 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefix Conditioning Unifies Language and Label Supervision
Paper and Code
Jun 02, 2022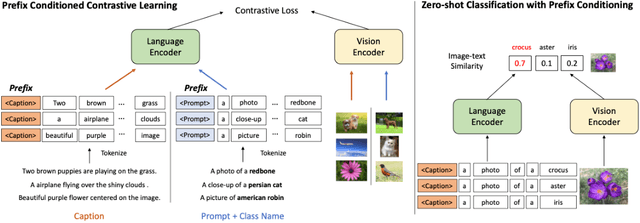
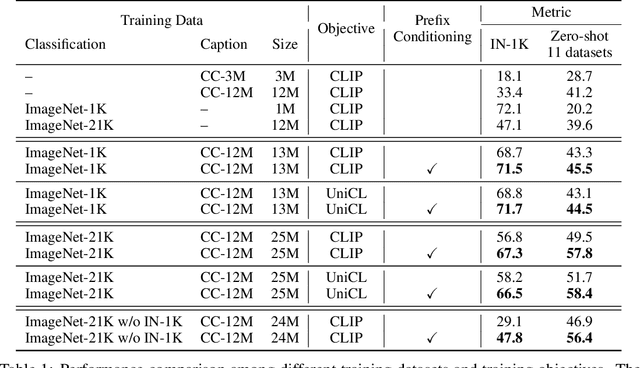


Vision-language contrastive learning suggests a new learning paradigm by leveraging a large amount of image-caption-pair data. The caption supervision excels at providing wide coverage in vocabulary that enables strong zero-shot image recognition performance. On the other hand, label supervision offers to learn more targeted visual representations that are label-oriented and can cover rare categories. To gain the complementary advantages of both kinds of supervision for contrastive image-caption pre-training, recent works have proposed to convert class labels into a sentence with pre-defined templates called prompts. However, a naive unification of the real caption and the prompt sentences could lead to a complication in learning, as the distribution shift in text may not be handled properly in the language encoder. In this work, we propose a simple yet effective approach to unify these two types of supervision using prefix tokens that inform a language encoder of the type of the input sentence (e.g., caption or prompt) at training time. Our method is generic and can be easily integrated into existing VL pre-training objectives such as CLIP or UniCL. In experiments, we show that this simple technique dramatically improves the performance in zero-shot image recognition accuracy of the pre-trained model.