 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIR-DIFF: Sparse Image Sets Restoration with Multi-View Diffusion Model
Mar 18, 2025The computer vision community has developed numerous techniques for digitally restoring true scene information from single-view degraded photographs, an important yet extremely ill-posed task. In this work, we tackle image restoration from a different perspective by jointly denoising multiple photographs of the same scene. Our core hypothesis is that degraded images capturing a shared scene contain complementary information that, when combined, better constrains the restoration problem. To this end, we implement a powerful multi-view diffusion model that jointly generates uncorrupted views by extracting rich information from multi-view relationships. Our experiments show that our multi-view approach outperforms existing single-view image and even video-based methods on image deblurring and super-resolution tasks. Critically, our model is trained to output 3D consistent images, making it a promising tool for applications requiring robust multi-view integration, such as 3D reconstruction or pose estimation.
3DFIRES: Few Image 3D REconstruction for Scenes with Hidden Surface
Mar 13, 2024This paper introduces 3DFIRES, a novel system for scene-level 3D reconstruction from posed images. Designed to work with as few as one view, 3DFIRES reconstructs the complete geometry of unseen scenes, including hidden surfaces. With multiple view inputs, our method produces full reconstruction within all camera frustums. A key feature of our approach is the fusion of multi-view information at the feature level, enabling the production of coherent and comprehensive 3D reconstruction. We train our system on non-watertight scans from large-scale real scene dataset. We show it matches the efficacy of single-view reconstruction methods with only one input and surpasses existing techniques in both quantitative and qualitative measures for sparse-view 3D reconstruction.
FAR: Flexible, Accurate and Robust 6DoF Relative Camera Pose Estimation
Mar 05, 2024Estimating relative camera poses between images has been a central problem in computer vision. Methods that find correspondences and solve for the fundamental matrix offer high precision in most cases. Conversely, methods predicting pose directly using neural networks are more robust to limited overlap and can infer absolute translation scale, but at the expense of reduced precision. We show how to combine the best of both methods; our approach yields results that are both precise and robust, while also accurately inferring translation scales. At the heart of our model lies a Transformer that (1) learns to balance between solved and learned pose estimations, and (2) provides a prior to guide a solver. A comprehensive analysis supports our design choices and demonstrates that our method adapts flexibly to various feature extractors and correspondence estimators, showing state-of-the-art performance in 6DoF pose estimation on Matterport3D, InteriorNet, StreetLearn, and Map-free Relocalization.
NIFTY: Neural Object Interaction Fields for Guided Human Motion Synthesis
Jul 14, 2023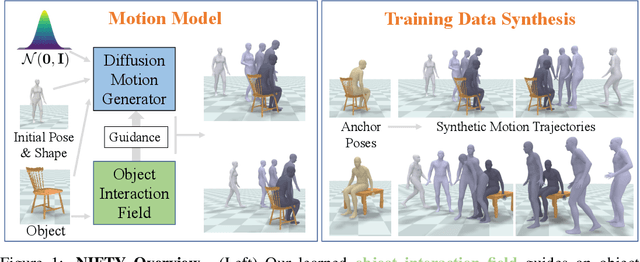

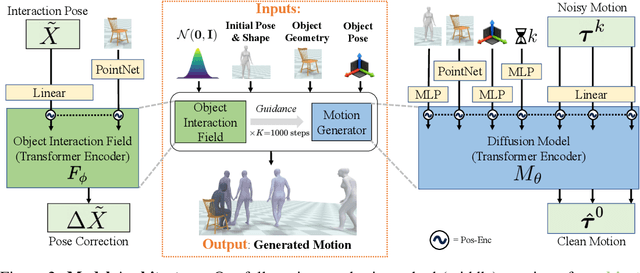
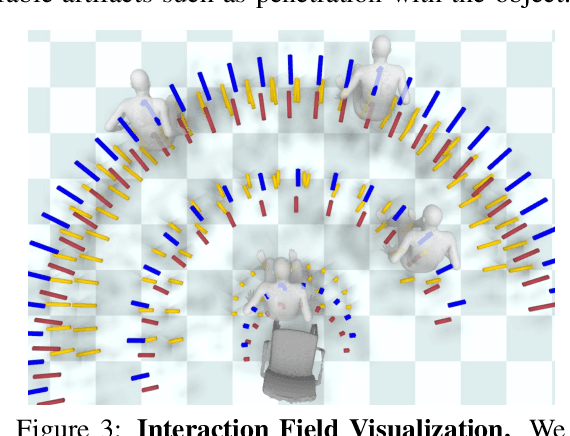
We address the problem of generating realistic 3D motions of humans interacting with objects in a scene. Our key idea is to create a neural interaction field attached to a specific object, which outputs the distance to the valid interaction manifold given a human pose as input. This interaction field guides the sampling of an object-conditioned human motion diffusion model, so as to encourage plausible contacts and affordance semantics. To support interactions with scarcely available data, we propose an automated synthetic data pipeline. For this, we seed a pre-trained motion model, which has priors for the basics of human movement, with interaction-specific anchor poses extracted from limited motion capture data. Using our guided diffusion model trained on generated synthetic data, we synthesize realistic motions for sitting and lifting with several objects, outperforming alternative approaches in terms of motion quality and successful action completion. We call our framework NIFTY: Neural Interaction Fields for Trajectory sYnthesis.
Learning to Predict Scene-Level Implicit 3D from Posed RGBD Data
Jun 14, 2023



We introduce a method that can learn to predict scene-level implicit functions for 3D reconstruction from posed RGBD data. At test time, our system maps a previously unseen RGB image to a 3D reconstruction of a scene via implicit functions. While implicit functions for 3D reconstruction have often been tied to meshes, we show that we can train one using only a set of posed RGBD images. This setting may help 3D reconstruction unlock the sea of accelerometer+RGBD data that is coming with new phones. Our system, D2-DRDF, can match and sometimes outperform current methods that use mesh supervision and shows better robustness to sparse data.
What's Behind the Couch? Directed Ray Distance Functions for 3D Scene Reconstruction
Dec 08, 2021
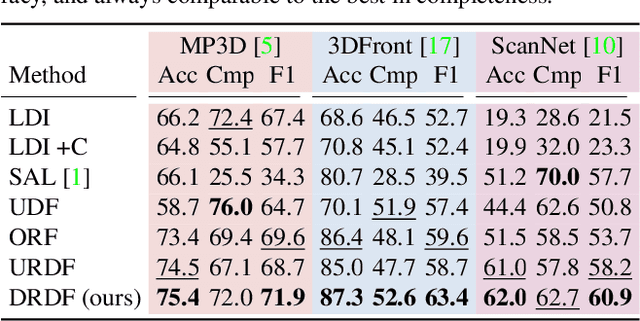
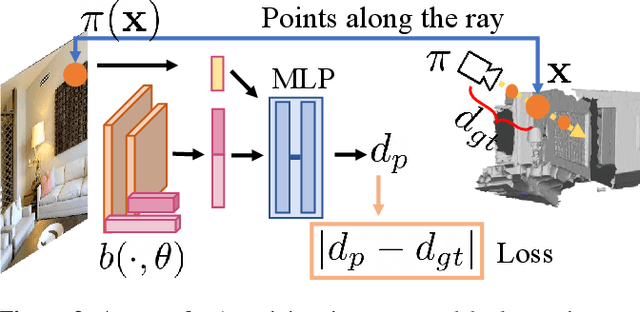
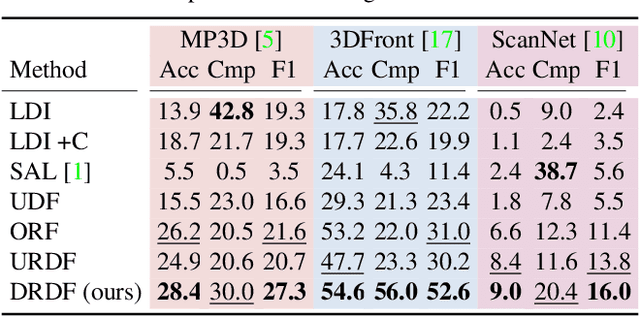
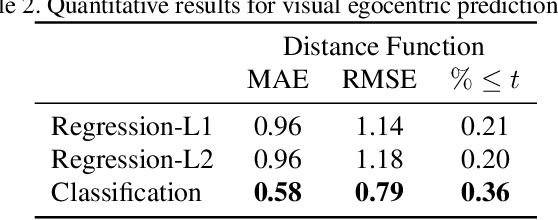
We present an approach for scene-level 3D reconstruction, including occluded regions, from an unseen RGB image. Our approach is trained on real 3D scans and images. This problem has proved difficult for multiple reasons; Real scans are not watertight, precluding many methods; distances in scenes require reasoning across objects (making it even harder); and, as we show, uncertainty about surface locations motivates networks to produce outputs that lack basic distance function properties. We propose a new distance-like function that can be computed on unstructured scans and has good behavior under uncertainty about surface location. Computing this function over rays reduces the complexity further. We train a deep network to predict this function and show it outperforms other methods on Matterport3D, 3D Front, and ScanNet.
Collision Replay: What Does Bumping Into Things Tell You About Scene Geometry?
May 03, 2021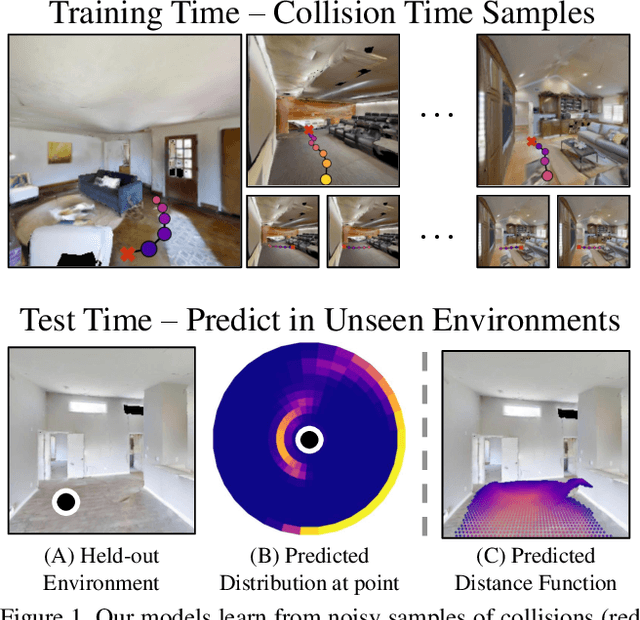
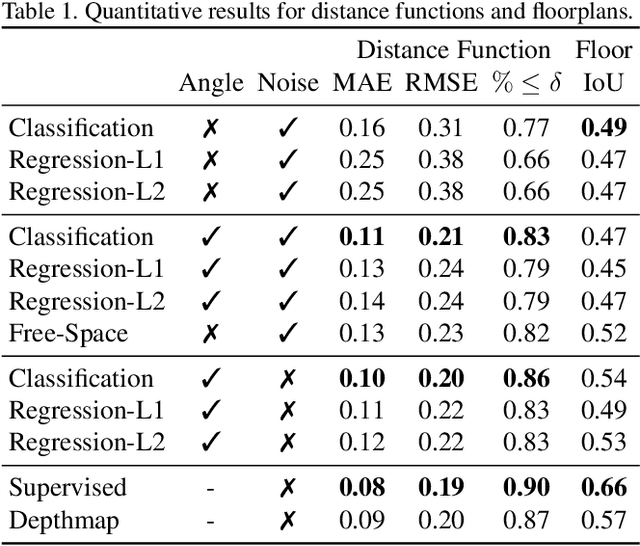
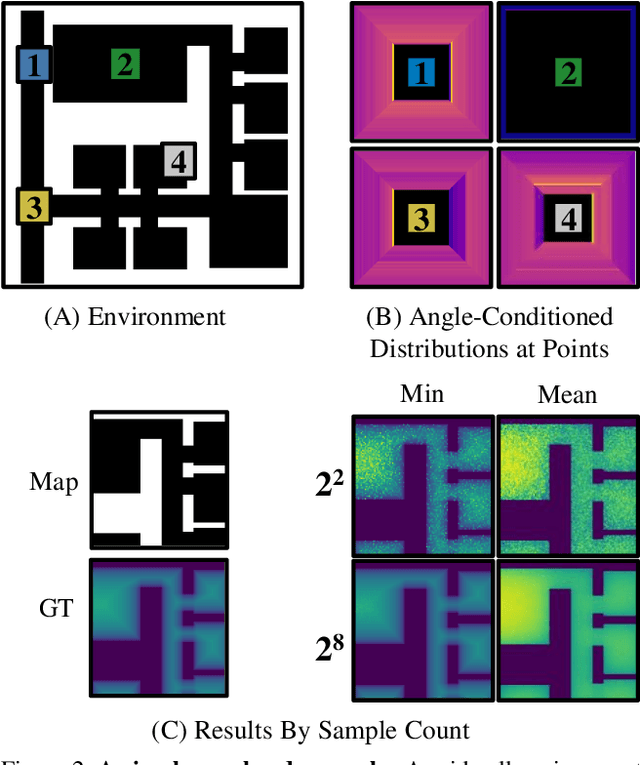
What does bumping into things in a scene tell you about scene geometry? In this paper, we investigate the idea of learning from collisions. At the heart of our approach is the idea of collision replay, where we use examples of a collision to provide supervision for observations at a past frame. We use collision replay to train convolutional neural networks to predict a distribution over collision time from new images. This distribution conveys information about the navigational affordances (e.g., corridors vs open spaces) and, as we show, can be converted into the distance function for the scene geometry. We analyze this approach with an agent that has noisy actuation in a photorealistic simulator.
Implicit Mesh Reconstruction from Unannotated Image Collections
Jul 16, 2020
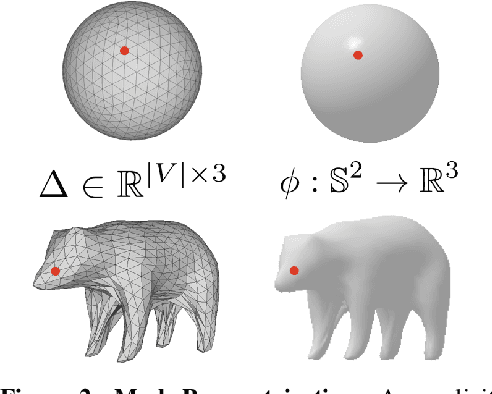

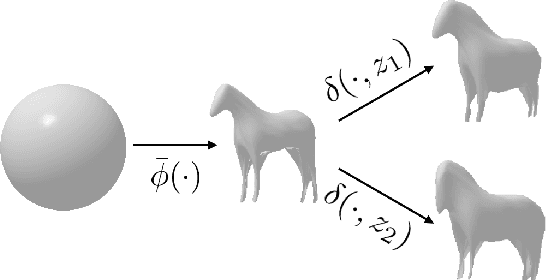
We present an approach to infer the 3D shape, texture, and camera pose for an object from a single RGB image, using only category-level image collections with foreground masks as supervision. We represent the shape as an image-conditioned implicit function that transforms the surface of a sphere to that of the predicted mesh, while additionally predicting the corresponding texture. To derive supervisory signal for learning, we enforce that: a) our predictions when rendered should explain the available image evidence, and b) the inferred 3D structure should be geometrically consistent with learned pixel to surface mappings. We empirically show that our approach improves over prior work that leverages similar supervision, and in fact performs competitively to methods that use stronger supervision. Finally, as our method enables learning with limited supervision, we qualitatively demonstrate its applicability over a set of about 30 object categories.
Articulation-aware Canonical Surface Mapping
Apr 02, 2020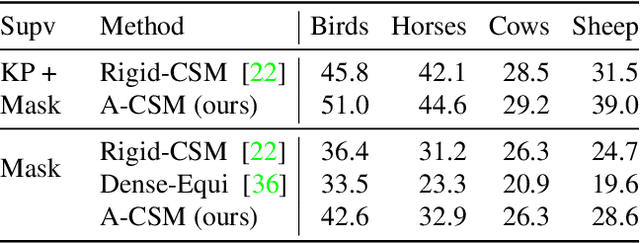
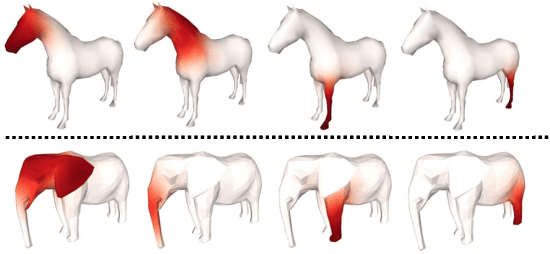
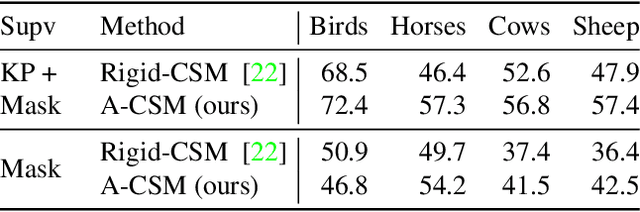
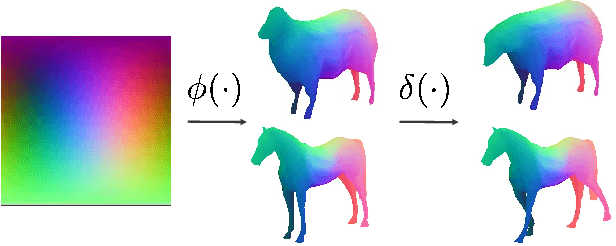
We tackle the tasks of: 1) predicting a Canonical Surface Mapping (CSM) that indicates the mapping from 2D pixels to corresponding points on a canonical template shape, and 2) inferring the articulation and pose of the template corresponding to the input image. While previous approaches rely on keypoint supervision for learning, we present an approach that can learn without such annotations. Our key insight is that these tasks are geometrically related, and we can obtain supervisory signal via enforcing consistency among the predictions. We present results across a diverse set of animal object categories, showing that our method can learn articulation and CSM prediction from image collections using only foreground mask labels for training. We empirically show that allowing articulation helps learn more accurate CSM prediction, and that enforcing the consistency with predicted CSM is similarly critical for learning meaningful articulation.
Canonical Surface Mapping via Geometric Cycle Consistency
Aug 15, 2019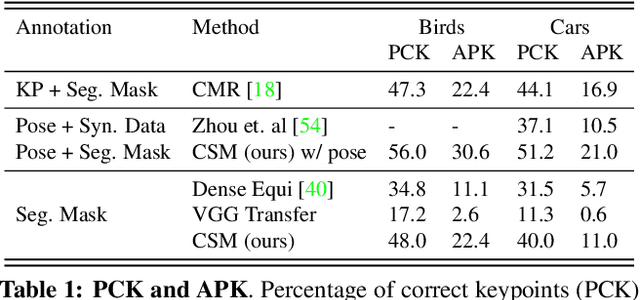
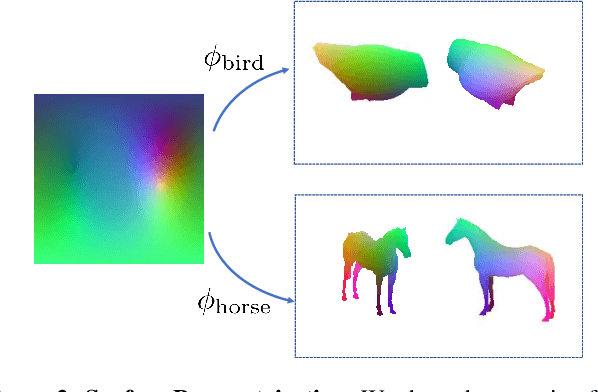
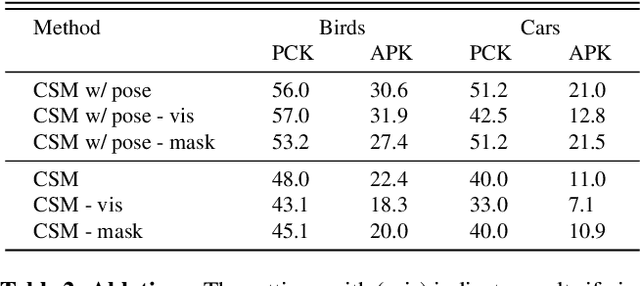
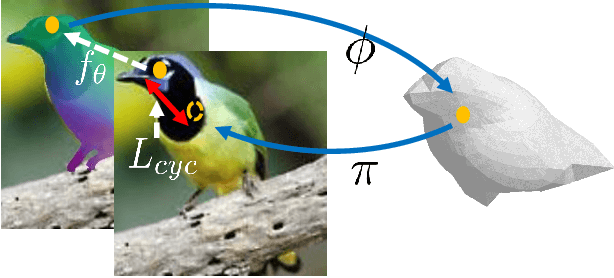
We explore the task of Canonical Surface Mapping (CSM). Specifically, given an image, we learn to map pixels on the object to their corresponding locations on an abstract 3D model of the category. But how do we learn such a mapping? A supervised approach would require extensive manual labeling which is not scalable beyond a few hand-picked categories. Our key insight is that the CSM task (pixel to 3D), when combined with 3D projection (3D to pixel), completes a cycle. Hence, we can exploit a geometric cycle consistency loss, thereby allowing us to forgo the dense manual supervision. Our approach allows us to train a CSM model for a diverse set of classes, without sparse or dense keypoint annotation, by leveraging only foreground mask labels for training. We show that our predictions also allow us to infer dense correspondence between two images, and compare the performance of our approach against several methods that predict correspondence by leveraging varying amount of supervision.