 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraZoom: Generating Gigapixel Images from Regular Photos
Jun 16, 2025We present UltraZoom, a system for generating gigapixel-resolution images of objects from casually captured inputs, such as handheld phone photos. Given a full-shot image (global, low-detail) and one or more close-ups (local, high-detail), UltraZoom upscales the full image to match the fine detail and scale of the close-up examples. To achieve this, we construct a per-instance paired dataset from the close-ups and adapt a pretrained generative model to learn object-specific low-to-high resolution mappings. At inference, we apply the model in a sliding window fashion over the full image. Constructing these pairs is non-trivial: it requires registering the close-ups within the full image for scale estimation and degradation alignment. We introduce a simple, robust method for getting registration on arbitrary materials in casual, in-the-wild captures. Together, these components form a system that enables seamless pan and zoom across the entire object, producing consistent, photorealistic gigapixel imagery from minimal input.
VidPanos: Generative Panoramic Videos from Casual Panning Videos
Oct 17, 2024
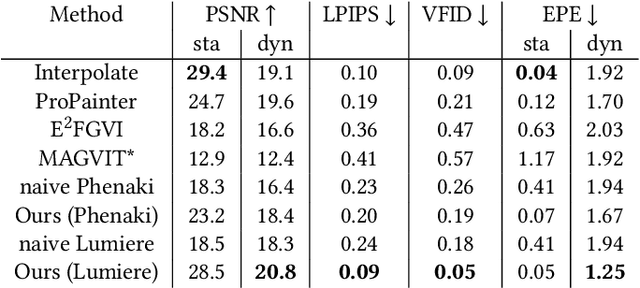
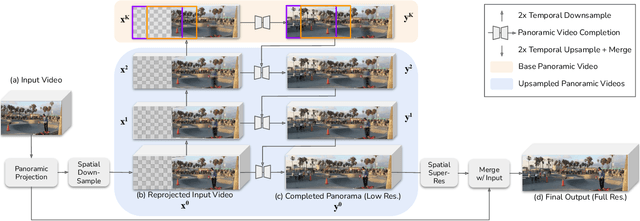
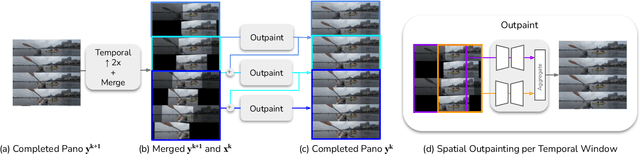
Panoramic image stitching provides a unified, wide-angle view of a scene that extends beyond the camera's field of view. Stitching frames of a panning video into a panoramic photograph is a well-understood problem for stationary scenes, but when objects are moving, a still panorama cannot capture the scene. We present a method for synthesizing a panoramic video from a casually-captured panning video, as if the original video were captured with a wide-angle camera. We pose panorama synthesis as a space-time outpainting problem, where we aim to create a full panoramic video of the same length as the input video. Consistent completion of the space-time volume requires a powerful, realistic prior over video content and motion, for which we adapt generative video models. Existing generative models do not, however, immediately extend to panorama completion, as we show. We instead apply video generation as a component of our panorama synthesis system, and demonstrate how to exploit the strengths of the models while minimizing their limitations. Our system can create video panoramas for a range of in-the-wild scenes including people, vehicles, and flowing water, as well as stationary background features.
Totems: Physical Objects for Verifying Visual Integrity
Sep 26, 2022
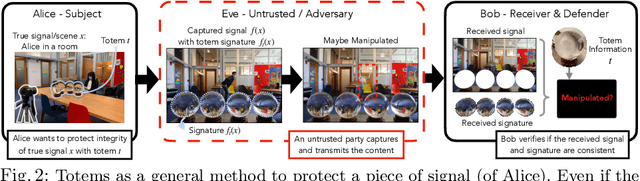


We introduce a new approach to image forensics: placing physical refractive objects, which we call totems, into a scene so as to protect any photograph taken of that scene. Totems bend and redirect light rays, thus providing multiple, albeit distorted, views of the scene within a single image. A defender can use these distorted totem pixels to detect if an image has been manipulated. Our approach unscrambles the light rays passing through the totems by estimating their positions in the scene and using their known geometric and material properties. To verify a totem-protected image, we detect inconsistencies between the scene reconstructed from totem viewpoints and the scene's appearance from the camera viewpoint. Such an approach makes the adversarial manipulation task more difficult, as the adversary must modify both the totem and image pixels in a geometrically consistent manner without knowing the physical properties of the totem. Unlike prior learning-based approaches, our method does not require training on datasets of specific manipulations, and instead uses physical properties of the scene and camera to solve the forensics problem.
A Unified Model for Recommendation with Selective Neighborhood Modeling
Oct 19, 2020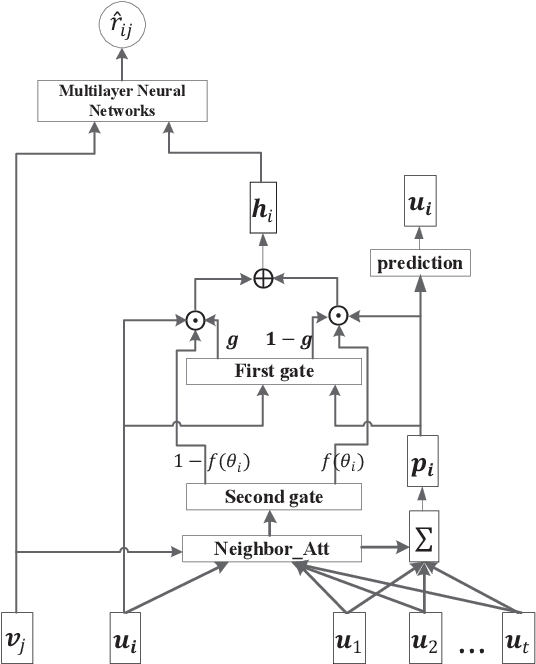
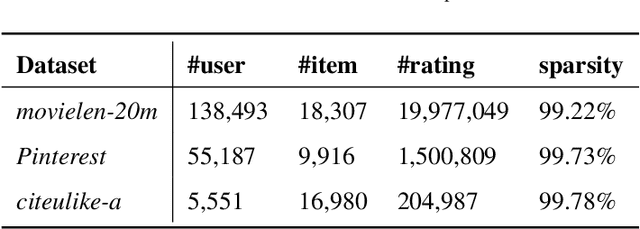
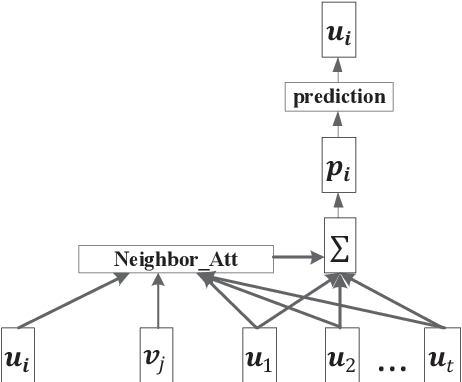
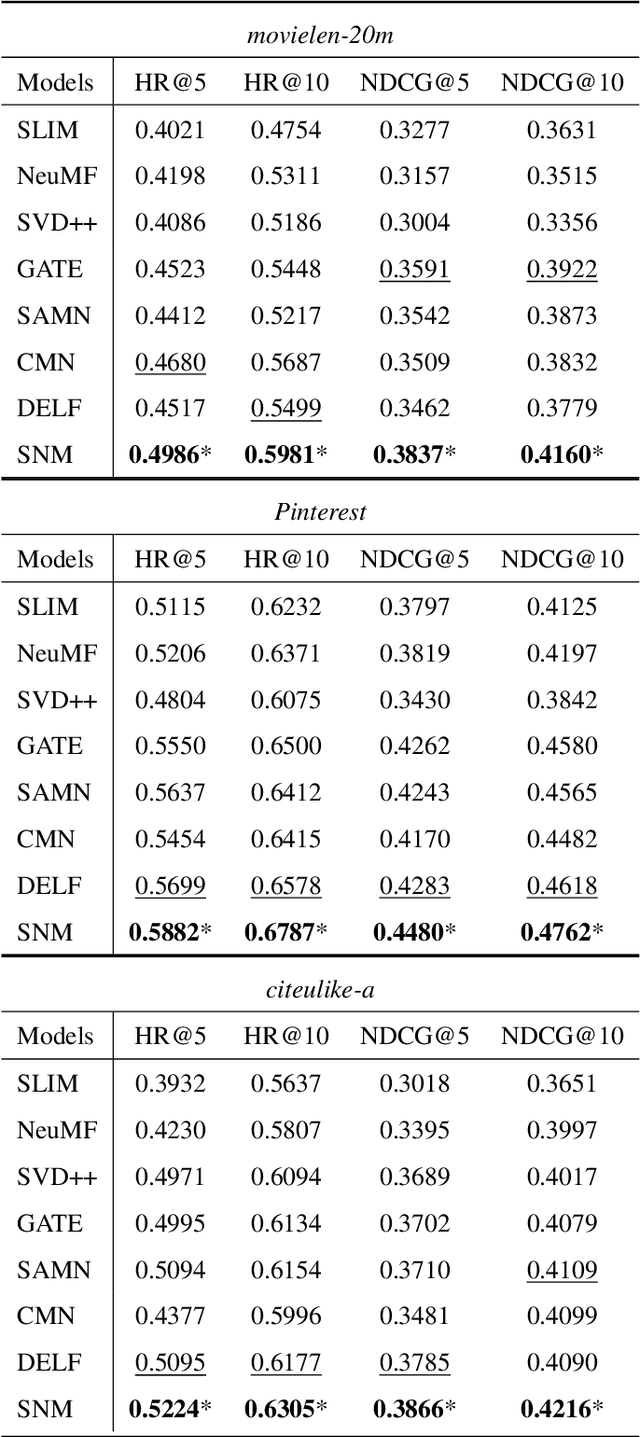
Neighborhood-based recommenders are a major class of Collaborative Filtering (CF) models. The intuition is to exploit neighbors with similar preferences for bridging unseen user-item pairs and alleviating data sparseness. Many existing works propose neural attention networks to aggregate neighbors and place higher weights on specific subsets of users for recommendation. However, the neighborhood information is not necessarily always informative, and the noises in the neighborhood can negatively affect the model performance. To address this issue, we propose a novel neighborhood-based recommender, where a hybrid gated network is designed to automatically separate similar neighbors from dissimilar (noisy) ones, and aggregate those similar neighbors to comprise neighborhood representations. The confidence in the neighborhood is also addressed by putting higher weights on the neighborhood representations if we are confident with the neighborhood information, and vice versa. In addition, a user-neighbor component is proposed to explicitly regularize user-neighbor proximity in the latent space. These two components are combined into a unified model to complement each other for the recommendation task. Extensive experiments on three publicly available datasets show that the proposed model consistently outperforms state-of-the-art neighborhood-based recommenders. We also study different variants of the proposed model to justify the underlying intuition of the proposed hybrid gated network and user-neighbor modeling components.
Hierarchical Text Interaction for Rating Prediction
Oct 15, 2020
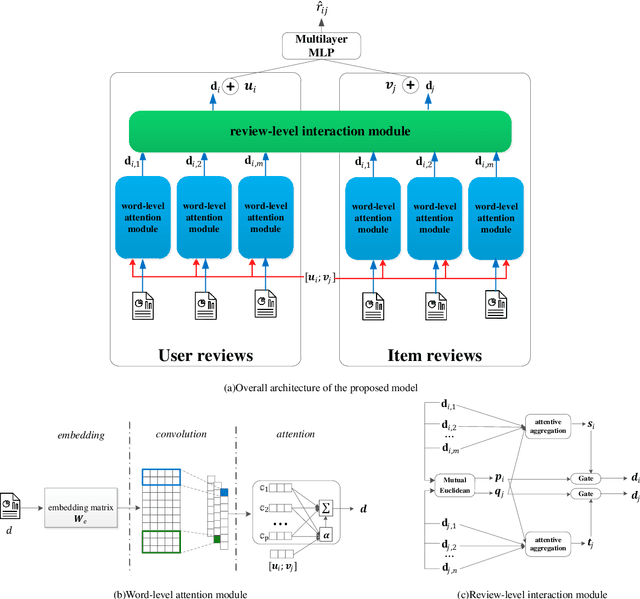
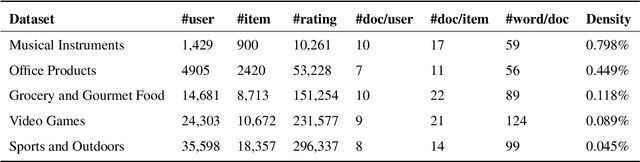

Traditional recommender systems encounter several challenges such as data sparsity and unexplained recommendation. To address these challenges, many works propose to exploit semantic information from review data. However, these methods have two major limitations in terms of the way to model textual features and capture textual interaction. For textual modeling, they simply concatenate all the reviews of a user/item into a single review. However, feature extraction at word/phrase level can violate the meaning of the original reviews. As for textual interaction, they defer the interactions to the prediction layer, making them fail to capture complex correlations between users and items. To address those limitations, we propose a novel Hierarchical Text Interaction model(HTI) for rating prediction. In HTI, we propose to model low-level word semantics and high-level review representations hierarchically. The hierarchy allows us to exploit textual features at different granularities. To further capture complex user-item interactions, we propose to exploit semantic correlations between each user-item pair at different hierarchies. At word level, we propose an attention mechanism specialized to each user-item pair, and capture the important words for representing each review. At review level, we mutually propagate textual features between the user and item, and capture the informative reviews. The aggregated review representations are integrated into a collaborative filtering framework for rating prediction. Experiments on five real-world datasets demonstrate that HTI outperforms state-of-the-art models by a large margin. Further case studies provide a deep insight into HTI's ability to capture semantic correlations at different levels of granularities for rating prediction.
DBRec: Dual-Bridging Recommendation via Discovering Latent Groups
Oct 16, 2019
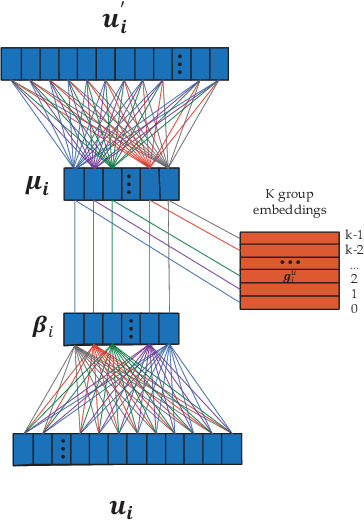
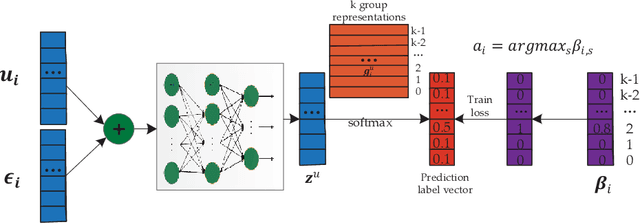
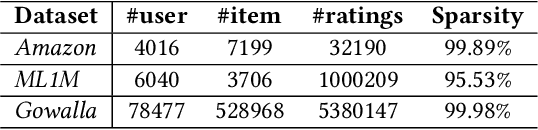
In recommender systems, the user-item interaction data is usually sparse and not sufficient for learning comprehensive user/item representations for recommendation. To address this problem, we propose a novel dual-bridging recommendation model (DBRec). DBRec performs latent user/item group discovery simultaneously with collaborative filtering, and interacts group information with users/items for bridging similar users/items. Therefore, a user's preference over an unobserved item, in DBRec, can be bridged by the users within the same group who have rated the item, or the user-rated items that share the same group with the unobserved item. In addition, we propose to jointly learn user-user group (item-item group) hierarchies, so that we can effectively discover latent groups and learn compact user/item representations. We jointly integrate collaborative filtering, latent group discovering and hierarchical modelling into a unified framework, so that all the model parameters can be learned toward the optimization of the objective function. We validate the effectiveness of the proposed model with two real datasets, and demonstrate its advantage over the state-of-the-art recommendation models with extensive experiments.