 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Tracing: Generative Pixel-Aligned Geometry Beyond the Visible
Jun 11, 2026Image-to-3D methods often trade off faithfulness and completeness: depth estimators are anchored to input pixels but stop at the visible surface, while image-to-3D models generate complete shapes that are often misaligned with the input. We introduce World Tracing, a generative pixel-aligned geometry representation that predicts 3D points aligned with observed pixels while completing geometry beyond the visible surface. For each input pixel, World Tracing predicts an ordered stack of camera-space 3D points, where the first layer represents the visible surface and subsequent layers represent front-to-back intersections with occluded surfaces. We instantiate this representation with a world-tracing diffusion transformer, WT-DiT, which treats multiple geometry layers as separate denoising tokens coupled through factorized and global attention. WT-DiT is trained with pixel-space flow matching and a mixed noise schedule that balances visible-surface reconstruction with occluded-geometry generation. World Tracing achieves strong performance on visible-surface reconstruction and complete geometry generation across object, scene, and dynamic benchmarks, outperforming both depth predictors and image-to-3D generators. It also preserves 2D-to-3D correspondence, enabling text-driven 3D scene editing, geometry-conditioned novel-view video synthesis, and training-free integration with textured-mesh generators.
Probing the 3D Awareness of Visual Foundation Models
Apr 12, 2024Recent advances in large-scale pretraining have yielded visual foundation models with strong capabilities. Not only can recent models generalize to arbitrary images for their training task, their intermediate representations are useful for other visual tasks such as detection and segmentation. Given that such models can classify, delineate, and localize objects in 2D, we ask whether they also represent their 3D structure? In this work, we analyze the 3D awareness of visual foundation models. We posit that 3D awareness implies that representations (1) encode the 3D structure of the scene and (2) consistently represent the surface across views. We conduct a series of experiments using task-specific probes and zero-shot inference procedures on frozen features. Our experiments reveal several limitations of the current models. Our code and analysis can be found at https://github.com/mbanani/probe3d.
Learning Visual Representations via Language-Guided Sampling
Feb 23, 2023



Although an object may appear in numerous contexts, we often describe it in a limited number of ways. This happens because language abstracts away visual variation to represent and communicate concepts. Building on this intuition, we propose an alternative approach to visual learning: using language similarity to sample semantically similar image pairs for contrastive learning. Our approach deviates from image-based contrastive learning by using language to sample pairs instead of hand-crafted augmentations or learned clusters. Our approach also deviates from image-text contrastive learning by relying on pre-trained language models to guide the learning rather than minimize a cross-modal similarity. Through a series of experiments, we show that language-guided learning can learn better features than both image-image and image-text representation learning approaches.
Self-Supervised Correspondence Estimation via Multiview Registration
Dec 06, 2022



Video provides us with the spatio-temporal consistency needed for visual learning. Recent approaches have utilized this signal to learn correspondence estimation from close-by frame pairs. However, by only relying on close-by frame pairs, those approaches miss out on the richer long-range consistency between distant overlapping frames. To address this, we propose a self-supervised approach for correspondence estimation that learns from multiview consistency in short RGB-D video sequences. Our approach combines pairwise correspondence estimation and registration with a novel SE(3) transformation synchronization algorithm. Our key insight is that self-supervised multiview registration allows us to obtain correspondences over longer time frames; increasing both the diversity and difficulty of sampled pairs. We evaluate our approach on indoor scenes for correspondence estimation and RGB-D pointcloud registration and find that we perform on-par with supervised approaches.
Bootstrap Your Own Correspondences
Jun 01, 2021


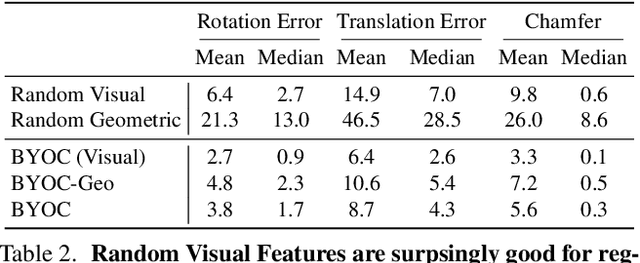
Geometric feature extraction is a crucial component of point cloud registration pipelines. Recent work has demonstrated how supervised learning can be leveraged to learn better and more compact 3D features. However, those approaches' reliance on ground-truth annotation limits their scalability. We propose BYOC: a self-supervised approach that learns visual and geometric features from RGB-D video without relying on ground-truth pose or correspondence. Our key observation is that randomly-initialized CNNs readily provide us with good correspondences; allowing us to bootstrap the learning of both visual and geometric features. Our approach combines classic ideas from point cloud registration with more recent representation learning approaches. We evaluate our approach on indoor scene datasets and find that our method outperforms traditional and learned descriptors, while being competitive with current state-of-the-art supervised approaches.
UnsupervisedR&R: Unsupervised Point Cloud Registration via Differentiable Rendering
Feb 23, 2021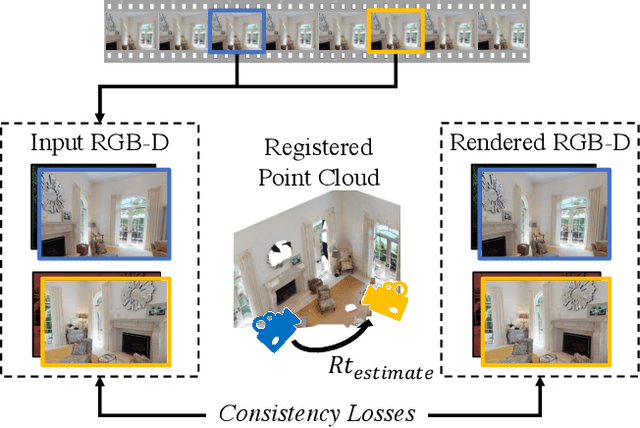
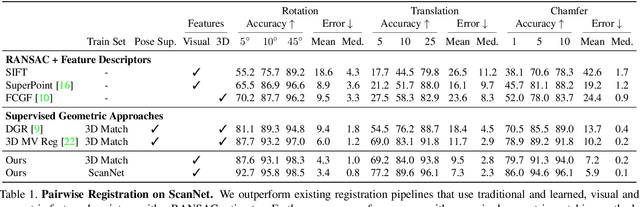
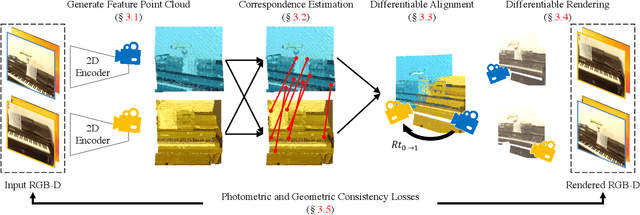
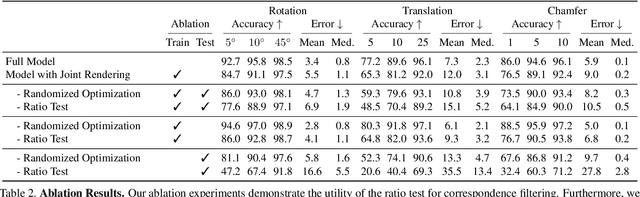
Aligning partial views of a scene into a single whole is essential to understanding one's environment and is a key component of numerous robotics tasks such as SLAM and SfM. Recent approaches have proposed end-to-end systems that can outperform traditional methods by leveraging pose supervision. However, with the rising prevalence of cameras with depth sensors, we can expect a new stream of raw RGB-D data without the annotations needed for supervision. We propose UnsupervisedR&R: an end-to-end unsupervised approach to learning point cloud registration from raw RGB-D video. The key idea is to leverage differentiable alignment and rendering to enforce photometric and geometric consistency between frames. We evaluate our approach on indoor scene datasets and find that we outperform existing traditional approaches with classic and learned descriptors while being competitive with supervised geometric point cloud registration approaches.
Novel Object Viewpoint Estimation through Reconstruction Alignment
Jun 05, 2020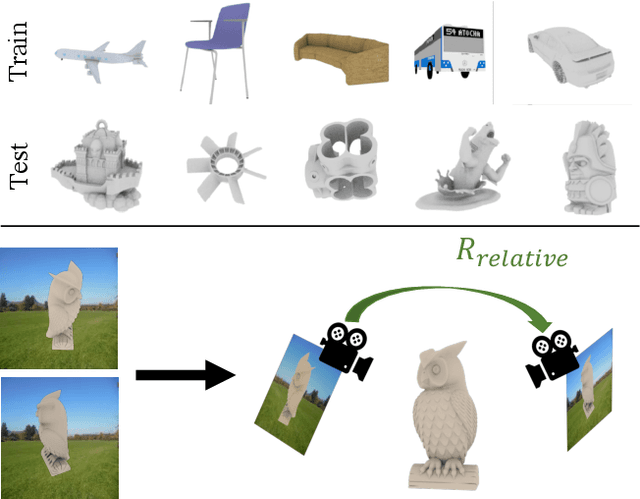

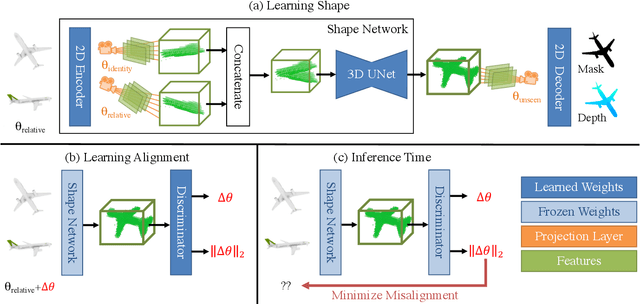

The goal of this paper is to estimate the viewpoint for a novel object. Standard viewpoint estimation approaches generally fail on this task due to their reliance on a 3D model for alignment or large amounts of class-specific training data and their corresponding canonical pose. We overcome those limitations by learning a reconstruct and align approach. Our key insight is that although we do not have an explicit 3D model or a predefined canonical pose, we can still learn to estimate the object's shape in the viewer's frame and then use an image to provide our reference model or canonical pose. In particular, we propose learning two networks: the first maps images to a 3D geometry-aware feature bottleneck and is trained via an image-to-image translation loss; the second learns whether two instances of features are aligned. At test time, our model finds the relative transformation that best aligns the bottleneck features of our test image to a reference image. We evaluate our method on novel object viewpoint estimation by generalizing across different datasets, analyzing the impact of our different modules, and providing a qualitative analysis of the learned features to identify what representations are being learnt for alignment.
Adviser Networks: Learning What Question to Ask for Human-In-The-Loop Viewpoint Estimation
Oct 25, 2018
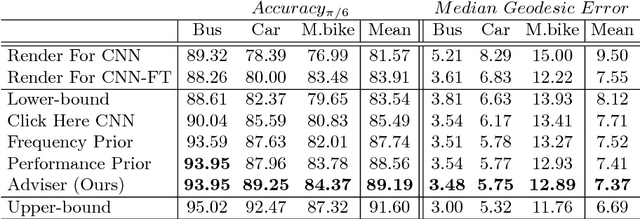
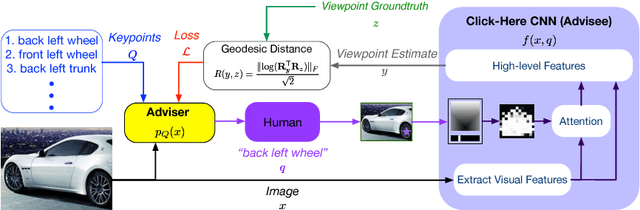

Humans have an unparalleled visual intelligence and can overcome visual ambiguities that machines currently cannot. Recent works have shown that incorporating guidance from humans during inference for monocular viewpoint-estimation can help overcome difficult cases in which the computer-alone would have otherwise failed. These hybrid intelligence approaches are hence gaining traction. However, deciding what question to ask the human at inference time remains an unknown for these problems. We address this question by formulating it as an Adviser Problem: can we learn a mapping from the input to a specific question to ask the human to maximize the expected positive impact to the overall task? We formulate a solution to the adviser problem for viewpoint estimation using a deep network where the question asks for the location of a keypoint in the input image. We show that by using the Adviser Network's recommendations, the model and the human outperforms the previous hybrid-intelligence state-of-the-art by 3.7%, and the computer-only state-of-the-art by 5.28% absolute.