 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bias-Free Training Paradigm for More General AI-generated Image Detection
Dec 23, 2024Successful forensic detectors can produce excellent results in supervised learning benchmarks but struggle to transfer to real-world applications. We believe this limitation is largely due to inadequate training data quality. While most research focuses on developing new algorithms, less attention is given to training data selection, despite evidence that performance can be strongly impacted by spurious correlations such as content, format, or resolution. A well-designed forensic detector should detect generator specific artifacts rather than reflect data biases. To this end, we propose B-Free, a bias-free training paradigm, where fake images are generated from real ones using the conditioning procedure of stable diffusion models. This ensures semantic alignment between real and fake images, allowing any differences to stem solely from the subtle artifacts introduced by AI generation. Through content-based augmentation, we show significant improvements in both generalization and robustness over state-of-the-art detectors and more calibrated results across 27 different generative models, including recent releases, like FLUX and Stable Diffusion 3.5. Our findings emphasize the importance of a careful dataset curation, highlighting the need for further research in dataset design. Code and data will be publicly available at https://grip-unina.github.io/B-Free/
FakeInversion: Learning to Detect Images from Unseen Text-to-Image Models by Inverting Stable Diffusion
Jun 12, 2024Due to the high potential for abuse of GenAI systems, the task of detecting synthetic images has recently become of great interest to the research community. Unfortunately, existing image-space detectors quickly become obsolete as new high-fidelity text-to-image models are developed at blinding speed. In this work, we propose a new synthetic image detector that uses features obtained by inverting an open-source pre-trained Stable Diffusion model. We show that these inversion features enable our detector to generalize well to unseen generators of high visual fidelity (e.g., DALL-E 3) even when the detector is trained only on lower fidelity fake images generated via Stable Diffusion. This detector achieves new state-of-the-art across multiple training and evaluation setups. Moreover, we introduce a new challenging evaluation protocol that uses reverse image search to mitigate stylistic and thematic biases in the detector evaluation. We show that the resulting evaluation scores align well with detectors' in-the-wild performance, and release these datasets as public benchmarks for future research.
* Project page: https://fake-inversion.github.io
Towards Practical Non-Adversarial Distribution Alignment via Variational Bounds
Oct 30, 2023Distribution alignment can be used to learn invariant representations with applications in fairness and robustness. Most prior works resort to adversarial alignment methods but the resulting minimax problems are unstable and challenging to optimize. Non-adversarial likelihood-based approaches either require model invertibility, impose constraints on the latent prior, or lack a generic framework for alignment. To overcome these limitations, we propose a non-adversarial VAE-based alignment method that can be applied to any model pipeline. We develop a set of alignment upper bounds (including a noisy bound) that have VAE-like objectives but with a different perspective. We carefully compare our method to prior VAE-based alignment approaches both theoretically and empirically. Finally, we demonstrate that our novel alignment losses can replace adversarial losses in standard invariant representation learning pipelines without modifying the original architectures -- thereby significantly broadening the applicability of non-adversarial alignment methods.
Disentangled Unsupervised Image Translation via Restricted Information Flow
Nov 26, 2021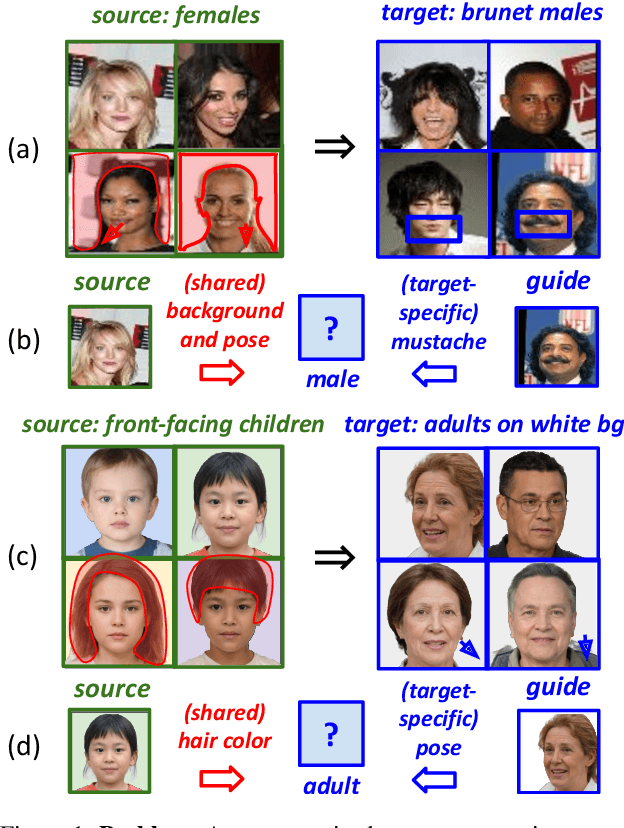
Unsupervised image-to-image translation methods aim to map images from one domain into plausible examples from another domain while preserving structures shared across two domains. In the many-to-many setting, an additional guidance example from the target domain is used to determine domain-specific attributes of the generated image. In the absence of attribute annotations, methods have to infer which factors are specific to each domain from data during training. Many state-of-art methods hard-code the desired shared-vs-specific split into their architecture, severely restricting the scope of the problem. In this paper, we propose a new method that does not rely on such inductive architectural biases, and infers which attributes are domain-specific from data by constraining information flow through the network using translation honesty losses and a penalty on the capacity of domain-specific embedding. We show that the proposed method achieves consistently high manipulation accuracy across two synthetic and one natural dataset spanning a wide variety of domain-specific and shared attributes.
MetaPose: Fast 3D Pose from Multiple Views without 3D Supervision
Aug 10, 2021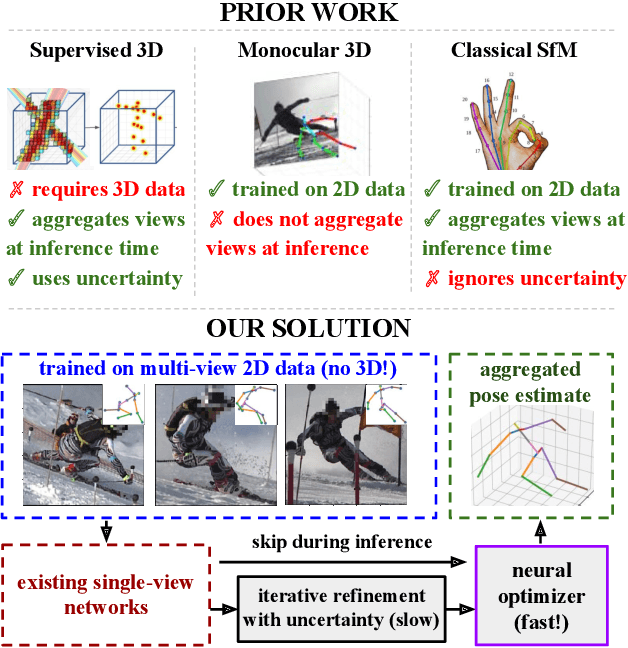
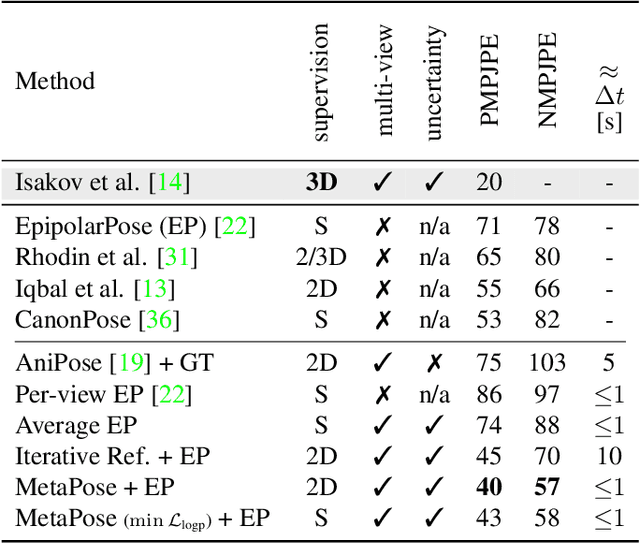
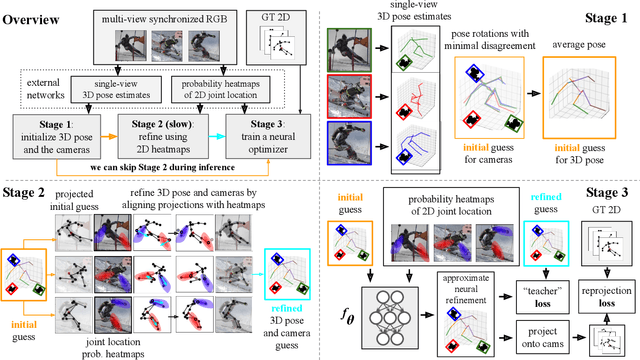

Recently, huge strides were made in monocular and multi-view pose estimation with known camera parameters, whereas pose estimation from multiple cameras with unknown positions and orientations received much less attention. In this paper, we show how to train a neural model that can perform accurate 3D pose and camera estimation, takes into account joint location uncertainty due occlusion from multiple views, and requires only 2D keypoint data for training. Our method outperforms both classical bundle adjustment and weakly-supervised monocular 3D baselines on the well-established Human3.6M dataset, as well as the more challenging in-the-wild Ski-Pose PTZ dataset with moving cameras. We provide an extensive ablation study separating the error due to the camera model, number of cameras, initialization, and image-space joint localization from the additional error introduced by our model.
VisDA-2021 Competition Universal Domain Adaptation to Improve Performance on Out-of-Distribution Data
Jul 23, 2021
Progress in machine learning is typically measured by training and testing a model on the same distribution of data, i.e., the same domain. This over-estimates future accuracy on out-of-distribution data. The Visual Domain Adaptation (VisDA) 2021 competition tests models' ability to adapt to novel test distributions and handle distributional shift. We set up unsupervised domain adaptation challenges for image classifiers and will evaluate adaptation to novel viewpoints, backgrounds, modalities and degradation in quality. Our challenge draws on large-scale publicly available datasets but constructs the evaluation across domains, rather that the traditional in-domain bench-marking. Furthermore, we focus on the difficult "universal" setting where, in addition to input distribution drift, methods may encounter missing and/or novel classes in the target dataset. Performance will be measured using a rigorous protocol, comparing to state-of-the-art domain adaptation methods with the help of established metrics. We believe that the competition will encourage further improvement in machine learning methods' ability to handle realistic data in many deployment scenarios.
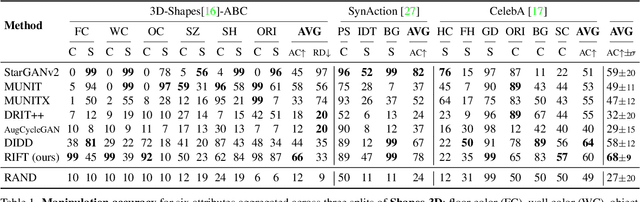
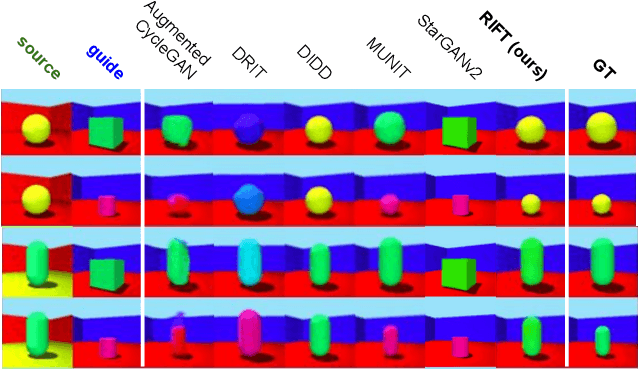
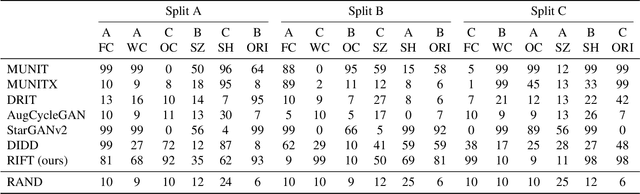
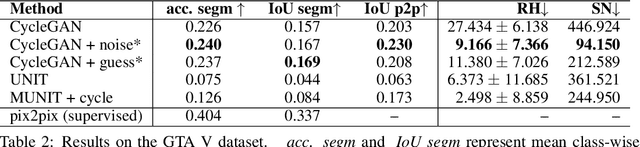
Evaluation of Correctness in Unsupervised Many-to-Many Image Translation
Mar 29, 2021

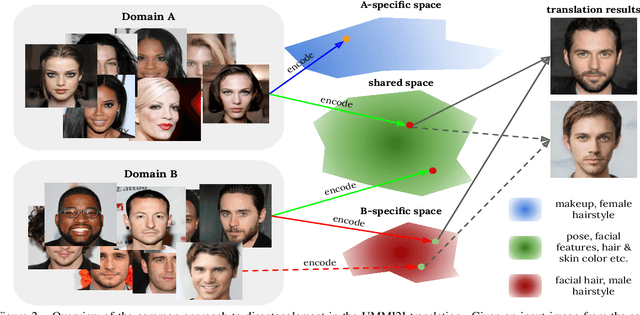
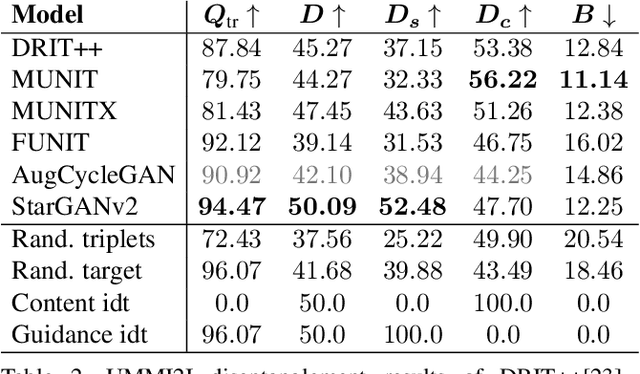
Given an input image from a source domain and a "guidance" image from a target domain, unsupervised many-to-many image-to-image (UMMI2I) translation methods seek to generate a plausible example from the target domain that preserves domain-invariant information of the input source image and inherits the domain-specific information from the guidance image. For example, when translating female faces to male faces, the generated male face should have the same expression, pose and hair color as the input female image, and the same facial hairstyle and other male-specific attributes as the guidance male image. Current state-of-the art UMMI2I methods generate visually pleasing images, but, since for most pairs of real datasets we do not know which attributes are domain-specific and which are domain-invariant, the semantic correctness of existing approaches has not been quantitatively evaluated yet. In this paper, we propose a set of benchmarks and metrics for the evaluation of semantic correctness of UMMI2I methods. We provide an extensive study how well the existing state-of-the-art UMMI2I translation methods preserve domain-invariant and manipulate domain-specific attributes, and discuss the trade-offs shared by all methods, as well as how different architectural choices affect various aspects of semantic correctness.
Log-Likelihood Ratio Minimizing Flows: Towards Robust and Quantifiable Neural Distribution Alignment
Mar 26, 2020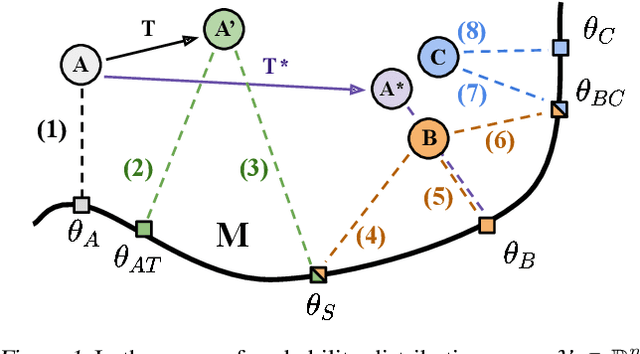
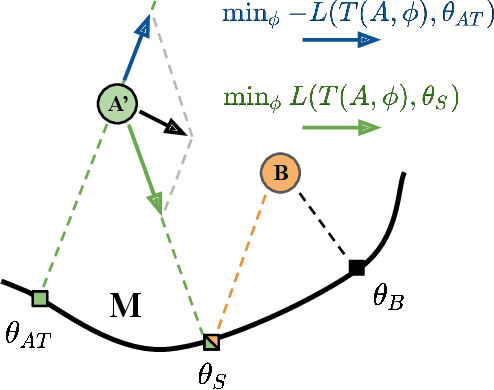

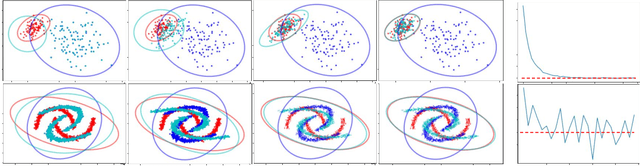
Unsupervised distribution alignment has many applications in deep learning, including domain adaptation and unsupervised image-to-image translation. Most prior work on unsupervised distribution alignment relies either on minimizing simple non-parametric statistical distances such as maximum mean discrepancy, or on adversarial alignment. However, the former fails to capture the structure of complex real-world distributions, while the latter is difficult to train and does not provide any universal convergence guarantees or automatic quantitative validation procedures. In this paper we propose a new distribution alignment method based on a log-likelihood ratio statistic and normalizing flows. We show that, under certain assumptions, this combination yields a deep neural likelihood-based minimization objective that attains a known lower bound upon convergence. We experimentally verify that minimizing the resulting objective results in domain alignment that preserves the local structure of input domains.
Adversarial Self-Defense for Cycle-Consistent GANs
Aug 05, 2019


The goal of unsupervised image-to-image translation is to map images from one domain to another without the ground truth correspondence between the two domains. State-of-art methods learn the correspondence using large numbers of unpaired examples from both domains and are based on generative adversarial networks. In order to preserve the semantics of the input image, the adversarial objective is usually combined with a cycle-consistency loss that penalizes incorrect reconstruction of the input image from the translated one. However, if the target mapping is many-to-one, e.g. aerial photos to maps, such a restriction forces the generator to hide information in low-amplitude structured noise that is undetectable by human eye or by the discriminator. In this paper, we show how such self-attacking behavior of unsupervised translation methods affects their performance and provide two defense techniques. We perform a quantitative evaluation of the proposed techniques and show that making the translation model more robust to the self-adversarial attack increases its generation quality and reconstruction reliability and makes the model less sensitive to low-amplitude perturbations.
PuppetGAN: Transferring Disentangled Properties from Synthetic to Real Images
Jan 28, 2019
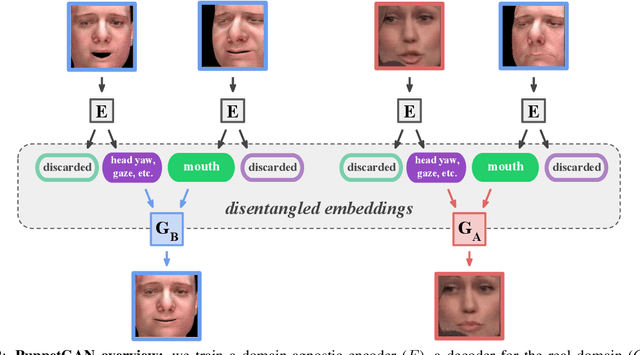
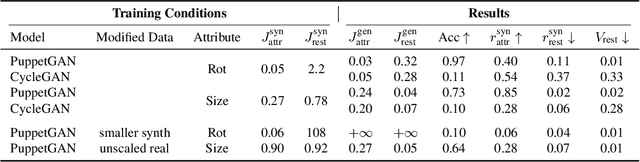
In this work we propose a model that enables controlled manipulation of visual attributes of real "target" images (e.g. lighting, expression or pose) using only implicit supervision with synthetic "source" exemplars. Specifically, our model learns a shared low-dimensional representation of input images from both domains in which a property of interest is isolated from other content features of the input. By using triplets of synthetic images that demonstrate modification of the visual property that we would like to control (for example mouth opening) we are able to perform disentanglement of image representations with respect to this property without using explicit attribute labels in either domain. Since our technique relies on triplets instead of explicit labels, it can be applied to shape, texture, lighting, or other properties that are difficult to measure or represent as explicit conditioners. We quantitatively analyze the degree to which trained models learn to isolate the property of interest from other content features with a proof-of-concept digit dataset and demonstrate results in a far more difficult setting, learning to manipulate real faces using a synthetic 3D faces dataset. We also explore limitations of our model with respect to differences in distributions of properties observed in two domains.