 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtraNeRF: Visibility-Aware View Extrapolation of Neural Radiance Fields with Diffusion Models
Jun 10, 2024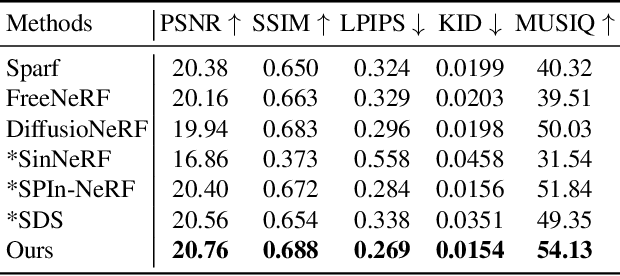
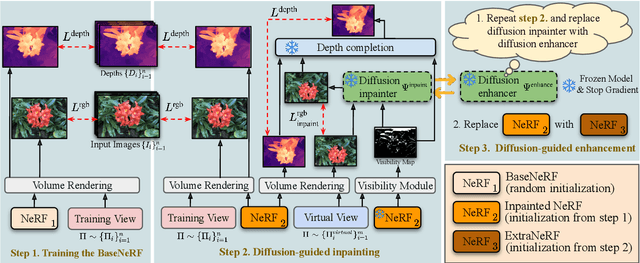
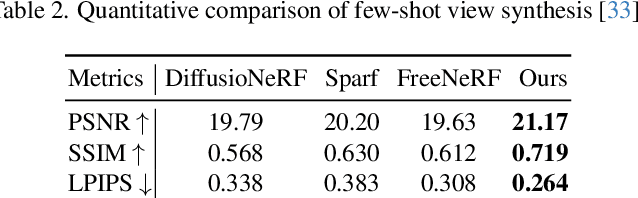
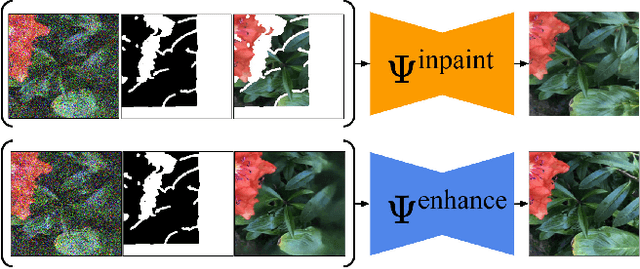
We propose ExtraNeRF, a novel method for extrapolating the range of views handled by a Neural Radiance Field (NeRF). Our main idea is to leverage NeRFs to model scene-specific, fine-grained details, while capitalizing on diffusion models to extrapolate beyond our observed data. A key ingredient is to track visibility to determine what portions of the scene have not been observed, and focus on reconstructing those regions consistently with diffusion models. Our primary contributions include a visibility-aware diffusion-based inpainting module that is fine-tuned on the input imagery, yielding an initial NeRF with moderate quality (often blurry) inpainted regions, followed by a second diffusion model trained on the input imagery to consistently enhance, notably sharpen, the inpainted imagery from the first pass. We demonstrate high-quality results, extrapolating beyond a small number of (typically six or fewer) input views, effectively outpainting the NeRF as well as inpainting newly disoccluded regions inside the original viewing volume. We compare with related work both quantitatively and qualitatively and show significant gains over prior art.
Infinite Texture: Text-guided High Resolution Diffusion Texture Synthesis
May 13, 2024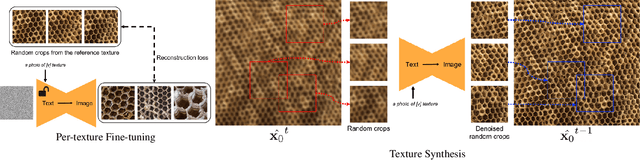



We present Infinite Texture, a method for generating arbitrarily large texture images from a text prompt. Our approach fine-tunes a diffusion model on a single texture, and learns to embed that statistical distribution in the output domain of the model. We seed this fine-tuning process with a sample texture patch, which can be optionally generated from a text-to-image model like DALL-E 2. At generation time, our fine-tuned diffusion model is used through a score aggregation strategy to generate output texture images of arbitrary resolution on a single GPU. We compare synthesized textures from our method to existing work in patch-based and deep learning texture synthesis methods. We also showcase two applications of our generated textures in 3D rendering and texture transfer.
Repopulating Street Scenes
Mar 30, 2021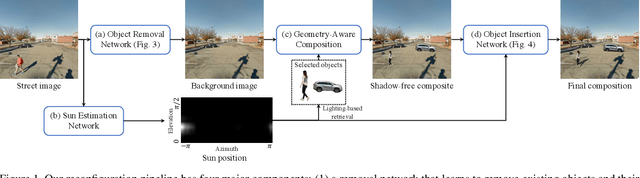
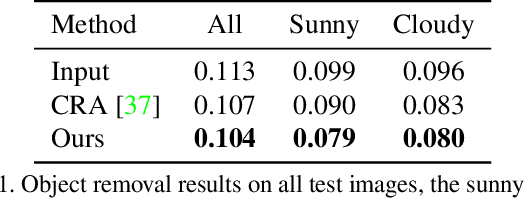

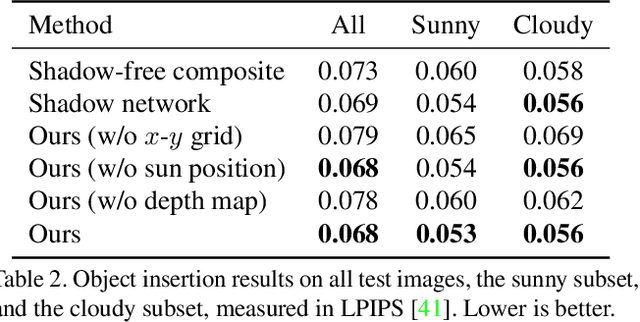
We present a framework for automatically reconfiguring images of street scenes by populating, depopulating, or repopulating them with objects such as pedestrians or vehicles. Applications of this method include anonymizing images to enhance privacy, generating data augmentations for perception tasks like autonomous driving, and composing scenes to achieve a certain ambiance, such as empty streets in the early morning. At a technical level, our work has three primary contributions: (1) a method for clearing images of objects, (2) a method for estimating sun direction from a single image, and (3) a way to compose objects in scenes that respects scene geometry and illumination. Each component is learned from data with minimal ground truth annotations, by making creative use of large-numbers of short image bursts of street scenes. We demonstrate convincing results on a range of street scenes and illustrate potential applications.