 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdviser Networks: Learning What Question to Ask for Human-In-The-Loop Viewpoint Estimation
Paper and Code

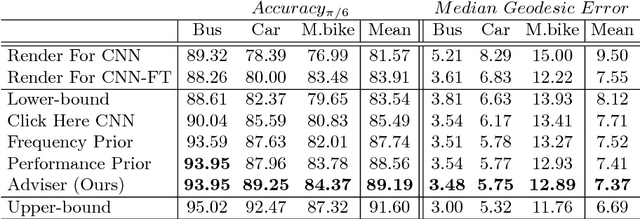
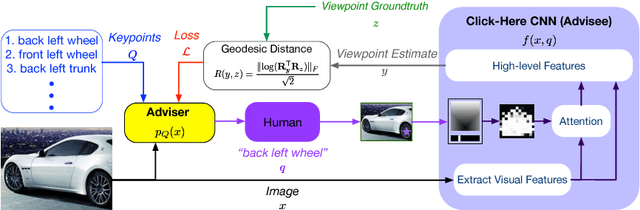

Humans have an unparalleled visual intelligence and can overcome visual ambiguities that machines currently cannot. Recent works have shown that incorporating guidance from humans during inference for monocular viewpoint-estimation can help overcome difficult cases in which the computer-alone would have otherwise failed. These hybrid intelligence approaches are hence gaining traction. However, deciding what question to ask the human at inference time remains an unknown for these problems. We address this question by formulating it as an Adviser Problem: can we learn a mapping from the input to a specific question to ask the human to maximize the expected positive impact to the overall task? We formulate a solution to the adviser problem for viewpoint estimation using a deep network where the question asks for the location of a keypoint in the input image. We show that by using the Adviser Network's recommendations, the model and the human outperforms the previous hybrid-intelligence state-of-the-art by 3.7%, and the computer-only state-of-the-art by 5.28% absolute.