 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeim2nerf: Image to Neural Radiance Field in the Wild
Paper and Code
Sep 08, 2022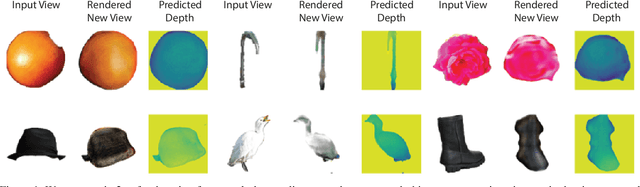
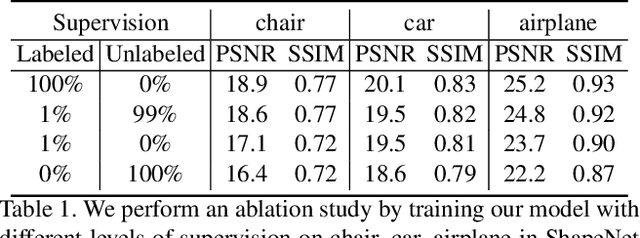
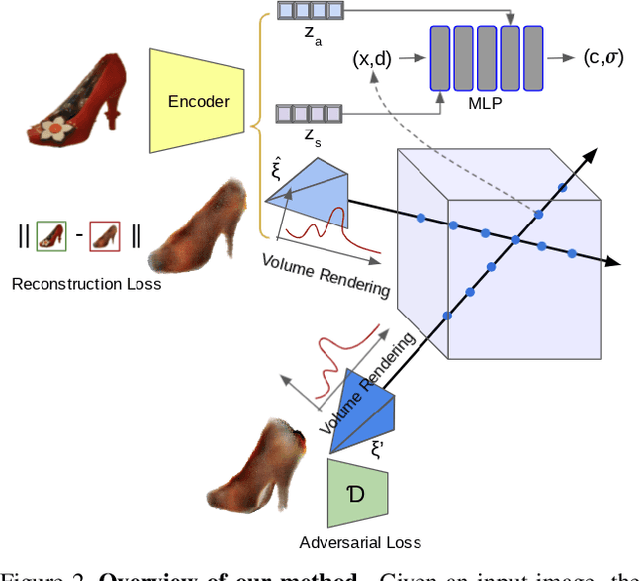
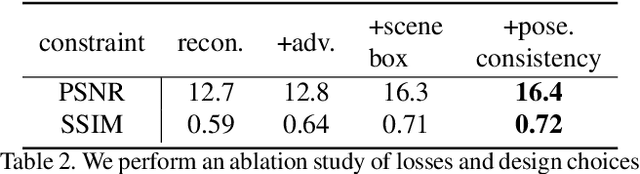
We propose im2nerf, a learning framework that predicts a continuous neural object representation given a single input image in the wild, supervised by only segmentation output from off-the-shelf recognition methods. The standard approach to constructing neural radiance fields takes advantage of multi-view consistency and requires many calibrated views of a scene, a requirement that cannot be satisfied when learning on large-scale image data in the wild. We take a step towards addressing this shortcoming by introducing a model that encodes the input image into a disentangled object representation that contains a code for object shape, a code for object appearance, and an estimated camera pose from which the object image is captured. Our model conditions a NeRF on the predicted object representation and uses volume rendering to generate images from novel views. We train the model end-to-end on a large collection of input images. As the model is only provided with single-view images, the problem is highly under-constrained. Therefore, in addition to using a reconstruction loss on the synthesized input view, we use an auxiliary adversarial loss on the novel rendered views. Furthermore, we leverage object symmetry and cycle camera pose consistency. We conduct extensive quantitative and qualitative experiments on the ShapeNet dataset as well as qualitative experiments on Open Images dataset. We show that in all cases, im2nerf achieves the state-of-the-art performance for novel view synthesis from a single-view unposed image in the wild.