 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniNOCS: A unified NOCS dataset and model for 3D lifting of 2D objects
Jul 11, 2024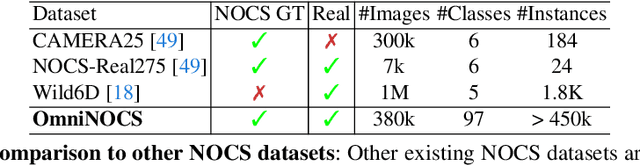


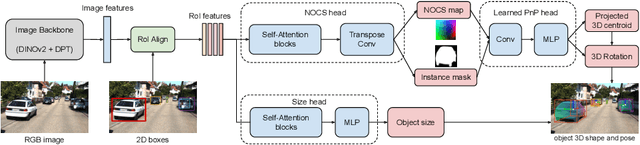
We propose OmniNOCS, a large-scale monocular dataset with 3D Normalized Object Coordinate Space (NOCS) maps, object masks, and 3D bounding box annotations for indoor and outdoor scenes. OmniNOCS has 20 times more object classes and 200 times more instances than existing NOCS datasets (NOCS-Real275, Wild6D). We use OmniNOCS to train a novel, transformer-based monocular NOCS prediction model (NOCSformer) that can predict accurate NOCS, instance masks and poses from 2D object detections across diverse classes. It is the first NOCS model that can generalize to a broad range of classes when prompted with 2D boxes. We evaluate our model on the task of 3D oriented bounding box prediction, where it achieves comparable results to state-of-the-art 3D detection methods such as Cube R-CNN. Unlike other 3D detection methods, our model also provides detailed and accurate 3D object shape and segmentation. We propose a novel benchmark for the task of NOCS prediction based on OmniNOCS, which we hope will serve as a useful baseline for future work in this area. Our dataset and code will be at the project website: https://omninocs.github.io.
Gaga: Group Any Gaussians via 3D-aware Memory Bank
Apr 11, 2024



We introduce Gaga, a framework that reconstructs and segments open-world 3D scenes by leveraging inconsistent 2D masks predicted by zero-shot segmentation models. Contrasted to prior 3D scene segmentation approaches that heavily rely on video object tracking, Gaga utilizes spatial information and effectively associates object masks across diverse camera poses. By eliminating the assumption of continuous view changes in training images, Gaga demonstrates robustness to variations in camera poses, particularly beneficial for sparsely sampled images, ensuring precise mask label consistency. Furthermore, Gaga accommodates 2D segmentation masks from diverse sources and demonstrates robust performance with different open-world zero-shot segmentation models, enhancing its versatility. Extensive qualitative and quantitative evaluations demonstrate that Gaga performs favorably against state-of-the-art methods, emphasizing its potential for real-world applications such as scene understanding and manipulation.
NIFTY: Neural Object Interaction Fields for Guided Human Motion Synthesis
Jul 14, 2023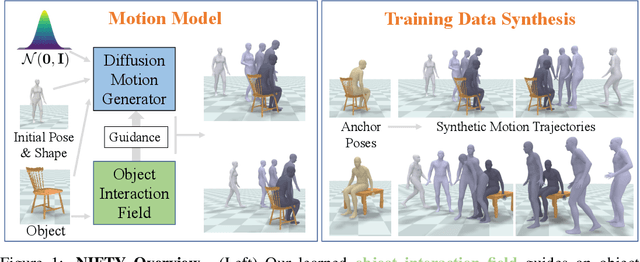

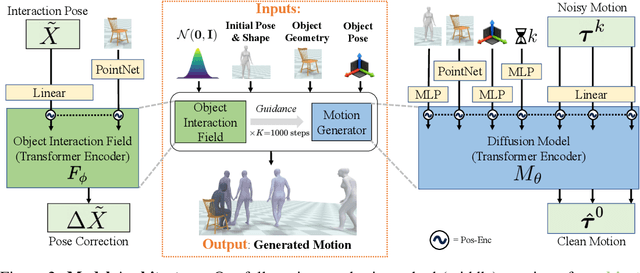
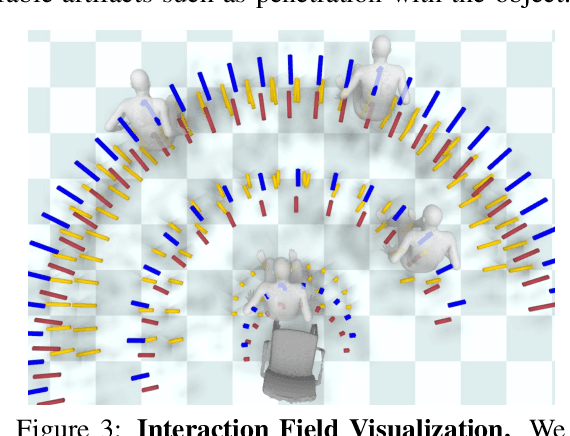
We address the problem of generating realistic 3D motions of humans interacting with objects in a scene. Our key idea is to create a neural interaction field attached to a specific object, which outputs the distance to the valid interaction manifold given a human pose as input. This interaction field guides the sampling of an object-conditioned human motion diffusion model, so as to encourage plausible contacts and affordance semantics. To support interactions with scarcely available data, we propose an automated synthetic data pipeline. For this, we seed a pre-trained motion model, which has priors for the basics of human movement, with interaction-specific anchor poses extracted from limited motion capture data. Using our guided diffusion model trained on generated synthetic data, we synthesize realistic motions for sitting and lifting with several objects, outperforming alternative approaches in terms of motion quality and successful action completion. We call our framework NIFTY: Neural Interaction Fields for Trajectory sYnthesis.
Learning a Diffusion Prior for NeRFs
Apr 27, 2023


Neural Radiance Fields (NeRFs) have emerged as a powerful neural 3D representation for objects and scenes derived from 2D data. Generating NeRFs, however, remains difficult in many scenarios. For instance, training a NeRF with only a small number of views as supervision remains challenging since it is an under-constrained problem. In such settings, it calls for some inductive prior to filter out bad local minima. One way to introduce such inductive priors is to learn a generative model for NeRFs modeling a certain class of scenes. In this paper, we propose to use a diffusion model to generate NeRFs encoded on a regularized grid. We show that our model can sample realistic NeRFs, while at the same time allowing conditional generations, given a certain observation as guidance.
NeRFMeshing: Distilling Neural Radiance Fields into Geometrically-Accurate 3D Meshes
Mar 16, 2023
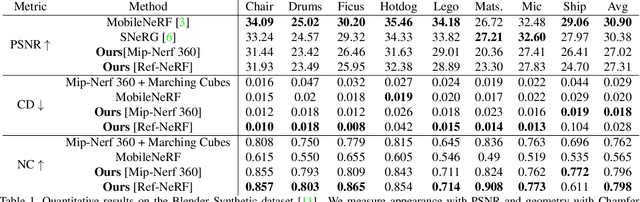


With the introduction of Neural Radiance Fields (NeRFs), novel view synthesis has recently made a big leap forward. At the core, NeRF proposes that each 3D point can emit radiance, allowing to conduct view synthesis using differentiable volumetric rendering. While neural radiance fields can accurately represent 3D scenes for computing the image rendering, 3D meshes are still the main scene representation supported by most computer graphics and simulation pipelines, enabling tasks such as real time rendering and physics-based simulations. Obtaining 3D meshes from neural radiance fields still remains an open challenge since NeRFs are optimized for view synthesis, not enforcing an accurate underlying geometry on the radiance field. We thus propose a novel compact and flexible architecture that enables easy 3D surface reconstruction from any NeRF-driven approach. Upon having trained the radiance field, we distill the volumetric 3D representation into a Signed Surface Approximation Network, allowing easy extraction of the 3D mesh and appearance. Our final 3D mesh is physically accurate and can be rendered in real time on an array of devices.
Nerflets: Local Radiance Fields for Efficient Structure-Aware 3D Scene Representation from 2D Supervision
Mar 10, 2023We address efficient and structure-aware 3D scene representation from images. Nerflets are our key contribution -- a set of local neural radiance fields that together represent a scene. Each nerflet maintains its own spatial position, orientation, and extent, within which it contributes to panoptic, density, and radiance reconstructions. By leveraging only photometric and inferred panoptic image supervision, we can directly and jointly optimize the parameters of a set of nerflets so as to form a decomposed representation of the scene, where each object instance is represented by a group of nerflets. During experiments with indoor and outdoor environments, we find that nerflets: (1) fit and approximate the scene more efficiently than traditional global NeRFs, (2) allow the extraction of panoptic and photometric renderings from arbitrary views, and (3) enable tasks rare for NeRFs, such as 3D panoptic segmentation and interactive editing.
im2nerf: Image to Neural Radiance Field in the Wild
Sep 08, 2022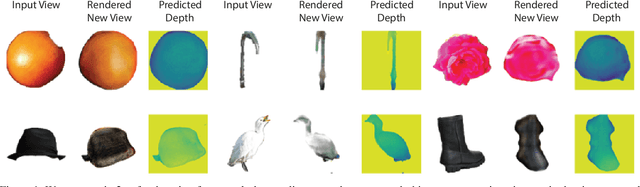
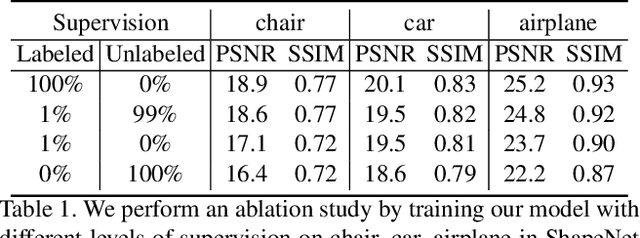
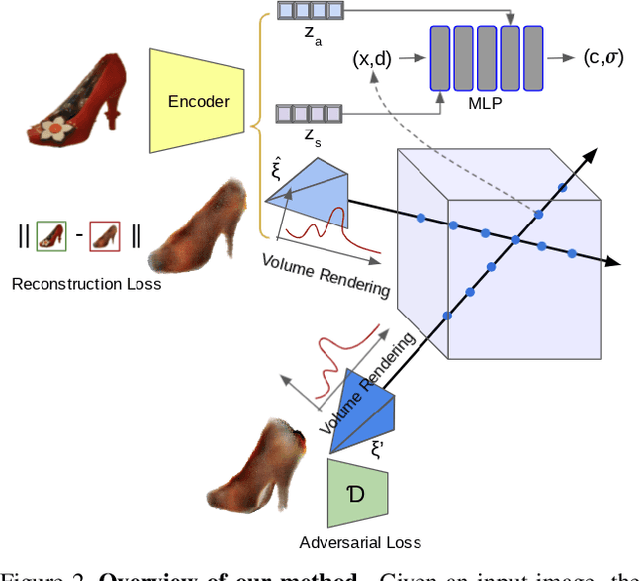
We propose im2nerf, a learning framework that predicts a continuous neural object representation given a single input image in the wild, supervised by only segmentation output from off-the-shelf recognition methods. The standard approach to constructing neural radiance fields takes advantage of multi-view consistency and requires many calibrated views of a scene, a requirement that cannot be satisfied when learning on large-scale image data in the wild. We take a step towards addressing this shortcoming by introducing a model that encodes the input image into a disentangled object representation that contains a code for object shape, a code for object appearance, and an estimated camera pose from which the object image is captured. Our model conditions a NeRF on the predicted object representation and uses volume rendering to generate images from novel views. We train the model end-to-end on a large collection of input images. As the model is only provided with single-view images, the problem is highly under-constrained. Therefore, in addition to using a reconstruction loss on the synthesized input view, we use an auxiliary adversarial loss on the novel rendered views. Furthermore, we leverage object symmetry and cycle camera pose consistency. We conduct extensive quantitative and qualitative experiments on the ShapeNet dataset as well as qualitative experiments on Open Images dataset. We show that in all cases, im2nerf achieves the state-of-the-art performance for novel view synthesis from a single-view unposed image in the wild.
Panoptic Neural Fields: A Semantic Object-Aware Neural Scene Representation
May 09, 2022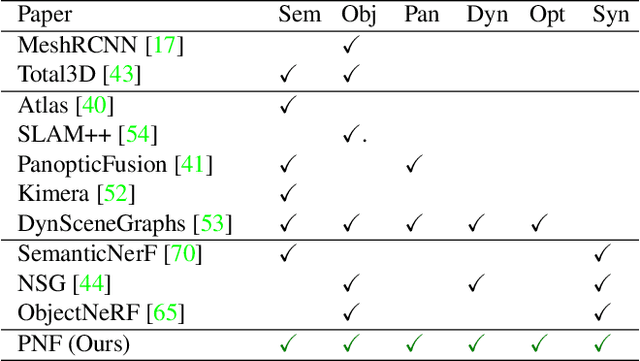
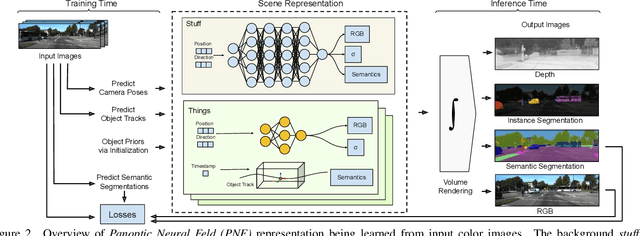
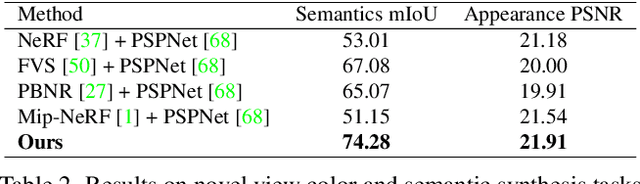
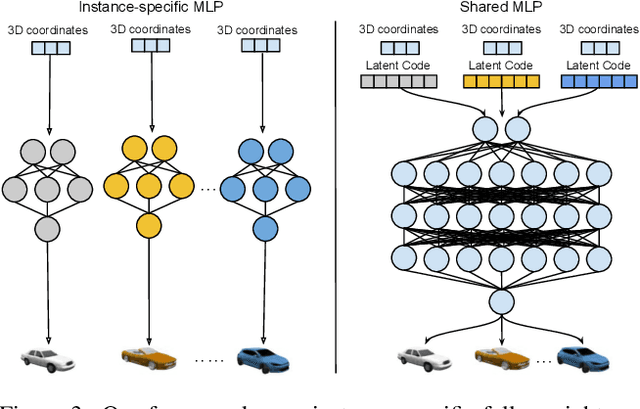
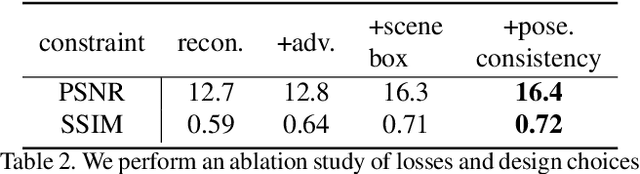
We present Panoptic Neural Fields (PNF), an object-aware neural scene representation that decomposes a scene into a set of objects (things) and background (stuff). Each object is represented by an oriented 3D bounding box and a multi-layer perceptron (MLP) that takes position, direction, and time and outputs density and radiance. The background stuff is represented by a similar MLP that additionally outputs semantic labels. Each object MLPs are instance-specific and thus can be smaller and faster than previous object-aware approaches, while still leveraging category-specific priors incorporated via meta-learned initialization. Our model builds a panoptic radiance field representation of any scene from just color images. We use off-the-shelf algorithms to predict camera poses, object tracks, and 2D image semantic segmentations. Then we jointly optimize the MLP weights and bounding box parameters using analysis-by-synthesis with self-supervision from color images and pseudo-supervision from predicted semantic segmentations. During experiments with real-world dynamic scenes, we find that our model can be used effectively for several tasks like novel view synthesis, 2D panoptic segmentation, 3D scene editing, and multiview depth prediction.
Kubric: A scalable dataset generator
Mar 07, 2022

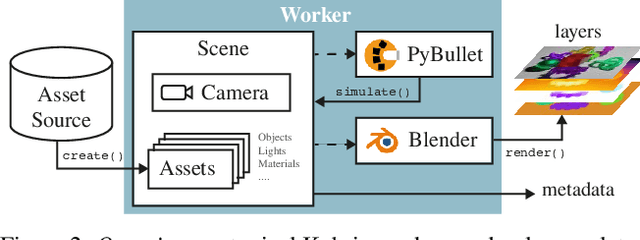
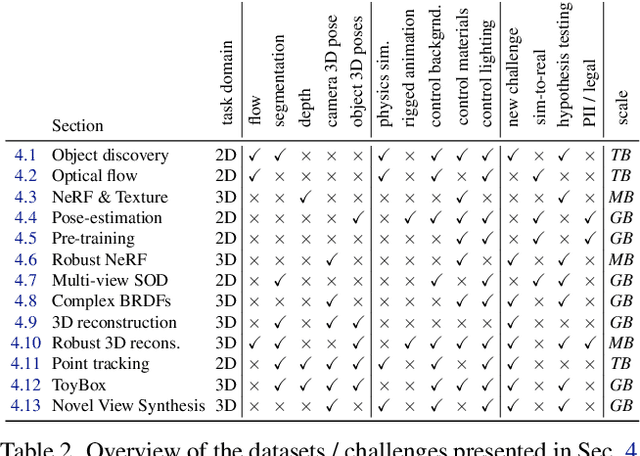
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
Learning 3D Semantic Segmentation with only 2D Image Supervision
Oct 21, 2021
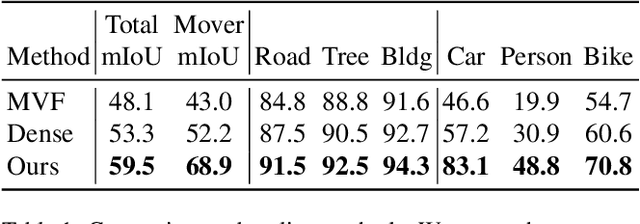
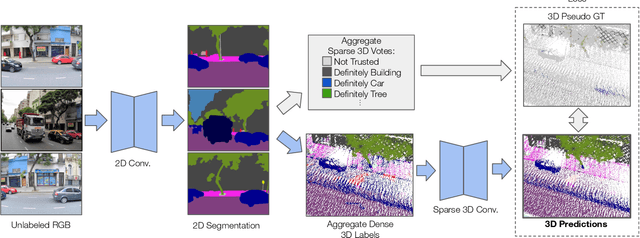
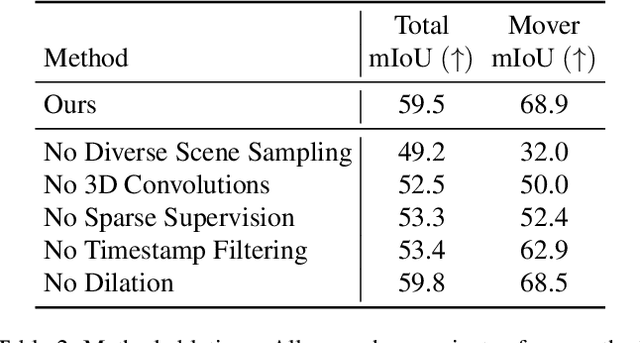
With the recent growth of urban mapping and autonomous driving efforts, there has been an explosion of raw 3D data collected from terrestrial platforms with lidar scanners and color cameras. However, due to high labeling costs, ground-truth 3D semantic segmentation annotations are limited in both quantity and geographic diversity, while also being difficult to transfer across sensors. In contrast, large image collections with ground-truth semantic segmentations are readily available for diverse sets of scenes. In this paper, we investigate how to use only those labeled 2D image collections to supervise training 3D semantic segmentation models. Our approach is to train a 3D model from pseudo-labels derived from 2D semantic image segmentations using multiview fusion. We address several novel issues with this approach, including how to select trusted pseudo-labels, how to sample 3D scenes with rare object categories, and how to decouple input features from 2D images from pseudo-labels during training. The proposed network architecture, 2D3DNet, achieves significantly better performance (+6.2-11.4 mIoU) than baselines during experiments on a new urban dataset with lidar and images captured in 20 cities across 5 continents.