 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulation-aware Canonical Surface Mapping
Paper and Code
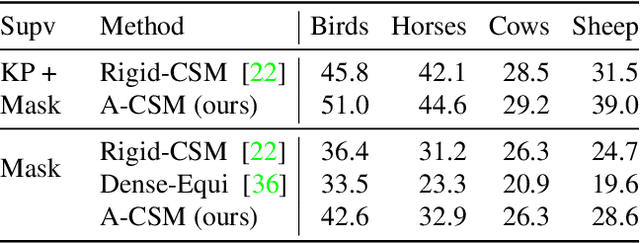
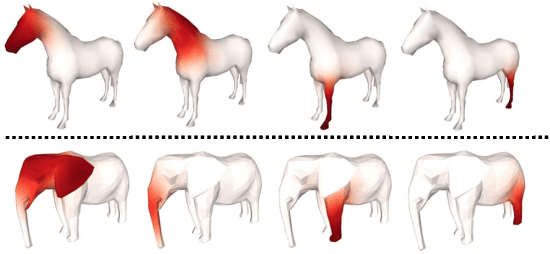
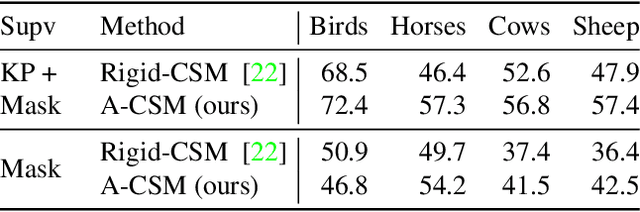
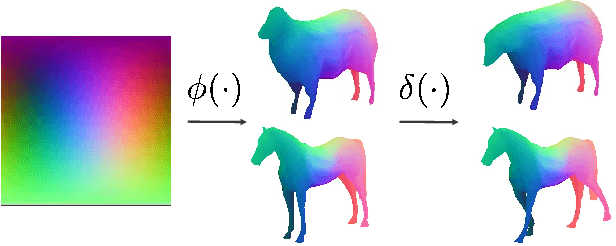
We tackle the tasks of: 1) predicting a Canonical Surface Mapping (CSM) that indicates the mapping from 2D pixels to corresponding points on a canonical template shape, and 2) inferring the articulation and pose of the template corresponding to the input image. While previous approaches rely on keypoint supervision for learning, we present an approach that can learn without such annotations. Our key insight is that these tasks are geometrically related, and we can obtain supervisory signal via enforcing consistency among the predictions. We present results across a diverse set of animal object categories, showing that our method can learn articulation and CSM prediction from image collections using only foreground mask labels for training. We empirically show that allowing articulation helps learn more accurate CSM prediction, and that enforcing the consistency with predicted CSM is similarly critical for learning meaningful articulation.