 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVid2CAD: CAD Model Alignment using Multi-View Constraints from Videos
Paper and Code
Dec 08, 2020
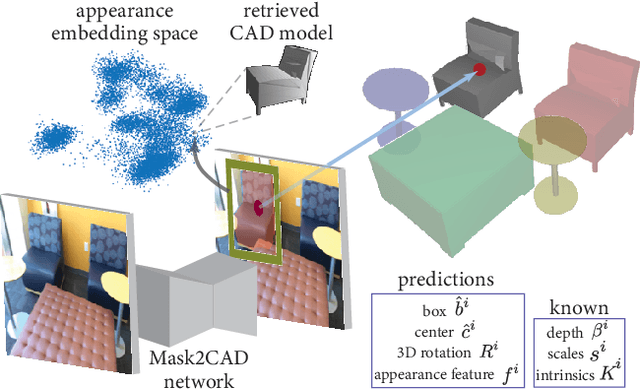
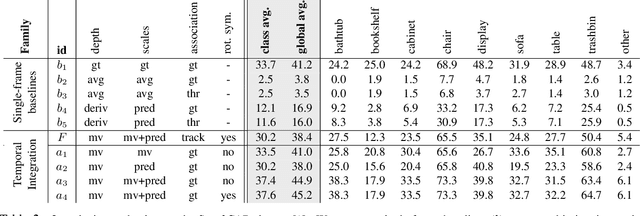

We address the task of aligning CAD models to a video sequence of a complex scene containing multiple objects. Our method is able to process arbitrary videos and fully automatically recover the 9 DoF pose for each object appearing in it, thus aligning them in a common 3D coordinate frame. The core idea of our method is to integrate neural network predictions from individual frames with a temporally global, multi-view constraint optimization formulation. This integration process resolves the scale and depth ambiguities in the per-frame predictions, and generally improves the estimate of all pose parameters. By leveraging multi-view constraints, our method also resolves occlusions and handles objects that are out of view in individual frames, thus reconstructing all objects into a single globally consistent CAD representation of the scene. In comparison to the state-of-the-art single-frame method Mask2CAD that we build on, we achieve substantial improvements on Scan2CAD (from 11.6% to 30.2% class average accuracy).