 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEye2Eye: A Simple Approach for Monocular-to-Stereo Video Synthesis
Apr 30, 2025The rising popularity of immersive visual experiences has increased interest in stereoscopic 3D video generation. Despite significant advances in video synthesis, creating 3D videos remains challenging due to the relative scarcity of 3D video data. We propose a simple approach for transforming a text-to-video generator into a video-to-stereo generator. Given an input video, our framework automatically produces the video frames from a shifted viewpoint, enabling a compelling 3D effect. Prior and concurrent approaches for this task typically operate in multiple phases, first estimating video disparity or depth, then warping the video accordingly to produce a second view, and finally inpainting the disoccluded regions. This approach inherently fails when the scene involves specular surfaces or transparent objects. In such cases, single-layer disparity estimation is insufficient, resulting in artifacts and incorrect pixel shifts during warping. Our work bypasses these restrictions by directly synthesizing the new viewpoint, avoiding any intermediate steps. This is achieved by leveraging a pre-trained video model's priors on geometry, object materials, optics, and semantics, without relying on external geometry models or manually disentangling geometry from the synthesis process. We demonstrate the advantages of our approach in complex, real-world scenarios featuring diverse object materials and compositions. See videos on https://video-eye2eye.github.io
Generative Omnimatte: Learning to Decompose Video into Layers
Nov 25, 2024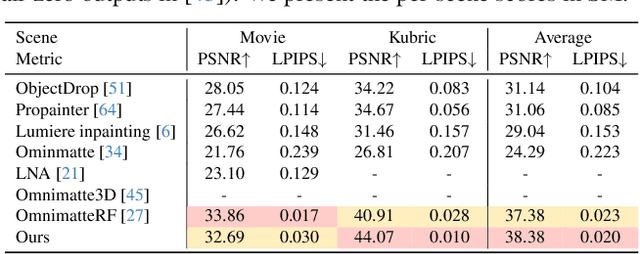



Given a video and a set of input object masks, an omnimatte method aims to decompose the video into semantically meaningful layers containing individual objects along with their associated effects, such as shadows and reflections. Existing omnimatte methods assume a static background or accurate pose and depth estimation and produce poor decompositions when these assumptions are violated. Furthermore, due to the lack of generative prior on natural videos, existing methods cannot complete dynamic occluded regions. We present a novel generative layered video decomposition framework to address the omnimatte problem. Our method does not assume a stationary scene or require camera pose or depth information and produces clean, complete layers, including convincing completions of occluded dynamic regions. Our core idea is to train a video diffusion model to identify and remove scene effects caused by a specific object. We show that this model can be finetuned from an existing video inpainting model with a small, carefully curated dataset, and demonstrate high-quality decompositions and editing results for a wide range of casually captured videos containing soft shadows, glossy reflections, splashing water, and more.
TokenFlow: Consistent Diffusion Features for Consistent Video Editing
Jul 23, 2023
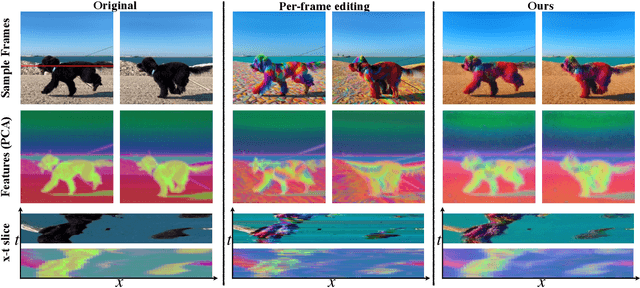

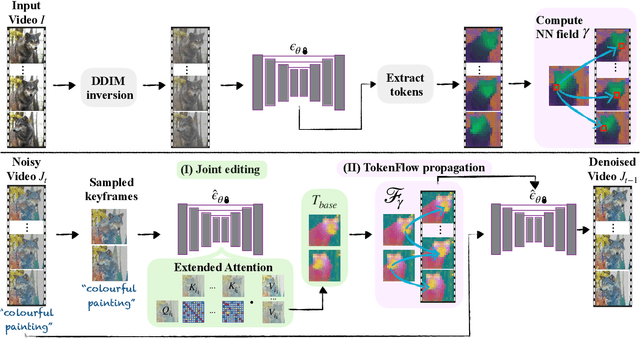
The generative AI revolution has recently expanded to videos. Nevertheless, current state-of-the-art video models are still lagging behind image models in terms of visual quality and user control over the generated content. In this work, we present a framework that harnesses the power of a text-to-image diffusion model for the task of text-driven video editing. Specifically, given a source video and a target text-prompt, our method generates a high-quality video that adheres to the target text, while preserving the spatial layout and motion of the input video. Our method is based on a key observation that consistency in the edited video can be obtained by enforcing consistency in the diffusion feature space. We achieve this by explicitly propagating diffusion features based on inter-frame correspondences, readily available in the model. Thus, our framework does not require any training or fine-tuning, and can work in conjunction with any off-the-shelf text-to-image editing method. We demonstrate state-of-the-art editing results on a variety of real-world videos. Webpage: https://diffusion-tokenflow.github.io/
Neural Congealing: Aligning Images to a Joint Semantic Atlas
Feb 08, 2023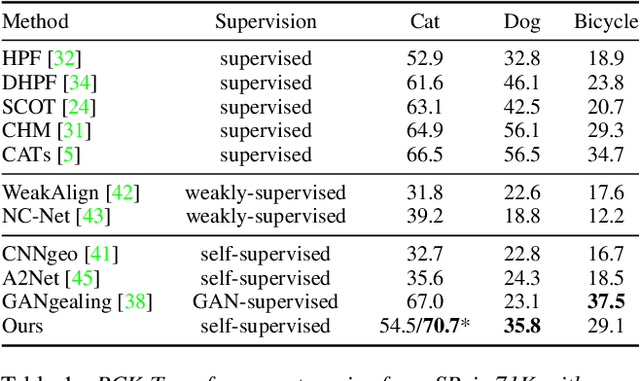
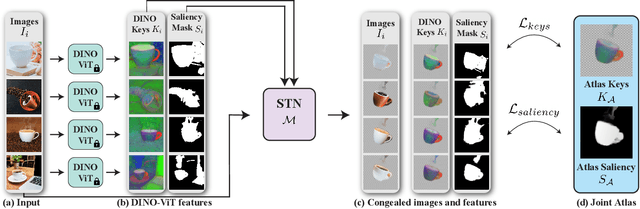

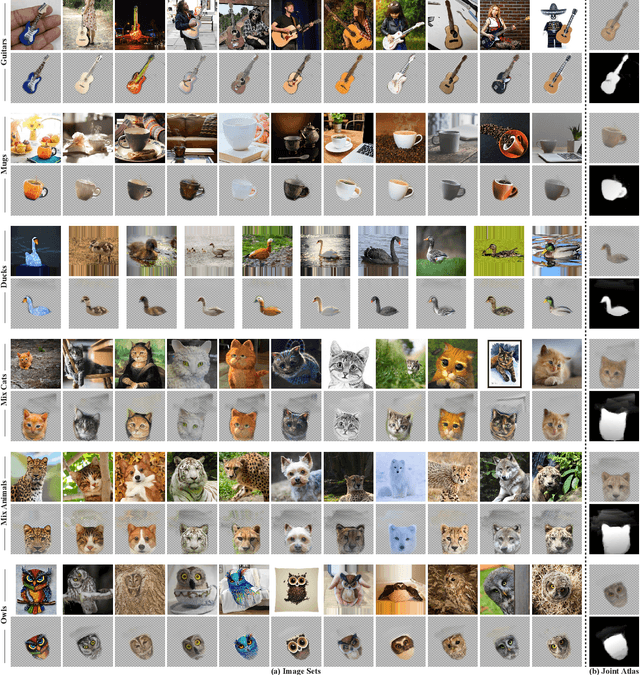
We present Neural Congealing -- a zero-shot self-supervised framework for detecting and jointly aligning semantically-common content across a given set of images. Our approach harnesses the power of pre-trained DINO-ViT features to learn: (i) a joint semantic atlas -- a 2D grid that captures the mode of DINO-ViT features in the input set, and (ii) dense mappings from the unified atlas to each of the input images. We derive a new robust self-supervised framework that optimizes the atlas representation and mappings per image set, requiring only a few real-world images as input without any additional input information (e.g., segmentation masks). Notably, we design our losses and training paradigm to account only for the shared content under severe variations in appearance, pose, background clutter or other distracting objects. We demonstrate results on a plethora of challenging image sets including sets of mixed domains (e.g., aligning images depicting sculpture and artwork of cats), sets depicting related yet different object categories (e.g., dogs and tigers), or domains for which large-scale training data is scarce (e.g., coffee mugs). We thoroughly evaluate our method and show that our test-time optimization approach performs favorably compared to a state-of-the-art method that requires extensive training on large-scale datasets.
Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation
Nov 22, 2022Large-scale text-to-image generative models have been a revolutionary breakthrough in the evolution of generative AI, allowing us to synthesize diverse images that convey highly complex visual concepts. However, a pivotal challenge in leveraging such models for real-world content creation tasks is providing users with control over the generated content. In this paper, we present a new framework that takes text-to-image synthesis to the realm of image-to-image translation -- given a guidance image and a target text prompt, our method harnesses the power of a pre-trained text-to-image diffusion model to generate a new image that complies with the target text, while preserving the semantic layout of the source image. Specifically, we observe and empirically demonstrate that fine-grained control over the generated structure can be achieved by manipulating spatial features and their self-attention inside the model. This results in a simple and effective approach, where features extracted from the guidance image are directly injected into the generation process of the target image, requiring no training or fine-tuning and applicable for both real or generated guidance images. We demonstrate high-quality results on versatile text-guided image translation tasks, including translating sketches, rough drawings and animations into realistic images, changing of the class and appearance of objects in a given image, and modifications of global qualities such as lighting and color.
Minimum Description Length Recurrent Neural Networks
Oct 31, 2021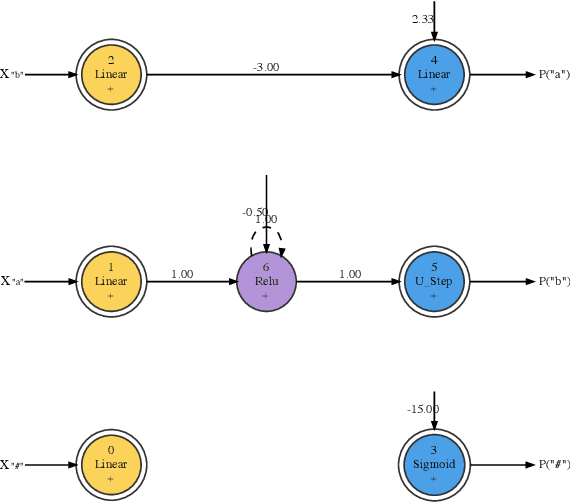

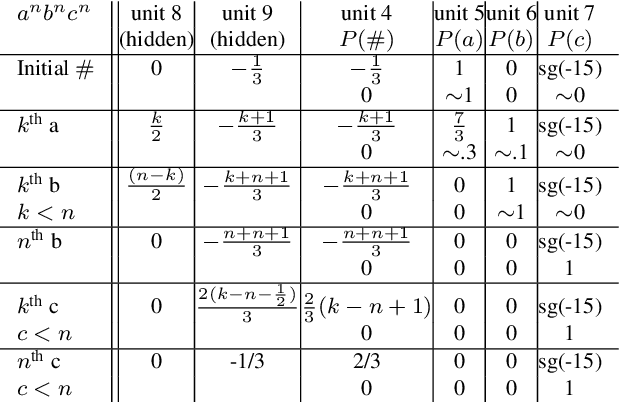
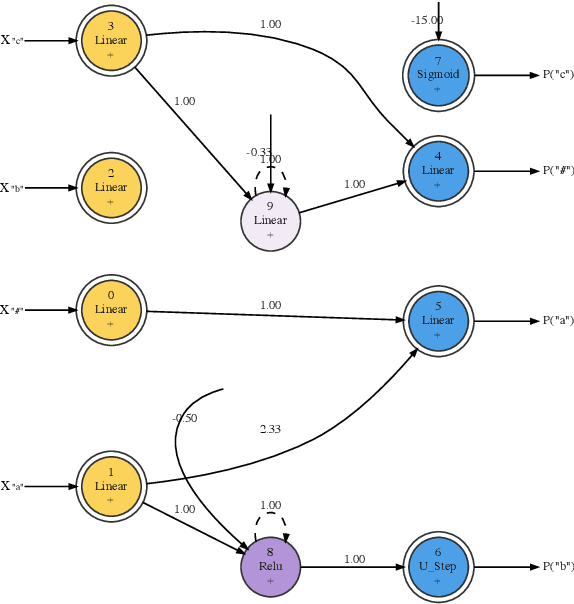
We train neural networks to optimize a Minimum Description Length score, i.e., to balance between the complexity of the network and its accuracy at a task. We show that networks trained with this objective function master tasks involving memory challenges such as counting, including cases that go beyond context-free languages. These learners master grammars for, e.g., $a^nb^n$, $a^nb^nc^n$, $a^nb^{2n}$, and $a^nb^mc^{n+m}$, and they perform addition. They do so with 100% accuracy, sometimes also with 100% confidence. The networks are also small and their inner workings are transparent. We thus provide formal proofs that their perfect accuracy holds not only on a given test set, but for any input sequence.