 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioVITA: Biological Dataset, Model, and Benchmark for Visual-Textual-Acoustic Alignment
Mar 25, 2026Understanding animal species from multimodal data poses an emerging challenge at the intersection of computer vision and ecology. While recent biological models, such as BioCLIP, have demonstrated strong alignment between images and textual taxonomic information for species identification, the integration of the audio modality remains an open problem. We propose BioVITA, a novel visual-textual-acoustic alignment framework for biological applications. BioVITA involves (i) a training dataset, (ii) a representation model, and (iii) a retrieval benchmark. First, we construct a large-scale training dataset comprising 1.3 million audio clips and 2.3 million images, covering 14,133 species annotated with 34 ecological trait labels. Second, building upon BioCLIP2, we introduce a two-stage training framework to effectively align audio representations with visual and textual representations. Third, we develop a cross-modal retrieval benchmark that covers all possible directional retrieval across the three modalities (i.e., image-to-audio, audio-to-text, text-to-image, and their reverse directions), with three taxonomic levels: Family, Genus, and Species. Extensive experiments demonstrate that our model learns a unified representation space that captures species-level semantics beyond taxonomy, advancing multimodal biodiversity understanding. The project page is available at: https://dahlian00.github.io/BioVITA_Page/
HalDec-Bench: Benchmarking Hallucination Detector in Image Captioning
Mar 16, 2026Hallucination detection in captions (HalDec) assesses a vision-language model's ability to correctly align image content with text by identifying errors in captions that misrepresent the image. Beyond evaluation, effective hallucination detection is also essential for curating high-quality image-caption pairs used to train VLMs. However, the generalizability of VLMs as hallucination detectors across different captioning models and hallucination types remains unclear due to the lack of a comprehensive benchmark. In this work, we introduce HalDec-Bench, a benchmark designed to evaluate hallucination detectors in a principled and interpretable manner. HalDec-Bench contains captions generated by diverse VLMs together with human annotations indicating the presence of hallucinations, detailed hallucination-type categories, and segment-level labels. The benchmark provides tasks with a wide range of difficulty levels and reveals performance differences across models that are not visible in existing multimodal reasoning or alignment benchmarks. Our analysis further uncovers two key findings. First, detectors tend to recognize sentences appearing at the beginning of a response as correct, regardless of their actual correctness. Second, our experiments suggest that dataset noise can be substantially reduced by using strong VLMs as filters while employing recent VLMs as caption generators. Our project page is available at https://dahlian00.github.io/HalDec-Bench-Page/.
Where-to-Unmask: Ground-Truth-Guided Unmasking Order Learning for Masked Diffusion Language Models
Feb 10, 2026Masked Diffusion Language Models (MDLMs) generate text by iteratively filling masked tokens, requiring two coupled decisions at each step: which positions to unmask (where-to-unmask) and which tokens to place (what-to-unmask). While standard MDLM training directly optimizes token prediction (what-to-unmask), inference-time unmasking orders (where-to-unmask) are typically determined by heuristic confidence measures or trained through reinforcement learning with costly on-policy rollouts. To address this, we introduce Gt-Margin, a position-wise score derived from ground-truth tokens, defined as the probability margin between the correct token and its strongest alternative. Gt-Margin yields an oracle unmasking order that prioritizes easier positions first under each partially masked state. We demonstrate that leveraging this oracle unmasking order significantly enhances final generation quality, particularly on logical reasoning benchmarks. Building on this insight, we train a supervised unmasking planner via learning-to-rank to imitate the oracle ordering from masked contexts. The resulting planner integrates into standard MDLM sampling to select where-to-unmask, improving reasoning accuracy without modifying the token prediction model.
Towards Safer Mobile Agents: Scalable Generation and Evaluation of Diverse Scenarios for VLMs
Jan 13, 2026Vision Language Models (VLMs) are increasingly deployed in autonomous vehicles and mobile systems, making it crucial to evaluate their ability to support safer decision-making in complex environments. However, existing benchmarks inadequately cover diverse hazardous situations, especially anomalous scenarios with spatio-temporal dynamics. While image editing models are a promising means to synthesize such hazards, it remains challenging to generate well-formulated scenarios that include moving, intrusive, and distant objects frequently observed in the real world. To address this gap, we introduce \textbf{HazardForge}, a scalable pipeline that leverages image editing models to generate these scenarios with layout decision algorithms, and validation modules. Using HazardForge, we construct \textbf{MovSafeBench}, a multiple-choice question (MCQ) benchmark comprising 7,254 images and corresponding QA pairs across 13 object categories, covering both normal and anomalous objects. Experiments using MovSafeBench show that VLM performance degrades notably under conditions including anomalous objects, with the largest drop in scenarios requiring nuanced motion understanding.
CaptionSmiths: Flexibly Controlling Language Pattern in Image Captioning
Jul 02, 2025An image captioning model flexibly switching its language pattern, e.g., descriptiveness and length, should be useful since it can be applied to diverse applications. However, despite the dramatic improvement in generative vision-language models, fine-grained control over the properties of generated captions is not easy due to two reasons: (i) existing models are not given the properties as a condition during training and (ii) existing models cannot smoothly transition its language pattern from one state to the other. Given this challenge, we propose a new approach, CaptionSmiths, to acquire a single captioning model that can handle diverse language patterns. First, our approach quantifies three properties of each caption, length, descriptiveness, and uniqueness of a word, as continuous scalar values, without human annotation. Given the values, we represent the conditioning via interpolation between two endpoint vectors corresponding to the extreme states, e.g., one for a very short caption and one for a very long caption. Empirical results demonstrate that the resulting model can smoothly change the properties of the output captions and show higher lexical alignment than baselines. For instance, CaptionSmiths reduces the error in controlling caption length by 506\% despite better lexical alignment. Code will be available on https://github.com/omron-sinicx/captionsmiths.
SBS Figures: Pre-training Figure QA from Stage-by-Stage Synthesized Images
Dec 23, 2024



Building a large-scale figure QA dataset requires a considerable amount of work, from gathering and selecting figures to extracting attributes like text, numbers, and colors, and generating QAs. Although recent developments in LLMs have led to efforts to synthesize figures, most of these focus primarily on QA generation. Additionally, creating figures directly using LLMs often encounters issues such as code errors, similar-looking figures, and repetitive content in figures. To address this issue, we present SBSFigures (Stage-by-Stage Synthetic Figures), a dataset for pre-training figure QA. Our proposed pipeline enables the creation of chart figures with complete annotations of the visualized data and dense QA annotations without any manual annotation process. Our stage-by-stage pipeline makes it possible to create diverse topic and appearance figures efficiently while minimizing code errors. Our SBSFigures demonstrate a strong pre-training effect, making it possible to achieve efficient training with a limited amount of real-world chart data starting from our pre-trained weights.
Is Large-Scale Pretraining the Secret to Good Domain Generalization?
Dec 03, 2024Multi-Source Domain Generalization (DG) is the task of training on multiple source domains and achieving high classification performance on unseen target domains. Recent methods combine robust features from web-scale pretrained backbones with new features learned from source data, and this has dramatically improved benchmark results. However, it remains unclear if DG finetuning methods are becoming better over time, or if improved benchmark performance is simply an artifact of stronger pre-training. Prior studies have shown that perceptual similarity to pre-training data correlates with zero-shot performance, but we find the effect limited in the DG setting. Instead, we posit that having perceptually similar data in pretraining is not enough; and that it is how well these data were learned that determines performance. This leads us to introduce the Alignment Hypothesis, which states that the final DG performance will be high if and only if alignment of image and class label text embeddings is high. Our experiments confirm the Alignment Hypothesis is true, and we use it as an analysis tool of existing DG methods evaluated on DomainBed datasets by splitting evaluation data into In-pretraining (IP) and Out-of-pretraining (OOP). We show that all evaluated DG methods struggle on DomainBed-OOP, while recent methods excel on DomainBed-IP. Put together, our findings highlight the need for DG methods which can generalize beyond pretraining alignment.
Weak-to-Strong Compositional Learning from Generative Models for Language-based Object Detection
Jul 21, 2024



Vision-language (VL) models often exhibit a limited understanding of complex expressions of visual objects (e.g., attributes, shapes, and their relations), given complex and diverse language queries. Traditional approaches attempt to improve VL models using hard negative synthetic text, but their effectiveness is limited. In this paper, we harness the exceptional compositional understanding capabilities of generative foundational models. We introduce a novel method for structured synthetic data generation aimed at enhancing the compositional understanding of VL models in language-based object detection. Our framework generates densely paired positive and negative triplets (image, text descriptions, and bounding boxes) in both image and text domains. By leveraging these synthetic triplets, we transform 'weaker' VL models into 'stronger' models in terms of compositional understanding, a process we call "Weak-to-Strong Compositional Learning" (WSCL). To achieve this, we propose a new compositional contrastive learning formulation that discovers semantics and structures in complex descriptions from synthetic triplets. As a result, VL models trained with our synthetic data generation exhibit a significant performance boost in the Omnilabel benchmark by up to +5AP and the D3 benchmark by +6.9AP upon existing baselines.
Unsupervised LLM Adaptation for Question Answering
Feb 16, 2024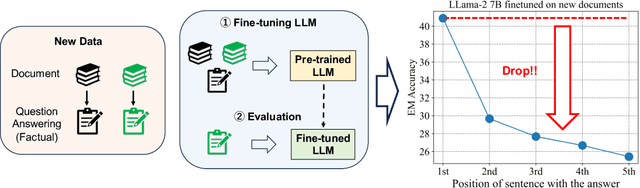

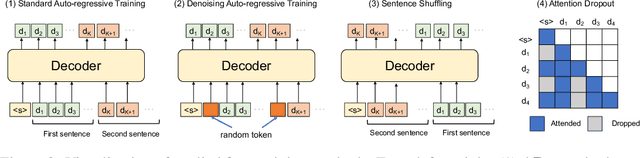
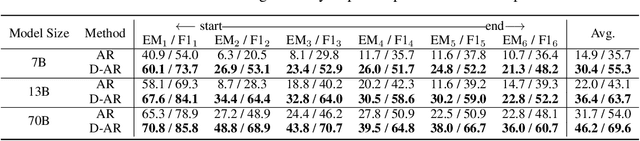
Large language models (LLM) learn diverse knowledge present in the large-scale training dataset via self-supervised training. Followed by instruction-tuning, LLM acquires the ability to return correct information for diverse questions. However, adapting these pre-trained LLMs to new target domains, such as different organizations or periods, for the question-answering (QA) task incurs a substantial annotation cost. To tackle this challenge, we propose a novel task, unsupervised LLM adaptation for question answering. In this task, we leverage a pre-trained LLM, a publicly available QA dataset (source data), and unlabeled documents from the target domain. Our goal is to learn LLM that can answer questions about the target domain. We introduce one synthetic and two real datasets to evaluate models fine-tuned on the source and target data, and reveal intriguing insights; (i) fine-tuned models exhibit the ability to provide correct answers for questions about the target domain even though they do not see any questions about the information described in the unlabeled documents, but (ii) they have difficulties in accessing information located in the middle or at the end of documents, and (iii) this challenge can be partially mitigated by replacing input tokens with random ones during adaptation.
ERM++: An Improved Baseline for Domain Generalization
Apr 04, 2023



Multi-source Domain Generalization (DG) measures a classifier's ability to generalize to new distributions of data it was not trained on, given several training domains. While several multi-source DG methods have been proposed, they incur additional complexity during training by using domain labels. Recent work has shown that a well-tuned Empirical Risk Minimization (ERM) training procedure, that is simply minimizing the empirical risk on the source domains, can outperform most existing DG methods. We identify several key candidate techniques to further improve ERM performance, such as better utilization of training data, model parameter selection, and weight-space regularization. We call the resulting method ERM++, and show it significantly improves the performance of DG on five multi-source datasets by over 5% compared to standard ERM, and beats state-of-the-art despite being less computationally expensive. Additionally, we demonstrate the efficacy of ERM++ on the WILDS-FMOW dataset, a challenging DG benchmark. We hope that ERM++ becomes a strong baseline for future DG research. Code is released at https://github.com/piotr-teterwak/erm_plusplus.