 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel Object Viewpoint Estimation through Reconstruction Alignment
Paper and Code
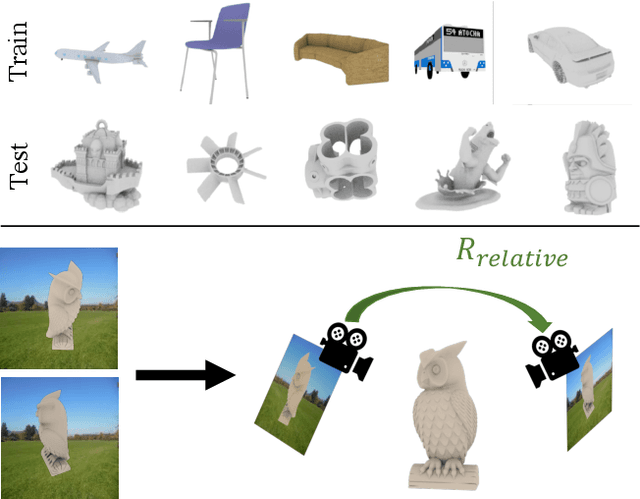

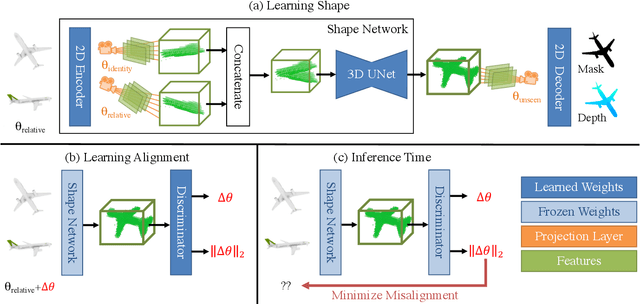

The goal of this paper is to estimate the viewpoint for a novel object. Standard viewpoint estimation approaches generally fail on this task due to their reliance on a 3D model for alignment or large amounts of class-specific training data and their corresponding canonical pose. We overcome those limitations by learning a reconstruct and align approach. Our key insight is that although we do not have an explicit 3D model or a predefined canonical pose, we can still learn to estimate the object's shape in the viewer's frame and then use an image to provide our reference model or canonical pose. In particular, we propose learning two networks: the first maps images to a 3D geometry-aware feature bottleneck and is trained via an image-to-image translation loss; the second learns whether two instances of features are aligned. At test time, our model finds the relative transformation that best aligns the bottleneck features of our test image to a reference image. We evaluate our method on novel object viewpoint estimation by generalizing across different datasets, analyzing the impact of our different modules, and providing a qualitative analysis of the learned features to identify what representations are being learnt for alignment.