerful representations that transfer to many tasks without finetuning. These methods often assume that there is one-to-one correspondence between its images and their (short) captions. However, many tasks require reasoning about multiple images and long text narratives, such as describing news articles with visual summaries. Thus, we explore a novel setting where the goal is to learn a self-supervised visual-language representation that is robust to varying text length and the number of images. In addition, unlike prior work which assumed captions have a literal relation to the image, we assume images only contain loose illustrative correspondence with the text. To explore this problem, we introduce a large-scale multimodal dataset containing over 31M articles, 22M images and 1M videos. We show that state-of-the-art image-text alignment methods are not robust to longer narratives with multiple images. Finally, we introduce an intuitive baseline that outperforms these methods on zero-shot image-set retrieval by 10% on the GoodNews dataset.
Learning 3D Semantic Segmentation with only 2D Image Supervision
Oct 21, 2021
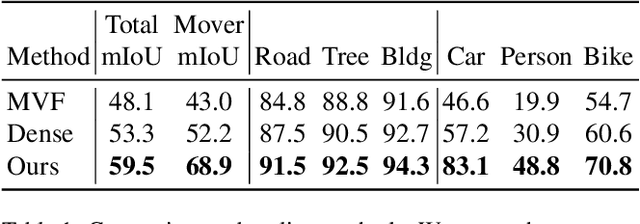
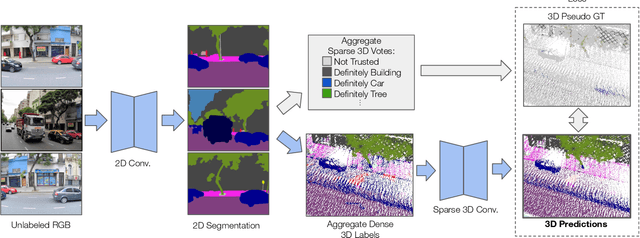
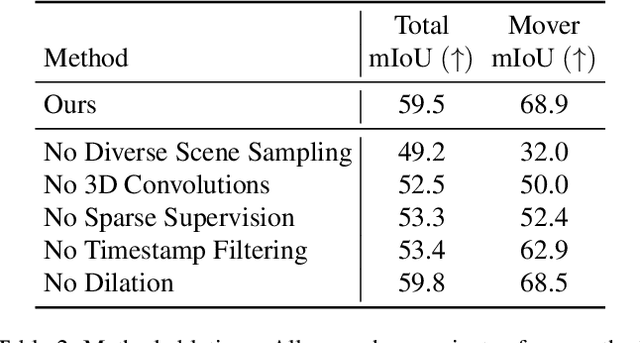
With the recent growth of urban mapping and autonomous driving efforts, there has been an explosion of raw 3D data collected from terrestrial platforms with lidar scanners and color cameras. However, due to high labeling costs, ground-truth 3D semantic segmentation annotations are limited in both quantity and geographic diversity, while also being difficult to transfer across sensors. In contrast, large image collections with ground-truth semantic segmentations are readily available for diverse sets of scenes. In this paper, we investigate how to use only those labeled 2D image collections to supervise training 3D semantic segmentation models. Our approach is to train a 3D model from pseudo-labels derived from 2D semantic image segmentations using multiview fusion. We address several novel issues with this approach, including how to select trusted pseudo-labels, how to sample 3D scenes with rare object categories, and how to decouple input features from 2D images from pseudo-labels during training. The proposed network architecture, 2D3DNet, achieves significantly better performance (+6.2-11.4 mIoU) than baselines during experiments on a new urban dataset with lidar and images captured in 20 cities across 5 continents.
Differentiable Surface Rendering via Non-Differentiable Sampling
Aug 10, 2021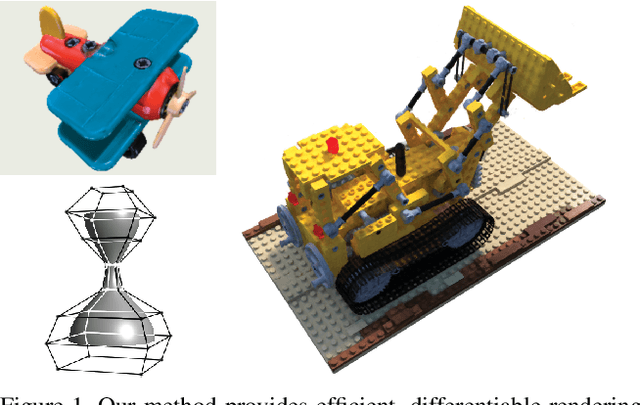

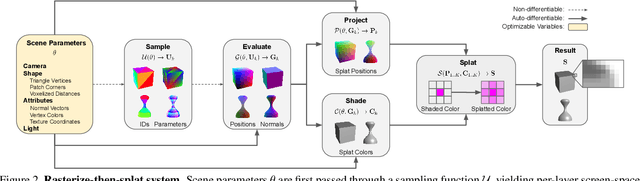
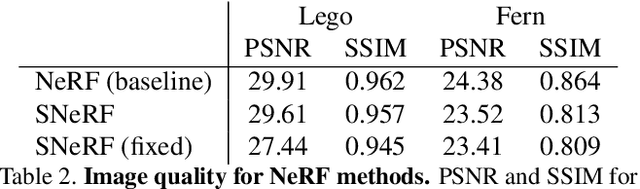
We present a method for differentiable rendering of 3D surfaces that supports both explicit and implicit representations, provides derivatives at occlusion boundaries, and is fast and simple to implement. The method first samples the surface using non-differentiable rasterization, then applies differentiable, depth-aware point splatting to produce the final image. Our approach requires no differentiable meshing or rasterization steps, making it efficient for large 3D models and applicable to isosurfaces extracted from implicit surface definitions. We demonstrate the effectiveness of our method for implicit-, mesh-, and parametric-surface-based inverse rendering and neural-network training applications. In particular, we show for the first time efficient, differentiable rendering of an isosurface extracted from a neural radiance field (NeRF), and demonstrate surface-based, rather than volume-based, rendering of a NeRF.
MetaPose: Fast 3D Pose from Multiple Views without 3D Supervision
Aug 10, 2021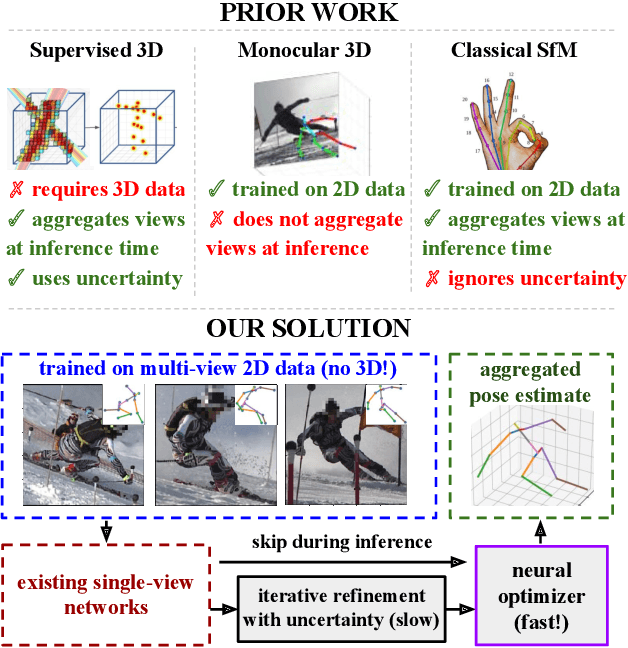
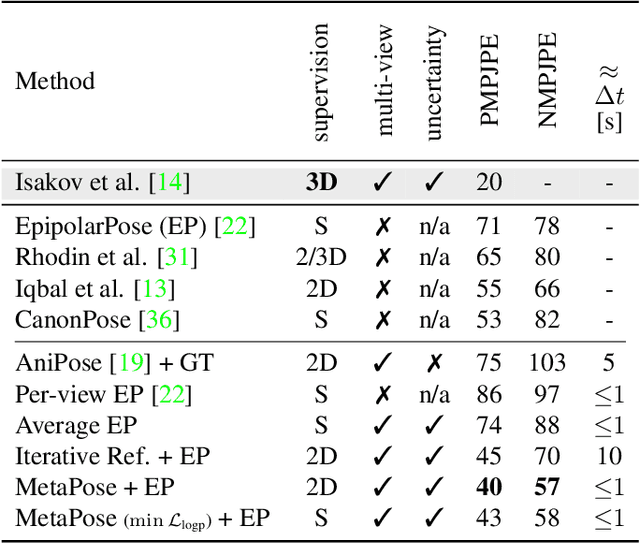
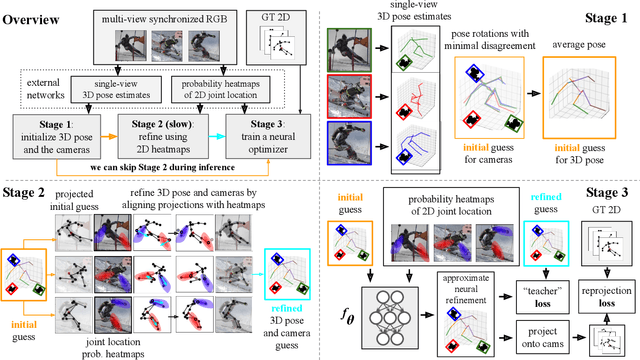

Recently, huge strides were made in monocular and multi-view pose estimation with known camera parameters, whereas pose estimation from multiple cameras with unknown positions and orientations received much less attention. In this paper, we show how to train a neural model that can perform accurate 3D pose and camera estimation, takes into account joint location uncertainty due occlusion from multiple views, and requires only 2D keypoint data for training. Our method outperforms both classical bundle adjustment and weakly-supervised monocular 3D baselines on the well-established Human3.6M dataset, as well as the more challenging in-the-wild Ski-Pose PTZ dataset with moving cameras. We provide an extensive ablation study separating the error due to the camera model, number of cameras, initialization, and image-space joint localization from the additional error introduced by our model.
Optical Mouse: 3D Mouse Pose From Single-View Video
Jun 17, 2021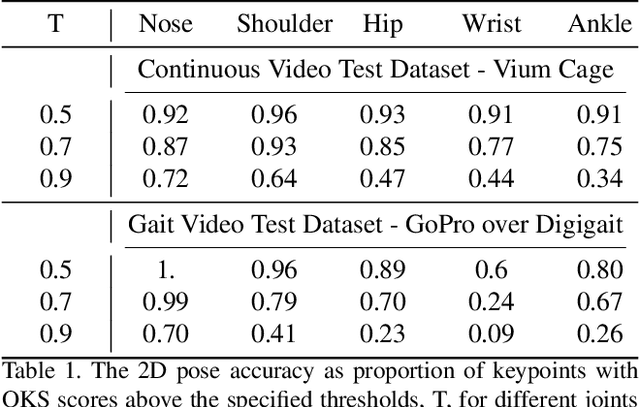

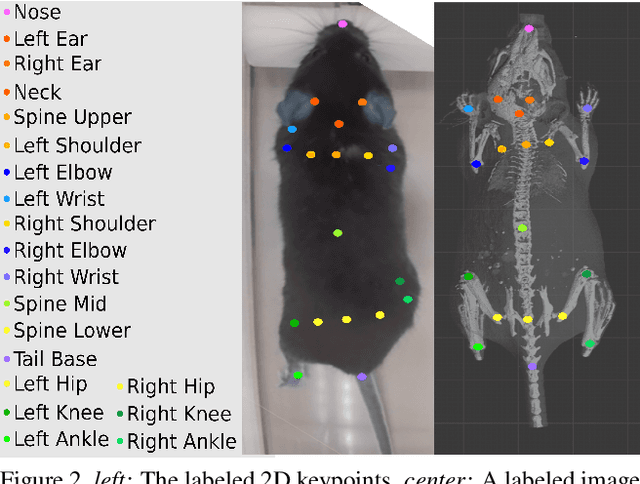
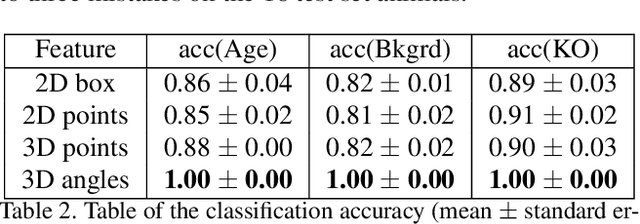
We present a method to infer the 3D pose of mice, including the limbs and feet, from monocular videos. Many human clinical conditions and their corresponding animal models result in abnormal motion, and accurately measuring 3D motion at scale offers insights into health. The 3D poses improve classification of health-related attributes over 2D representations. The inferred poses are accurate enough to estimate stride length even when the feet are mostly occluded. This method could be applied as part of a continuous monitoring system to non-invasively measure animal health.
Human 3D keypoints via spatial uncertainty modeling
Dec 18, 2020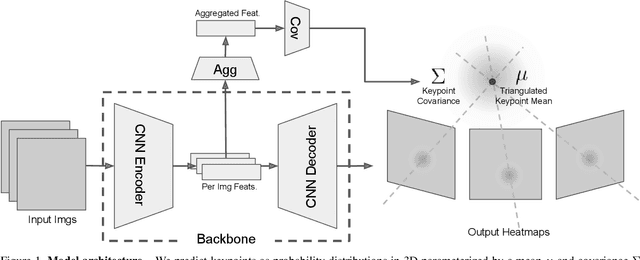


We introduce a technique for 3D human keypoint estimation that directly models the notion of spatial uncertainty of a keypoint. Our technique employs a principled approach to modelling spatial uncertainty inspired from techniques in robust statistics. Furthermore, our pipeline requires no 3D ground truth labels, relying instead on (possibly noisy) 2D image-level keypoints. Our method achieves near state-of-the-art performance on Human3.6m while being efficient to evaluate and straightforward to
Learning to Infer Semantic Parameters for 3D Shape Editing
Nov 09, 2020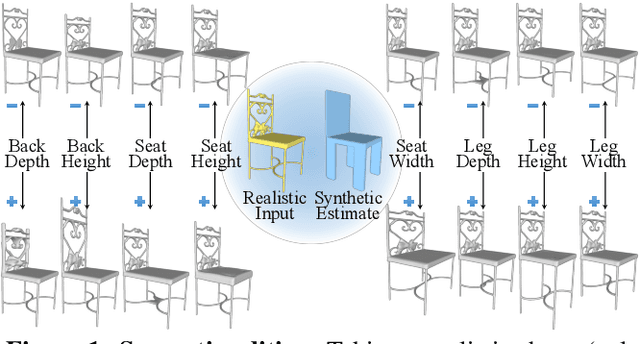

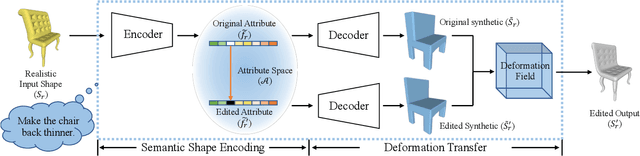
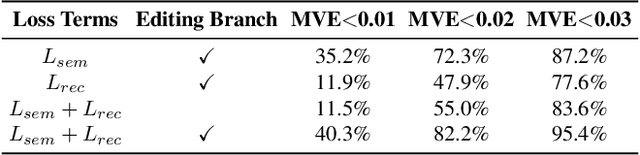
Many applications in 3D shape design and augmentation require the ability to make specific edits to an object's semantic parameters (e.g., the pose of a person's arm or the length of an airplane's wing) while preserving as much existing details as possible. We propose to learn a deep network that infers the semantic parameters of an input shape and then allows the user to manipulate those parameters. The network is trained jointly on shapes from an auxiliary synthetic template and unlabeled realistic models, ensuring robustness to shape variability while relieving the need to label realistic exemplars. At testing time, edits within the parameter space drive deformations to be applied to the original shape, which provides semantically-meaningful manipulation while preserving the details. This is in contrast to prior methods that either use autoencoders with a limited latent-space dimensionality, failing to preserve arbitrary detail, or drive deformations with purely-geometric controls, such as cages, losing the ability to update local part regions. Experiments with datasets of chairs, airplanes, and human bodies demonstrate that our method produces more natural edits than prior work.