 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoCast: Forecasting Egocentric Human Pose in the Wild
Dec 03, 2024



Accurately estimating and forecasting human body pose is important for enhancing the user's sense of immersion in Augmented Reality. Addressing this need, our paper introduces EgoCast, a bimodal method for 3D human pose forecasting using egocentric videos and proprioceptive data. We study the task of human pose forecasting in a realistic setting, extending the boundaries of temporal forecasting in dynamic scenes and building on the current framework for current pose estimation in the wild. We introduce a current-frame estimation module that generates pseudo-groundtruth poses for inference, eliminating the need for past groundtruth poses typically required by current methods during forecasting. Our experimental results on the recent Ego-Exo4D and Aria Digital Twin datasets validate EgoCast for real-life motion estimation. On the Ego-Exo4D Body Pose 2024 Challenge, our method significantly outperforms the state-of-the-art approaches, laying the groundwork for future research in human pose estimation and forecasting in unscripted activities with egocentric inputs.
TIPS: Text-Image Pretraining with Spatial Awareness
Oct 21, 2024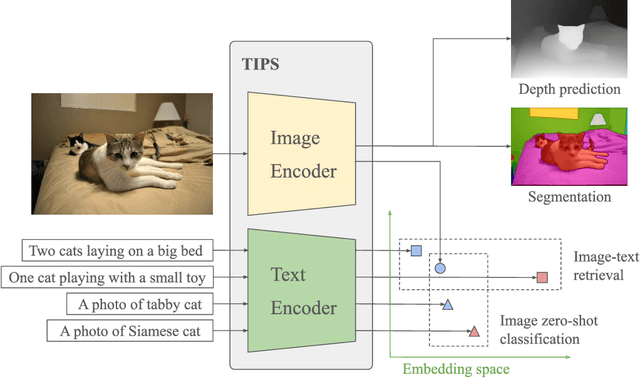
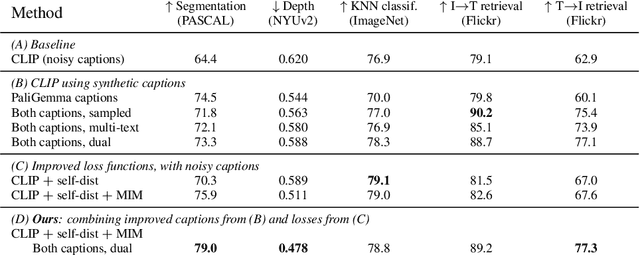
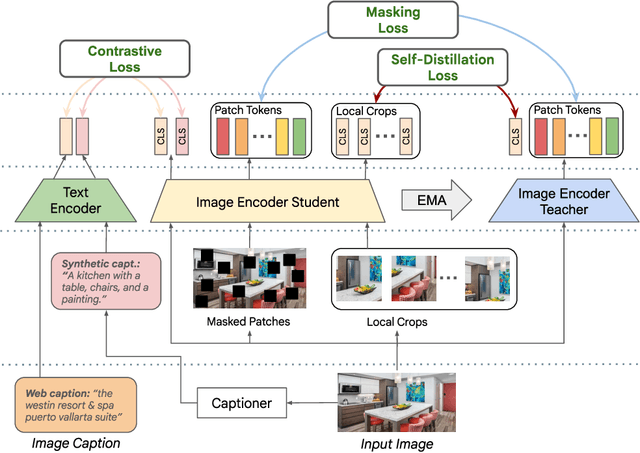
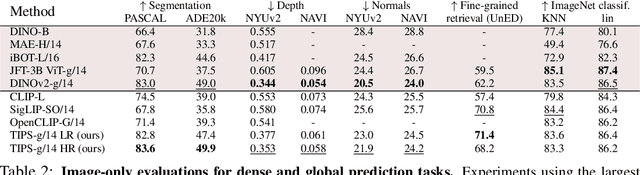
While image-text representation learning has become very popular in recent years, existing models tend to lack spatial awareness and have limited direct applicability for dense understanding tasks. For this reason, self-supervised image-only pretraining is still the go-to method for many dense vision applications (e.g. depth estimation, semantic segmentation), despite the lack of explicit supervisory signals. In this paper, we close this gap between image-text and self-supervised learning, by proposing a novel general-purpose image-text model, which can be effectively used off-the-shelf for dense and global vision tasks. Our method, which we refer to as Text-Image Pretraining with Spatial awareness (TIPS), leverages two simple and effective insights. First, on textual supervision: we reveal that replacing noisy web image captions by synthetically generated textual descriptions boosts dense understanding performance significantly, due to a much richer signal for learning spatially aware representations. We propose an adapted training method that combines noisy and synthetic captions, resulting in improvements across both dense and global understanding tasks. Second, on the learning technique: we propose to combine contrastive image-text learning with self-supervised masked image modeling, to encourage spatial coherence, unlocking substantial enhancements for downstream applications. Building on these two ideas, we scale our model using the transformer architecture, trained on a curated set of public images. Our experiments are conducted on 8 tasks involving 16 datasets in total, demonstrating strong off-the-shelf performance on both dense and global understanding, for several image-only and image-text tasks.
OmniNOCS: A unified NOCS dataset and model for 3D lifting of 2D objects
Jul 11, 2024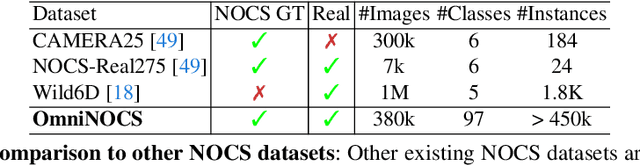


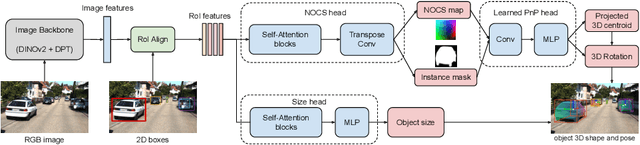
We propose OmniNOCS, a large-scale monocular dataset with 3D Normalized Object Coordinate Space (NOCS) maps, object masks, and 3D bounding box annotations for indoor and outdoor scenes. OmniNOCS has 20 times more object classes and 200 times more instances than existing NOCS datasets (NOCS-Real275, Wild6D). We use OmniNOCS to train a novel, transformer-based monocular NOCS prediction model (NOCSformer) that can predict accurate NOCS, instance masks and poses from 2D object detections across diverse classes. It is the first NOCS model that can generalize to a broad range of classes when prompted with 2D boxes. We evaluate our model on the task of 3D oriented bounding box prediction, where it achieves comparable results to state-of-the-art 3D detection methods such as Cube R-CNN. Unlike other 3D detection methods, our model also provides detailed and accurate 3D object shape and segmentation. We propose a novel benchmark for the task of NOCS prediction based on OmniNOCS, which we hope will serve as a useful baseline for future work in this area. Our dataset and code will be at the project website: https://omninocs.github.io.
Probing the 3D Awareness of Visual Foundation Models
Apr 12, 2024Recent advances in large-scale pretraining have yielded visual foundation models with strong capabilities. Not only can recent models generalize to arbitrary images for their training task, their intermediate representations are useful for other visual tasks such as detection and segmentation. Given that such models can classify, delineate, and localize objects in 2D, we ask whether they also represent their 3D structure? In this work, we analyze the 3D awareness of visual foundation models. We posit that 3D awareness implies that representations (1) encode the 3D structure of the scene and (2) consistently represent the surface across views. We conduct a series of experiments using task-specific probes and zero-shot inference procedures on frozen features. Our experiments reveal several limitations of the current models. Our code and analysis can be found at https://github.com/mbanani/probe3d.
EgoCOL: Egocentric Camera pose estimation for Open-world 3D object Localization @Ego4D challenge 2023
Jun 29, 2023



We present EgoCOL, an egocentric camera pose estimation method for open-world 3D object localization. Our method leverages sparse camera pose reconstructions in a two-fold manner, video and scan independently, to estimate the camera pose of egocentric frames in 3D renders with high recall and precision. We extensively evaluate our method on the Visual Query (VQ) 3D object localization Ego4D benchmark. EgoCOL can estimate 62% and 59% more camera poses than the Ego4D baseline in the Ego4D Visual Queries 3D Localization challenge at CVPR 2023 in the val and test sets, respectively. Our code is publicly available at https://github.com/BCV-Uniandes/EgoCOL
Estimating Generic 3D Room Structures from 2D Annotations
Jun 15, 2023



Indoor rooms are among the most common use cases in 3D scene understanding. Current state-of-the-art methods for this task are driven by large annotated datasets. Room layouts are especially important, consisting of structural elements in 3D, such as wall, floor, and ceiling. However, they are difficult to annotate, especially on pure RGB video. We propose a novel method to produce generic 3D room layouts just from 2D segmentation masks, which are easy to annotate for humans. Based on these 2D annotations, we automatically reconstruct 3D plane equations for the structural elements and their spatial extent in the scene, and connect adjacent elements at the appropriate contact edges. We annotate and publicly release 2266 3D room layouts on the RealEstate10k dataset, containing YouTube videos. We demonstrate the high quality of these 3D layouts annotations with extensive experiments.
CAD-Estate: Large-scale CAD Model Annotation in RGB Videos
Jun 15, 2023



We propose a method for annotating videos of complex multi-object scenes with a globally-consistent 3D representation of the objects. We annotate each object with a CAD model from a database, and place it in the 3D coordinate frame of the scene with a 9-DoF pose transformation. Our method is semi-automatic and works on commonly-available RGB videos, without requiring a depth sensor. Many steps are performed automatically, and the tasks performed by humans are simple, well-specified, and require only limited reasoning in 3D. This makes them feasible for crowd-sourcing and has allowed us to construct a large-scale dataset by annotating real-estate videos from YouTube. Our dataset CAD-Estate offers 108K instances of 12K unique CAD models placed in the 3D representations of 21K videos. In comparison to Scan2CAD, the largest existing dataset with CAD model annotations on real scenes, CAD-Estate has 8x more instances and 4x more unique CAD models. We showcase the benefits of pre-training a Mask2CAD model on CAD-Estate for the task of automatic 3D object reconstruction and pose estimation, demonstrating that it leads to improvements on the popular Scan2CAD benchmark. We will release the data by mid July 2023.
NAVI: Category-Agnostic Image Collections with High-Quality 3D Shape and Pose Annotations
Jun 15, 2023



Recent advances in neural reconstruction enable high-quality 3D object reconstruction from casually captured image collections. Current techniques mostly analyze their progress on relatively simple image collections where Structure-from-Motion (SfM) techniques can provide ground-truth (GT) camera poses. We note that SfM techniques tend to fail on in-the-wild image collections such as image search results with varying backgrounds and illuminations. To enable systematic research progress on 3D reconstruction from casual image captures, we propose NAVI: a new dataset of category-agnostic image collections of objects with high-quality 3D scans along with per-image 2D-3D alignments providing near-perfect GT camera parameters. These 2D-3D alignments allow us to extract accurate derivative annotations such as dense pixel correspondences, depth and segmentation maps. We demonstrate the use of NAVI image collections on different problem settings and show that NAVI enables more thorough evaluations that were not possible with existing datasets. We believe NAVI is beneficial for systematic research progress on 3D reconstruction and correspondence estimation. Project page: https://navidataset.github.io
RayTran: 3D pose estimation and shape reconstruction of multiple objects from videos with ray-traced transformers
Mar 24, 2022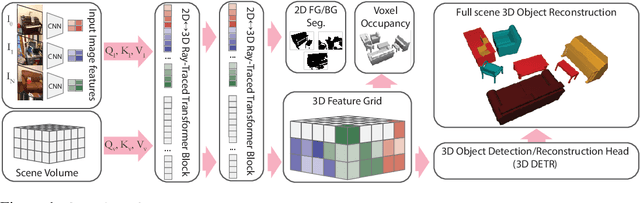
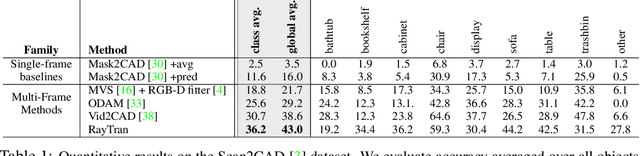
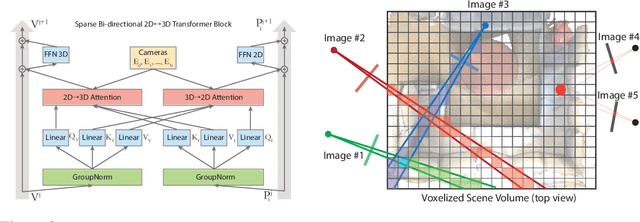
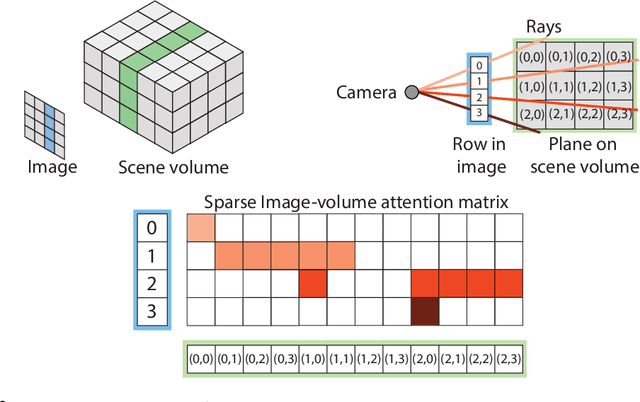
We propose a transformer-based neural network architecture for multi-object 3D reconstruction from RGB videos. It relies on two alternative ways to represent its knowledge: as a global 3D grid of features and an array of view-specific 2D grids. We progressively exchange information between the two with a dedicated bidirectional attention mechanism. We exploit knowledge about the image formation process to significantly sparsify the attention weight matrix, making our architecture feasible on current hardware, both in terms of memory and computation. We attach a DETR-style head on top of the 3D feature grid in order to detect the objects in the scene and to predict their 3D pose and 3D shape. Compared to previous methods, our architecture is single stage, end-to-end trainable, and it can reason holistically about a scene from multiple video frames without needing a brittle tracking step. We evaluate our method on the challenging Scan2CAD dataset, where we outperform (1) recent state-of-the-art methods for 3D object pose estimation from RGB videos; and (2) a strong alternative method combining Multi-view Stereo with RGB-D CAD alignment. We plan to release our source code.
Vid2CAD: CAD Model Alignment using Multi-View Constraints from Videos
Dec 08, 2020
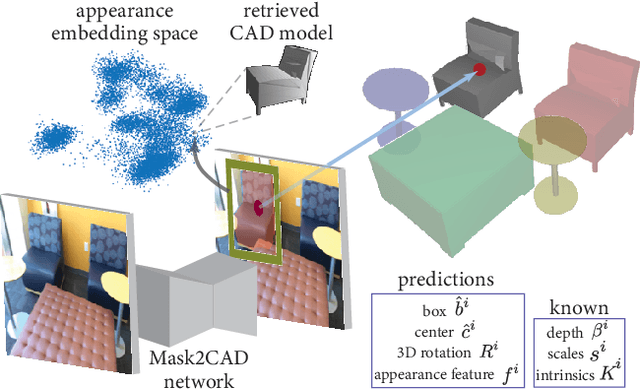
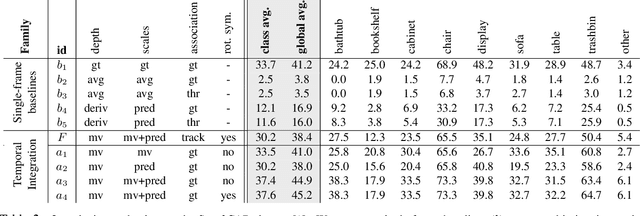

We address the task of aligning CAD models to a video sequence of a complex scene containing multiple objects. Our method is able to process arbitrary videos and fully automatically recover the 9 DoF pose for each object appearing in it, thus aligning them in a common 3D coordinate frame. The core idea of our method is to integrate neural network predictions from individual frames with a temporally global, multi-view constraint optimization formulation. This integration process resolves the scale and depth ambiguities in the per-frame predictions, and generally improves the estimate of all pose parameters. By leveraging multi-view constraints, our method also resolves occlusions and handles objects that are out of view in individual frames, thus reconstructing all objects into a single globally consistent CAD representation of the scene. In comparison to the state-of-the-art single-frame method Mask2CAD that we build on, we achieve substantial improvements on Scan2CAD (from 11.6% to 30.2% class average accuracy).