 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Camera Poses and Where to Find Them
Apr 24, 2025Annotating camera poses on dynamic Internet videos at scale is critical for advancing fields like realistic video generation and simulation. However, collecting such a dataset is difficult, as most Internet videos are unsuitable for pose estimation. Furthermore, annotating dynamic Internet videos present significant challenges even for state-of-theart methods. In this paper, we introduce DynPose-100K, a large-scale dataset of dynamic Internet videos annotated with camera poses. Our collection pipeline addresses filtering using a carefully combined set of task-specific and generalist models. For pose estimation, we combine the latest techniques of point tracking, dynamic masking, and structure-from-motion to achieve improvements over the state-of-the-art approaches. Our analysis and experiments demonstrate that DynPose-100K is both large-scale and diverse across several key attributes, opening up avenues for advancements in various downstream applications.
FAR: Flexible, Accurate and Robust 6DoF Relative Camera Pose Estimation
Mar 05, 2024Estimating relative camera poses between images has been a central problem in computer vision. Methods that find correspondences and solve for the fundamental matrix offer high precision in most cases. Conversely, methods predicting pose directly using neural networks are more robust to limited overlap and can infer absolute translation scale, but at the expense of reduced precision. We show how to combine the best of both methods; our approach yields results that are both precise and robust, while also accurately inferring translation scales. At the heart of our model lies a Transformer that (1) learns to balance between solved and learned pose estimations, and (2) provides a prior to guide a solver. A comprehensive analysis supports our design choices and demonstrates that our method adapts flexibly to various feature extractors and correspondence estimators, showing state-of-the-art performance in 6DoF pose estimation on Matterport3D, InteriorNet, StreetLearn, and Map-free Relocalization.
Scalable 3D Captioning with Pretrained Models
Jun 16, 2023We introduce Cap3D, an automatic approach for generating descriptive text for 3D objects. This approach utilizes pretrained models from image captioning, image-text alignment, and LLM to consolidate captions from multiple views of a 3D asset, completely side-stepping the time-consuming and costly process of manual annotation. We apply Cap3D to the recently introduced large-scale 3D dataset, Objaverse, resulting in 660k 3D-text pairs. Our evaluation, conducted using 41k human annotations from the same dataset, demonstrates that Cap3D surpasses human-authored descriptions in terms of quality, cost, and speed. Through effective prompt engineering, Cap3D rivals human performance in generating geometric descriptions on 17k collected annotations from the ABO dataset. Finally, we finetune Text-to-3D models on Cap3D and human captions, and show Cap3D outperforms; and benchmark the SOTA including Point-E, Shape-E, and DreamFusion.
The 8-Point Algorithm as an Inductive Bias for Relative Pose Prediction by ViTs
Aug 18, 2022
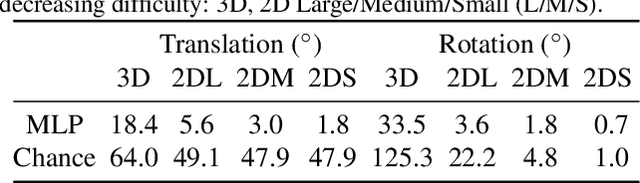
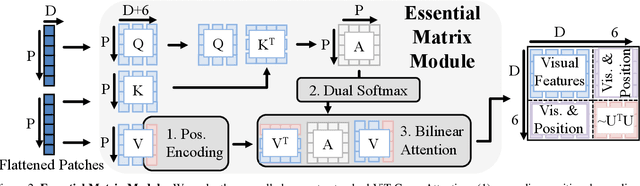
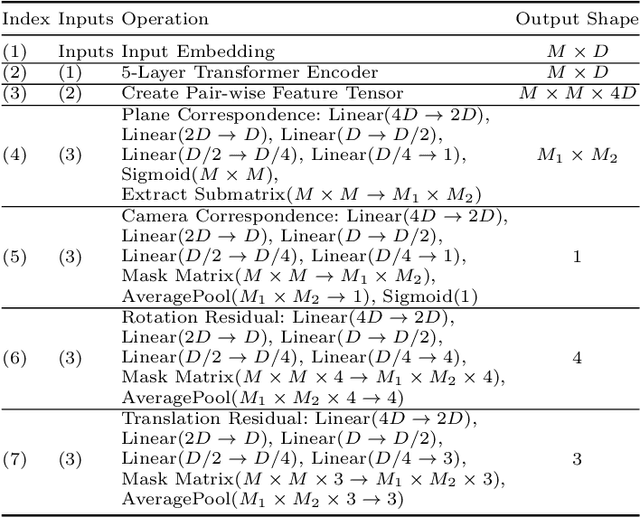
We present a simple baseline for directly estimating the relative pose (rotation and translation, including scale) between two images. Deep methods have recently shown strong progress but often require complex or multi-stage architectures. We show that a handful of modifications can be applied to a Vision Transformer (ViT) to bring its computations close to the Eight-Point Algorithm. This inductive bias enables a simple method to be competitive in multiple settings, often substantially improving over the state of the art with strong performance gains in limited data regimes.
PlaneFormers: From Sparse View Planes to 3D Reconstruction
Aug 08, 2022

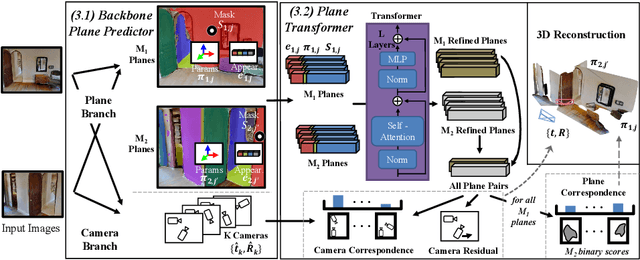
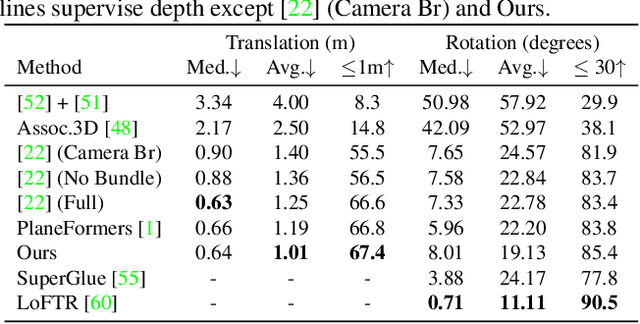
We present an approach for the planar surface reconstruction of a scene from images with limited overlap. This reconstruction task is challenging since it requires jointly reasoning about single image 3D reconstruction, correspondence between images, and the relative camera pose between images. Past work has proposed optimization-based approaches. We introduce a simpler approach, the PlaneFormer, that uses a transformer applied to 3D-aware plane tokens to perform 3D reasoning. Our experiments show that our approach is substantially more effective than prior work, and that several 3D-specific design decisions are crucial for its success.
FWD: Real-time Novel View Synthesis with Forward Warping and Depth
Jun 21, 2022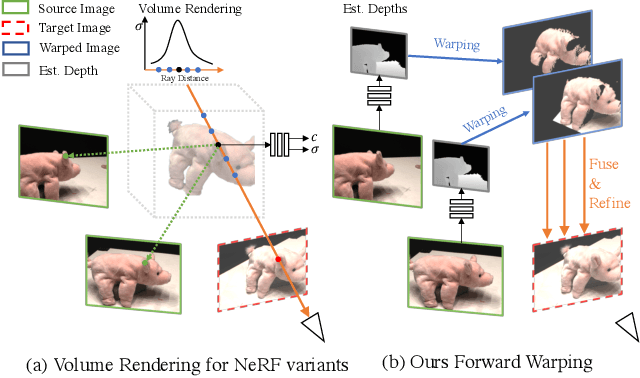



Novel view synthesis (NVS) is a challenging task requiring systems to generate photorealistic images of scenes from new viewpoints, where both quality and speed are important for applications. Previous image-based rendering (IBR) methods are fast, but have poor quality when input views are sparse. Recent Neural Radiance Fields (NeRF) and generalizable variants give impressive results but are not real-time. In our paper, we propose a generalizable NVS method with sparse inputs, called FWD, which gives high-quality synthesis in real-time. With explicit depth and differentiable rendering, it achieves competitive results to the SOTA methods with 130-1000x speedup and better perceptual quality. If available, we can seamlessly integrate sensor depth during either training or inference to improve image quality while retaining real-time speed. With the growing prevalence of depths sensors, we hope that methods making use of depth will become increasingly useful.
Understanding 3D Object Articulation in Internet Videos
Mar 30, 2022
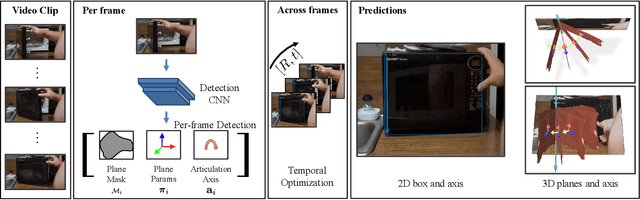


We propose to investigate detecting and characterizing the 3D planar articulation of objects from ordinary videos. While seemingly easy for humans, this problem poses many challenges for computers. We propose to approach this problem by combining a top-down detection system that finds planes that can be articulated along with an optimization approach that solves for a 3D plane that can explain a sequence of observed articulations. We show that this system can be trained on a combination of videos and 3D scan datasets. When tested on a dataset of challenging Internet videos and the Charades dataset, our approach obtains strong performance. Project site: https://jasonqsy.github.io/Articulation3D
PixelSynth: Generating a 3D-Consistent Experience from a Single Image
Aug 12, 2021
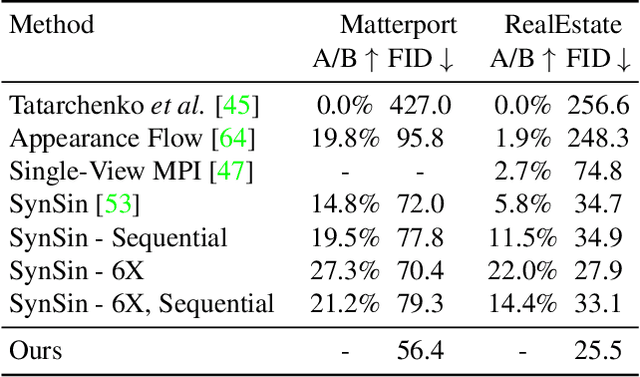


Recent advancements in differentiable rendering and 3D reasoning have driven exciting results in novel view synthesis from a single image. Despite realistic results, methods are limited to relatively small view change. In order to synthesize immersive scenes, models must also be able to extrapolate. We present an approach that fuses 3D reasoning with autoregressive modeling to outpaint large view changes in a 3D-consistent manner, enabling scene synthesis. We demonstrate considerable improvement in single image large-angle view synthesis results compared to a variety of methods and possible variants across simulated and real datasets. In addition, we show increased 3D consistency compared to alternative accumulation methods. Project website: https://crockwell.github.io/pixelsynth/
Full-Body Awareness from Partial Observations
Aug 13, 2020



There has been great progress in human 3D mesh recovery and great interest in learning about the world from consumer video data. Unfortunately current methods for 3D human mesh recovery work rather poorly on consumer video data, since on the Internet, unusual camera viewpoints and aggressive truncations are the norm rather than a rarity. We study this problem and make a number of contributions to address it: (i) we propose a simple but highly effective self-training framework that adapts human 3D mesh recovery systems to consumer videos and demonstrate its application to two recent systems; (ii) we introduce evaluation protocols and keypoint annotations for 13K frames across four consumer video datasets for studying this task, including evaluations on out-of-image keypoints; and (iii) we show that our method substantially improves PCK and human-subject judgments compared to baselines, both on test videos from the dataset it was trained on, as well as on three other datasets without further adaptation. Project website: https://crockwell.github.io/partial_humans