 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Correctness in Unsupervised Many-to-Many Image Translation
Paper and Code
Mar 29, 2021

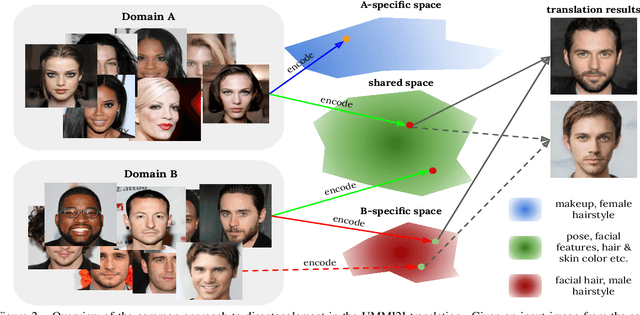
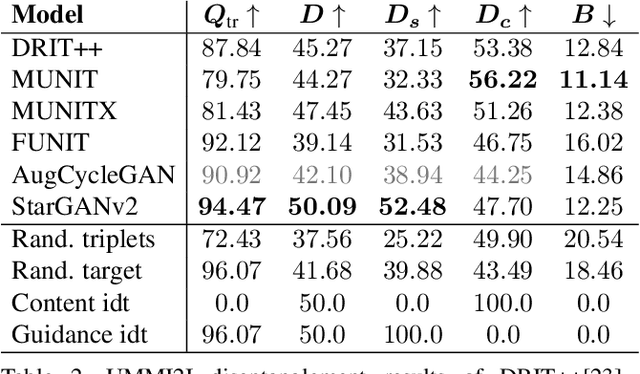
Given an input image from a source domain and a "guidance" image from a target domain, unsupervised many-to-many image-to-image (UMMI2I) translation methods seek to generate a plausible example from the target domain that preserves domain-invariant information of the input source image and inherits the domain-specific information from the guidance image. For example, when translating female faces to male faces, the generated male face should have the same expression, pose and hair color as the input female image, and the same facial hairstyle and other male-specific attributes as the guidance male image. Current state-of-the art UMMI2I methods generate visually pleasing images, but, since for most pairs of real datasets we do not know which attributes are domain-specific and which are domain-invariant, the semantic correctness of existing approaches has not been quantitatively evaluated yet. In this paper, we propose a set of benchmarks and metrics for the evaluation of semantic correctness of UMMI2I methods. We provide an extensive study how well the existing state-of-the-art UMMI2I translation methods preserve domain-invariant and manipulate domain-specific attributes, and discuss the trade-offs shared by all methods, as well as how different architectural choices affect various aspects of semantic correctness.