 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegaSaM: Accurate, Fast, and Robust Structure and Motion from Casual Dynamic Videos
Dec 05, 2024



We present a system that allows for accurate, fast, and robust estimation of camera parameters and depth maps from casual monocular videos of dynamic scenes. Most conventional structure from motion and monocular SLAM techniques assume input videos that feature predominantly static scenes with large amounts of parallax. Such methods tend to produce erroneous estimates in the absence of these conditions. Recent neural network-based approaches attempt to overcome these challenges; however, such methods are either computationally expensive or brittle when run on dynamic videos with uncontrolled camera motion or unknown field of view. We demonstrate the surprising effectiveness of a deep visual SLAM framework: with careful modifications to its training and inference schemes, this system can scale to real-world videos of complex dynamic scenes with unconstrained camera paths, including videos with little camera parallax. Extensive experiments on both synthetic and real videos demonstrate that our system is significantly more accurate and robust at camera pose and depth estimation when compared with prior and concurrent work, with faster or comparable running times. See interactive results on our project page: https://mega-sam.github.io/
Motion Prompting: Controlling Video Generation with Motion Trajectories
Dec 03, 2024Motion control is crucial for generating expressive and compelling video content; however, most existing video generation models rely mainly on text prompts for control, which struggle to capture the nuances of dynamic actions and temporal compositions. To this end, we train a video generation model conditioned on spatio-temporally sparse or dense motion trajectories. In contrast to prior motion conditioning work, this flexible representation can encode any number of trajectories, object-specific or global scene motion, and temporally sparse motion; due to its flexibility we refer to this conditioning as motion prompts. While users may directly specify sparse trajectories, we also show how to translate high-level user requests into detailed, semi-dense motion prompts, a process we term motion prompt expansion. We demonstrate the versatility of our approach through various applications, including camera and object motion control, "interacting" with an image, motion transfer, and image editing. Our results showcase emergent behaviors, such as realistic physics, suggesting the potential of motion prompts for probing video models and interacting with future generative world models. Finally, we evaluate quantitatively, conduct a human study, and demonstrate strong performance. Video results are available on our webpage: https://motion-prompting.github.io/
Generative Omnimatte: Learning to Decompose Video into Layers
Nov 25, 2024Given a video and a set of input object masks, an omnimatte method aims to decompose the video into semantically meaningful layers containing individual objects along with their associated effects, such as shadows and reflections. Existing omnimatte methods assume a static background or accurate pose and depth estimation and produce poor decompositions when these assumptions are violated. Furthermore, due to the lack of generative prior on natural videos, existing methods cannot complete dynamic occluded regions. We present a novel generative layered video decomposition framework to address the omnimatte problem. Our method does not assume a stationary scene or require camera pose or depth information and produces clean, complete layers, including convincing completions of occluded dynamic regions. Our core idea is to train a video diffusion model to identify and remove scene effects caused by a specific object. We show that this model can be finetuned from an existing video inpainting model with a small, carefully curated dataset, and demonstrate high-quality decompositions and editing results for a wide range of casually captured videos containing soft shadows, glossy reflections, splashing water, and more.
VidPanos: Generative Panoramic Videos from Casual Panning Videos
Oct 17, 2024
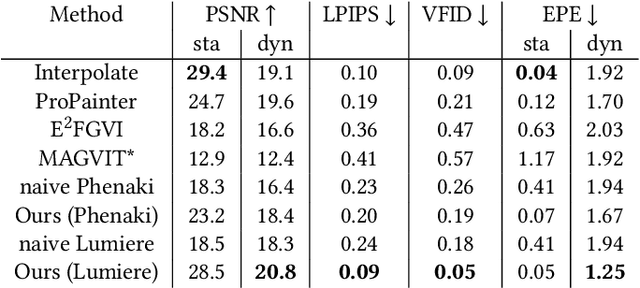
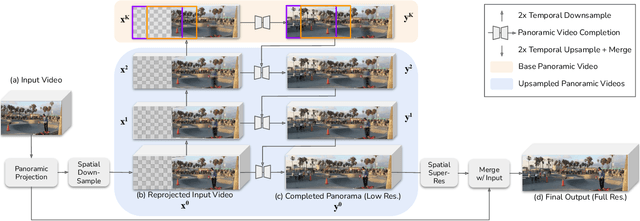
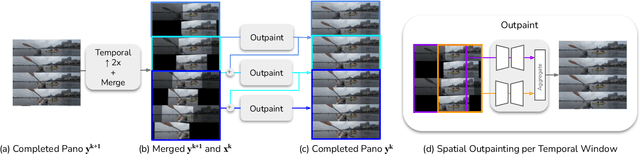
Panoramic image stitching provides a unified, wide-angle view of a scene that extends beyond the camera's field of view. Stitching frames of a panning video into a panoramic photograph is a well-understood problem for stationary scenes, but when objects are moving, a still panorama cannot capture the scene. We present a method for synthesizing a panoramic video from a casually-captured panning video, as if the original video were captured with a wide-angle camera. We pose panorama synthesis as a space-time outpainting problem, where we aim to create a full panoramic video of the same length as the input video. Consistent completion of the space-time volume requires a powerful, realistic prior over video content and motion, for which we adapt generative video models. Existing generative models do not, however, immediately extend to panorama completion, as we show. We instead apply video generation as a component of our panorama synthesis system, and demonstrate how to exploit the strengths of the models while minimizing their limitations. Our system can create video panoramas for a range of in-the-wild scenes including people, vehicles, and flowing water, as well as stationary background features.
MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion
Oct 04, 2024



Estimating geometry from dynamic scenes, where objects move and deform over time, remains a core challenge in computer vision. Current approaches often rely on multi-stage pipelines or global optimizations that decompose the problem into subtasks, like depth and flow, leading to complex systems prone to errors. In this paper, we present Motion DUSt3R (MonST3R), a novel geometry-first approach that directly estimates per-timestep geometry from dynamic scenes. Our key insight is that by simply estimating a pointmap for each timestep, we can effectively adapt DUST3R's representation, previously only used for static scenes, to dynamic scenes. However, this approach presents a significant challenge: the scarcity of suitable training data, namely dynamic, posed videos with depth labels. Despite this, we show that by posing the problem as a fine-tuning task, identifying several suitable datasets, and strategically training the model on this limited data, we can surprisingly enable the model to handle dynamics, even without an explicit motion representation. Based on this, we introduce new optimizations for several downstream video-specific tasks and demonstrate strong performance on video depth and camera pose estimation, outperforming prior work in terms of robustness and efficiency. Moreover, MonST3R shows promising results for primarily feed-forward 4D reconstruction.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
ExtraNeRF: Visibility-Aware View Extrapolation of Neural Radiance Fields with Diffusion Models
Jun 10, 2024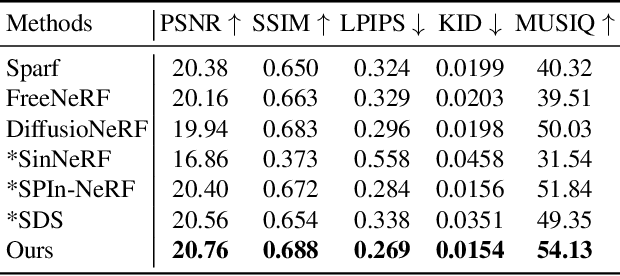
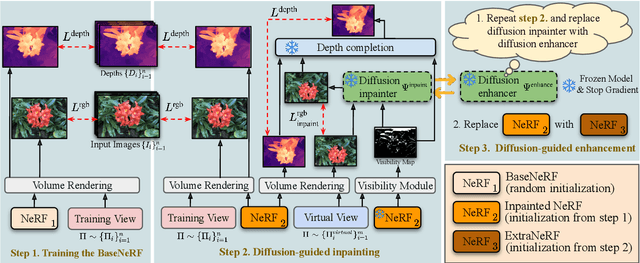
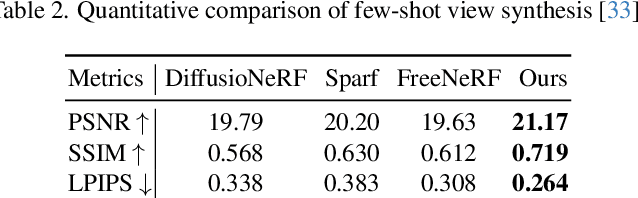
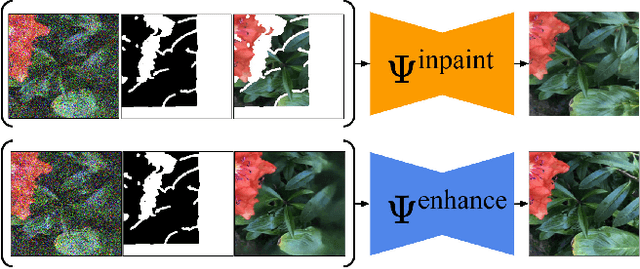
We propose ExtraNeRF, a novel method for extrapolating the range of views handled by a Neural Radiance Field (NeRF). Our main idea is to leverage NeRFs to model scene-specific, fine-grained details, while capitalizing on diffusion models to extrapolate beyond our observed data. A key ingredient is to track visibility to determine what portions of the scene have not been observed, and focus on reconstructing those regions consistently with diffusion models. Our primary contributions include a visibility-aware diffusion-based inpainting module that is fine-tuned on the input imagery, yielding an initial NeRF with moderate quality (often blurry) inpainted regions, followed by a second diffusion model trained on the input imagery to consistently enhance, notably sharpen, the inpainted imagery from the first pass. We demonstrate high-quality results, extrapolating beyond a small number of (typically six or fewer) input views, effectively outpainting the NeRF as well as inpainting newly disoccluded regions inside the original viewing volume. We compare with related work both quantitatively and qualitatively and show significant gains over prior art.
DreamWalk: Style Space Exploration using Diffusion Guidance
Apr 04, 2024Text-conditioned diffusion models can generate impressive images, but fall short when it comes to fine-grained control. Unlike direct-editing tools like Photoshop, text conditioned models require the artist to perform "prompt engineering," constructing special text sentences to control the style or amount of a particular subject present in the output image. Our goal is to provide fine-grained control over the style and substance specified by the prompt, for example to adjust the intensity of styles in different regions of the image (Figure 1). Our approach is to decompose the text prompt into conceptual elements, and apply a separate guidance term for each element in a single diffusion process. We introduce guidance scale functions to control when in the diffusion process and \emph{where} in the image to intervene. Since the method is based solely on adjusting diffusion guidance, it does not require fine-tuning or manipulating the internal layers of the diffusion model's neural network, and can be used in conjunction with LoRA- or DreamBooth-trained models (Figure2). Project page: https://mshu1.github.io/dreamwalk.github.io/
WonderJourney: Going from Anywhere to Everywhere
Dec 06, 2023



We introduce WonderJourney, a modularized framework for perpetual 3D scene generation. Unlike prior work on view generation that focuses on a single type of scenes, we start at any user-provided location (by a text description or an image) and generate a journey through a long sequence of diverse yet coherently connected 3D scenes. We leverage an LLM to generate textual descriptions of the scenes in this journey, a text-driven point cloud generation pipeline to make a compelling and coherent sequence of 3D scenes, and a large VLM to verify the generated scenes. We show compelling, diverse visual results across various scene types and styles, forming imaginary "wonderjourneys". Project website: https://kovenyu.com/WonderJourney/
ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs
Nov 22, 2023



Methods for finetuning generative models for concept-driven personalization generally achieve strong results for subject-driven or style-driven generation. Recently, low-rank adaptations (LoRA) have been proposed as a parameter-efficient way of achieving concept-driven personalization. While recent work explores the combination of separate LoRAs to achieve joint generation of learned styles and subjects, existing techniques do not reliably address the problem; they often compromise either subject fidelity or style fidelity. We propose ZipLoRA, a method to cheaply and effectively merge independently trained style and subject LoRAs in order to achieve generation of any user-provided subject in any user-provided style. Experiments on a wide range of subject and style combinations show that ZipLoRA can generate compelling results with meaningful improvements over baselines in subject and style fidelity while preserving the ability to recontextualize. Project page: https://ziplora.github.io