 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLog-Likelihood Ratio Minimizing Flows: Towards Robust and Quantifiable Neural Distribution Alignment
Mar 26, 2020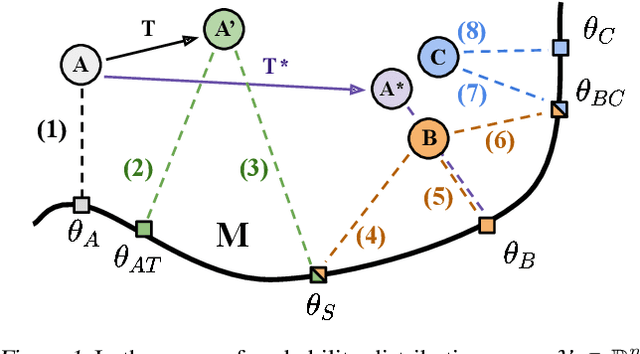
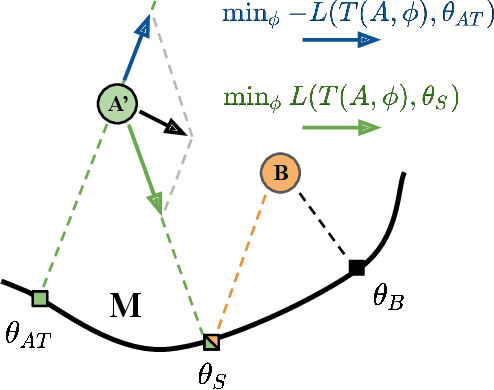

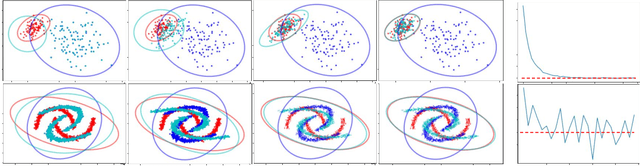
Unsupervised distribution alignment has many applications in deep learning, including domain adaptation and unsupervised image-to-image translation. Most prior work on unsupervised distribution alignment relies either on minimizing simple non-parametric statistical distances such as maximum mean discrepancy, or on adversarial alignment. However, the former fails to capture the structure of complex real-world distributions, while the latter is difficult to train and does not provide any universal convergence guarantees or automatic quantitative validation procedures. In this paper we propose a new distribution alignment method based on a log-likelihood ratio statistic and normalizing flows. We show that, under certain assumptions, this combination yields a deep neural likelihood-based minimization objective that attains a known lower bound upon convergence. We experimentally verify that minimizing the resulting objective results in domain alignment that preserves the local structure of input domains.
PuppetGAN: Transferring Disentangled Properties from Synthetic to Real Images
Jan 28, 2019
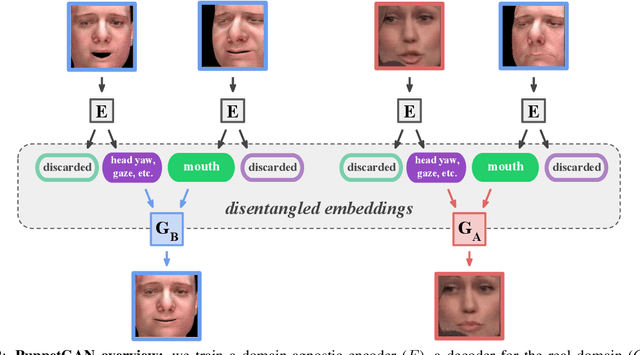
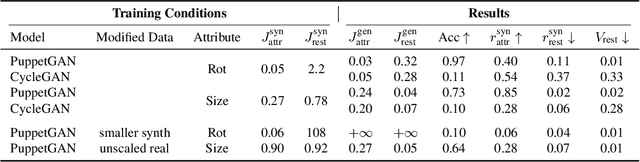
In this work we propose a model that enables controlled manipulation of visual attributes of real "target" images (e.g. lighting, expression or pose) using only implicit supervision with synthetic "source" exemplars. Specifically, our model learns a shared low-dimensional representation of input images from both domains in which a property of interest is isolated from other content features of the input. By using triplets of synthetic images that demonstrate modification of the visual property that we would like to control (for example mouth opening) we are able to perform disentanglement of image representations with respect to this property without using explicit attribute labels in either domain. Since our technique relies on triplets instead of explicit labels, it can be applied to shape, texture, lighting, or other properties that are difficult to measure or represent as explicit conditioners. We quantitatively analyze the degree to which trained models learn to isolate the property of interest from other content features with a proof-of-concept digit dataset and demonstrate results in a far more difficult setting, learning to manipulate real faces using a synthetic 3D faces dataset. We also explore limitations of our model with respect to differences in distributions of properties observed in two domains.
Eyemotion: Classifying facial expressions in VR using eye-tracking cameras
Jul 28, 2017
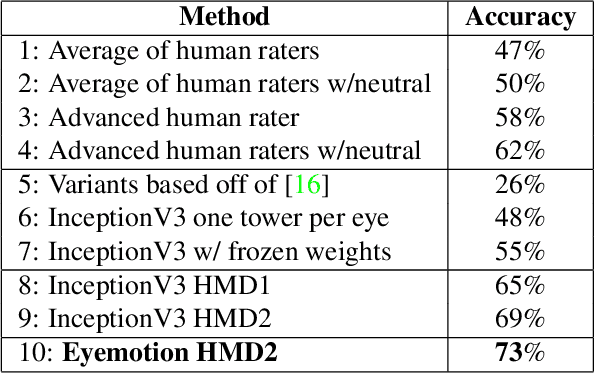
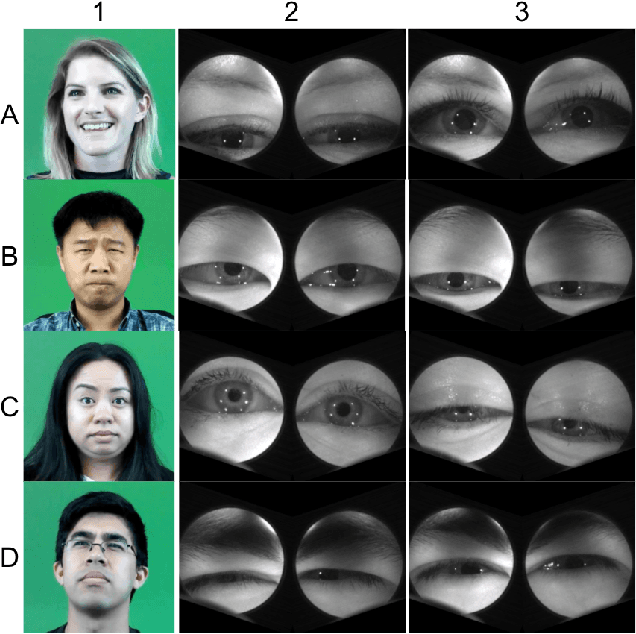
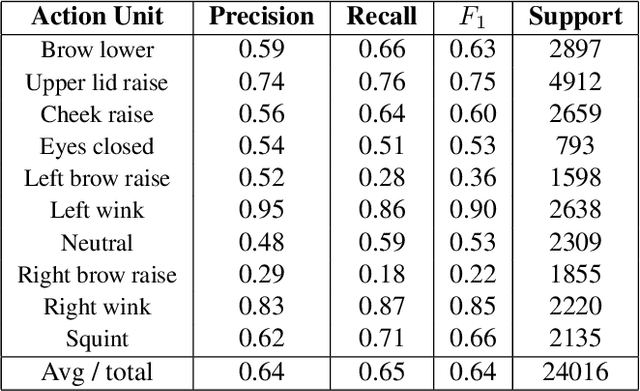
One of the main challenges of social interaction in virtual reality settings is that head-mounted displays occlude a large portion of the face, blocking facial expressions and thereby restricting social engagement cues among users. Hence, auxiliary means of sensing and conveying these expressions are needed. We present an algorithm to automatically infer expressions by analyzing only a partially occluded face while the user is engaged in a virtual reality experience. Specifically, we show that images of the user's eyes captured from an IR gaze-tracking camera within a VR headset are sufficient to infer a select subset of facial expressions without the use of any fixed external camera. Using these inferences, we can generate dynamic avatars in real-time which function as an expressive surrogate for the user. We propose a novel data collection pipeline as well as a novel approach for increasing CNN accuracy via personalization. Our results show a mean accuracy of 74% ($F1$ of 0.73) among 5 `emotive' expressions and a mean accuracy of 70% ($F1$ of 0.68) among 10 distinct facial action units, outperforming human raters.