 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLipSync3D: Data-Efficient Learning of Personalized 3D Talking Faces from Video using Pose and Lighting Normalization
Jun 08, 2021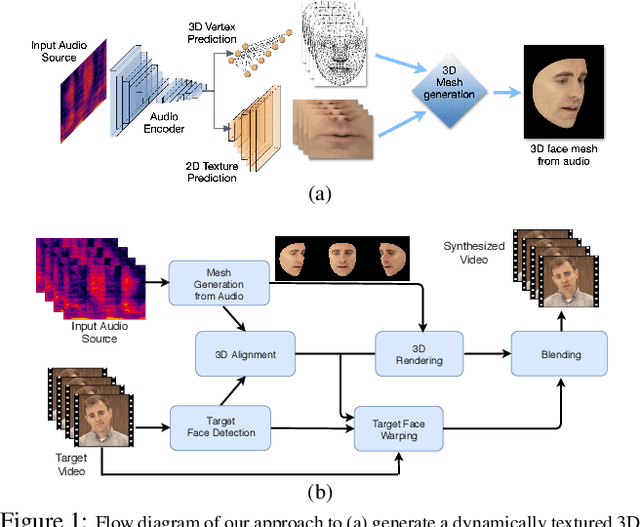
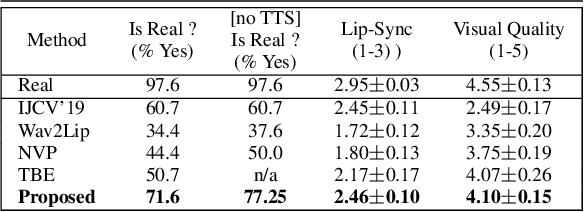
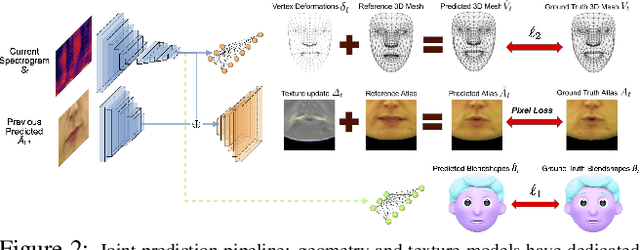

In this paper, we present a video-based learning framework for animating personalized 3D talking faces from audio. We introduce two training-time data normalizations that significantly improve data sample efficiency. First, we isolate and represent faces in a normalized space that decouples 3D geometry, head pose, and texture. This decomposes the prediction problem into regressions over the 3D face shape and the corresponding 2D texture atlas. Second, we leverage facial symmetry and approximate albedo constancy of skin to isolate and remove spatio-temporal lighting variations. Together, these normalizations allow simple networks to generate high fidelity lip-sync videos under novel ambient illumination while training with just a single speaker-specific video. Further, to stabilize temporal dynamics, we introduce an auto-regressive approach that conditions the model on its previous visual state. Human ratings and objective metrics demonstrate that our method outperforms contemporary state-of-the-art audio-driven video reenactment benchmarks in terms of realism, lip-sync and visual quality scores. We illustrate several applications enabled by our framework.
PuppetGAN: Transferring Disentangled Properties from Synthetic to Real Images
Jan 28, 2019
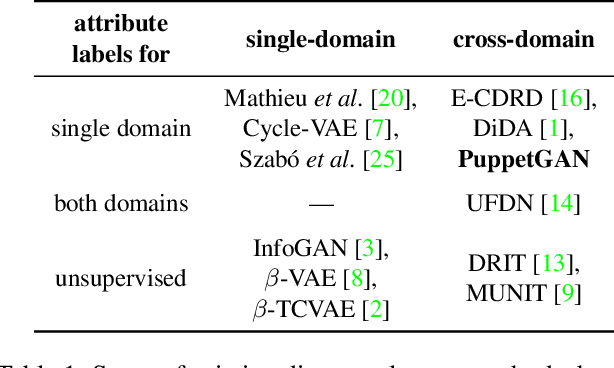
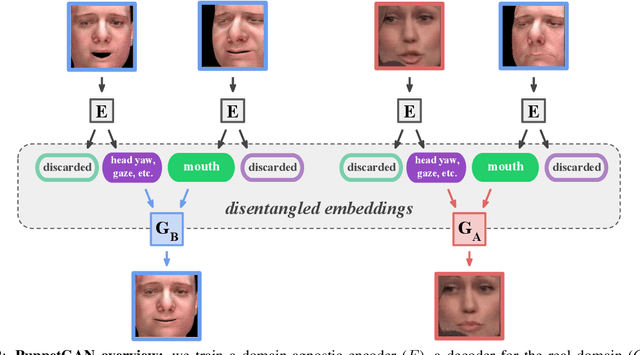
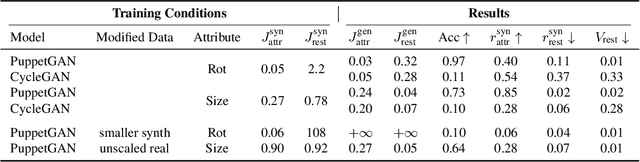
In this work we propose a model that enables controlled manipulation of visual attributes of real "target" images (e.g. lighting, expression or pose) using only implicit supervision with synthetic "source" exemplars. Specifically, our model learns a shared low-dimensional representation of input images from both domains in which a property of interest is isolated from other content features of the input. By using triplets of synthetic images that demonstrate modification of the visual property that we would like to control (for example mouth opening) we are able to perform disentanglement of image representations with respect to this property without using explicit attribute labels in either domain. Since our technique relies on triplets instead of explicit labels, it can be applied to shape, texture, lighting, or other properties that are difficult to measure or represent as explicit conditioners. We quantitatively analyze the degree to which trained models learn to isolate the property of interest from other content features with a proof-of-concept digit dataset and demonstrate results in a far more difficult setting, learning to manipulate real faces using a synthetic 3D faces dataset. We also explore limitations of our model with respect to differences in distributions of properties observed in two domains.
Towards Accurate Multi-person Pose Estimation in the Wild
Apr 14, 2017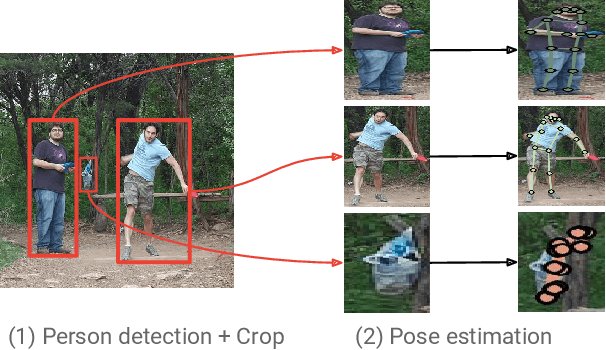



We propose a method for multi-person detection and 2-D pose estimation that achieves state-of-art results on the challenging COCO keypoints task. It is a simple, yet powerful, top-down approach consisting of two stages. In the first stage, we predict the location and scale of boxes which are likely to contain people; for this we use the Faster RCNN detector. In the second stage, we estimate the keypoints of the person potentially contained in each proposed bounding box. For each keypoint type we predict dense heatmaps and offsets using a fully convolutional ResNet. To combine these outputs we introduce a novel aggregation procedure to obtain highly localized keypoint predictions. We also use a novel form of keypoint-based Non-Maximum-Suppression (NMS), instead of the cruder box-level NMS, and a novel form of keypoint-based confidence score estimation, instead of box-level scoring. Trained on COCO data alone, our final system achieves average precision of 0.649 on the COCO test-dev set and the 0.643 test-standard sets, outperforming the winner of the 2016 COCO keypoints challenge and other recent state-of-art. Further, by using additional in-house labeled data we obtain an even higher average precision of 0.685 on the test-dev set and 0.673 on the test-standard set, more than 5% absolute improvement compared to the previous best performing method on the same dataset.