 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLipSync3D: Data-Efficient Learning of Personalized 3D Talking Faces from Video using Pose and Lighting Normalization
Jun 08, 2021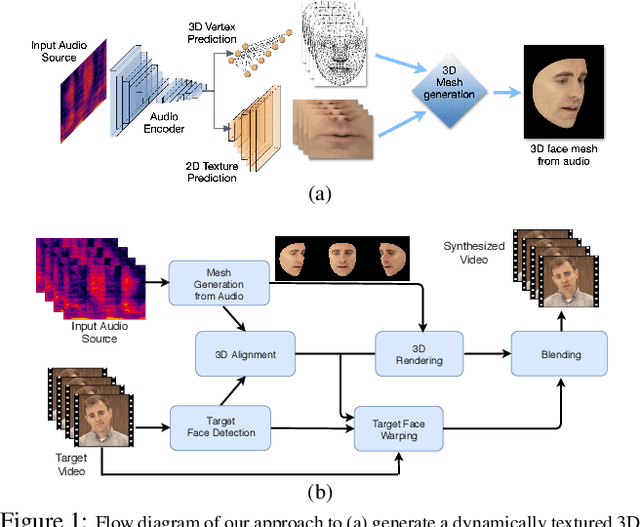
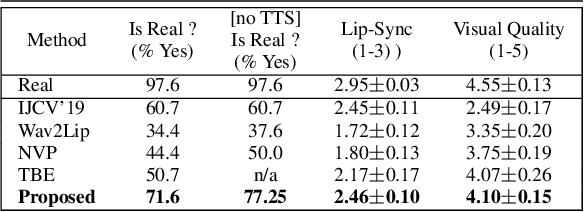
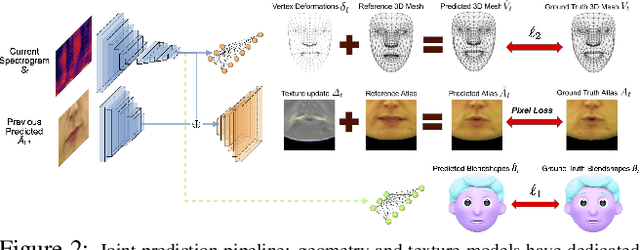

In this paper, we present a video-based learning framework for animating personalized 3D talking faces from audio. We introduce two training-time data normalizations that significantly improve data sample efficiency. First, we isolate and represent faces in a normalized space that decouples 3D geometry, head pose, and texture. This decomposes the prediction problem into regressions over the 3D face shape and the corresponding 2D texture atlas. Second, we leverage facial symmetry and approximate albedo constancy of skin to isolate and remove spatio-temporal lighting variations. Together, these normalizations allow simple networks to generate high fidelity lip-sync videos under novel ambient illumination while training with just a single speaker-specific video. Further, to stabilize temporal dynamics, we introduce an auto-regressive approach that conditions the model on its previous visual state. Human ratings and objective metrics demonstrate that our method outperforms contemporary state-of-the-art audio-driven video reenactment benchmarks in terms of realism, lip-sync and visual quality scores. We illustrate several applications enabled by our framework.
Eyemotion: Classifying facial expressions in VR using eye-tracking cameras
Jul 28, 2017
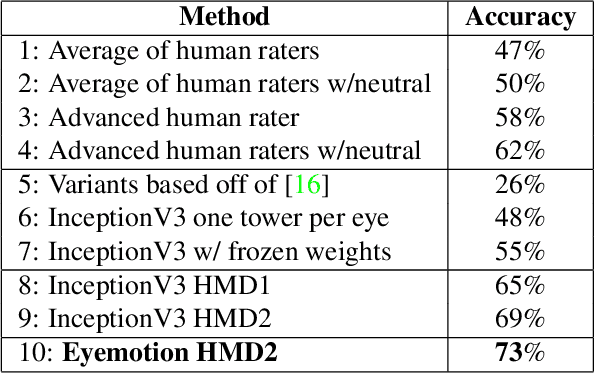
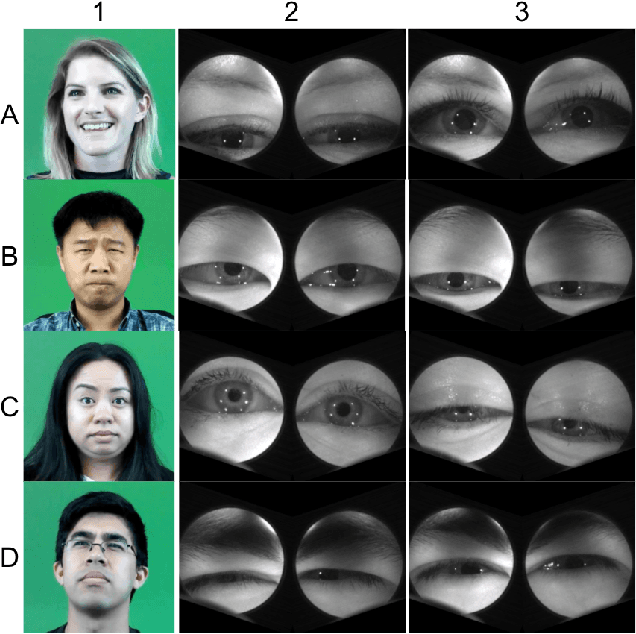
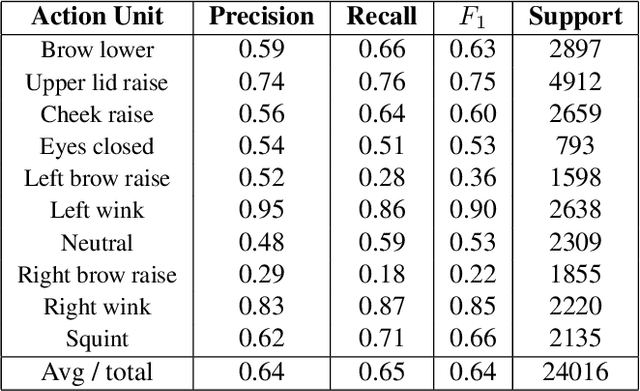
One of the main challenges of social interaction in virtual reality settings is that head-mounted displays occlude a large portion of the face, blocking facial expressions and thereby restricting social engagement cues among users. Hence, auxiliary means of sensing and conveying these expressions are needed. We present an algorithm to automatically infer expressions by analyzing only a partially occluded face while the user is engaged in a virtual reality experience. Specifically, we show that images of the user's eyes captured from an IR gaze-tracking camera within a VR headset are sufficient to infer a select subset of facial expressions without the use of any fixed external camera. Using these inferences, we can generate dynamic avatars in real-time which function as an expressive surrogate for the user. We propose a novel data collection pipeline as well as a novel approach for increasing CNN accuracy via personalization. Our results show a mean accuracy of 74% ($F1$ of 0.73) among 5 `emotive' expressions and a mean accuracy of 70% ($F1$ of 0.68) among 10 distinct facial action units, outperforming human raters.