 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Safer Mobile Agents: Scalable Generation and Evaluation of Diverse Scenarios for VLMs
Jan 13, 2026Vision Language Models (VLMs) are increasingly deployed in autonomous vehicles and mobile systems, making it crucial to evaluate their ability to support safer decision-making in complex environments. However, existing benchmarks inadequately cover diverse hazardous situations, especially anomalous scenarios with spatio-temporal dynamics. While image editing models are a promising means to synthesize such hazards, it remains challenging to generate well-formulated scenarios that include moving, intrusive, and distant objects frequently observed in the real world. To address this gap, we introduce \textbf{HazardForge}, a scalable pipeline that leverages image editing models to generate these scenarios with layout decision algorithms, and validation modules. Using HazardForge, we construct \textbf{MovSafeBench}, a multiple-choice question (MCQ) benchmark comprising 7,254 images and corresponding QA pairs across 13 object categories, covering both normal and anomalous objects. Experiments using MovSafeBench show that VLM performance degrades notably under conditions including anomalous objects, with the largest drop in scenarios requiring nuanced motion understanding.
Evaluating the Capability of Video Question Generation for Expert Knowledge Elicitation
Dec 17, 2025Skilled human interviewers can extract valuable information from experts. This raises a fundamental question: what makes some questions more effective than others? To address this, a quantitative evaluation of question-generation models is essential. Video question generation (VQG) is a topic for video question answering (VideoQA), where questions are generated for given answers. Their evaluation typically focuses on the ability to answer questions, rather than the quality of generated questions. In contrast, we focus on the question quality in eliciting unseen knowledge from human experts. For a continuous improvement of VQG models, we propose a protocol that evaluates the ability by simulating question-answering communication with experts using a question-to-answer retrieval. We obtain the retriever by constructing a novel dataset, EgoExoAsk, which comprises 27,666 QA pairs generated from Ego-Exo4D's expert commentary annotation. The EgoExoAsk training set is used to obtain the retriever, and the benchmark is constructed on the validation set with Ego-Exo4D video segments. Experimental results demonstrate our metric reasonably aligns with question generation settings: models accessing richer context are evaluated better, supporting that our protocol works as intended. The EgoExoAsk dataset is available in https://github.com/omron-sinicx/VQG4ExpertKnowledge .
CaptionSmiths: Flexibly Controlling Language Pattern in Image Captioning
Jul 02, 2025An image captioning model flexibly switching its language pattern, e.g., descriptiveness and length, should be useful since it can be applied to diverse applications. However, despite the dramatic improvement in generative vision-language models, fine-grained control over the properties of generated captions is not easy due to two reasons: (i) existing models are not given the properties as a condition during training and (ii) existing models cannot smoothly transition its language pattern from one state to the other. Given this challenge, we propose a new approach, CaptionSmiths, to acquire a single captioning model that can handle diverse language patterns. First, our approach quantifies three properties of each caption, length, descriptiveness, and uniqueness of a word, as continuous scalar values, without human annotation. Given the values, we represent the conditioning via interpolation between two endpoint vectors corresponding to the extreme states, e.g., one for a very short caption and one for a very long caption. Empirical results demonstrate that the resulting model can smoothly change the properties of the output captions and show higher lexical alignment than baselines. For instance, CaptionSmiths reduces the error in controlling caption length by 506\% despite better lexical alignment. Code will be available on https://github.com/omron-sinicx/captionsmiths.
KeyMPs: One-Shot Vision-Language Guided Motion Generation by Sequencing DMPs for Occlusion-Rich Tasks
Apr 14, 2025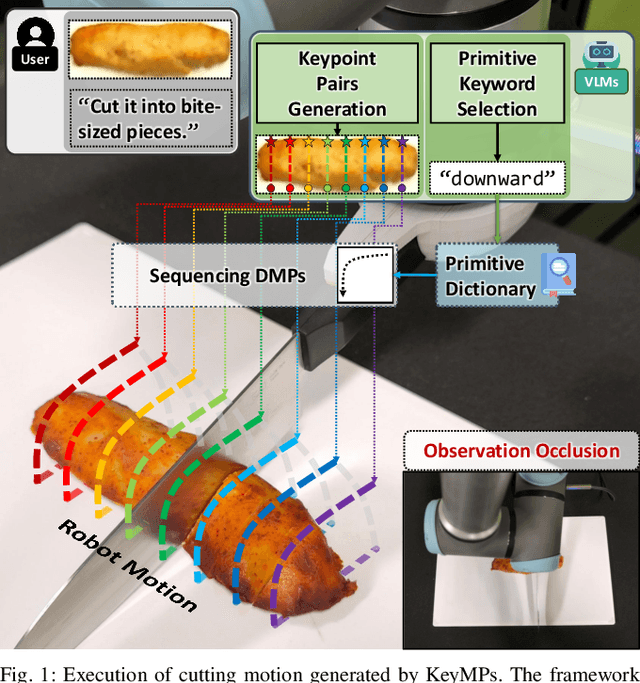
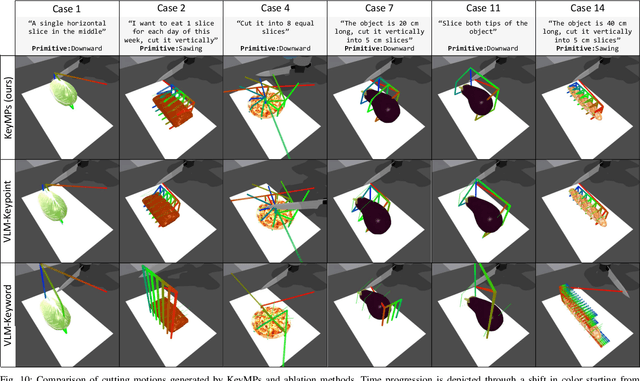
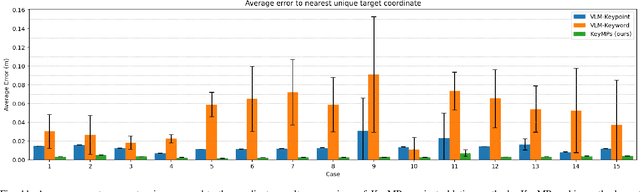
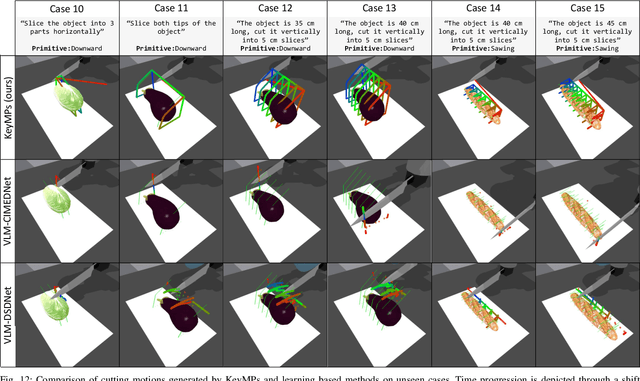
Dynamic Movement Primitives (DMPs) provide a flexible framework wherein smooth robotic motions are encoded into modular parameters. However, they face challenges in integrating multimodal inputs commonly used in robotics like vision and language into their framework. To fully maximize DMPs' potential, enabling them to handle multimodal inputs is essential. In addition, we also aim to extend DMPs' capability to handle object-focused tasks requiring one-shot complex motion generation, as observation occlusion could easily happen mid-execution in such tasks (e.g., knife occlusion in cake icing, hand occlusion in dough kneading, etc.). A promising approach is to leverage Vision-Language Models (VLMs), which process multimodal data and can grasp high-level concepts. However, they typically lack enough knowledge and capabilities to directly infer low-level motion details and instead only serve as a bridge between high-level instructions and low-level control. To address this limitation, we propose Keyword Labeled Primitive Selection and Keypoint Pairs Generation Guided Movement Primitives (KeyMPs), a framework that combines VLMs with sequencing of DMPs. KeyMPs use VLMs' high-level reasoning capability to select a reference primitive through keyword labeled primitive selection and VLMs' spatial awareness to generate spatial scaling parameters used for sequencing DMPs by generalizing the overall motion through keypoint pairs generation, which together enable one-shot vision-language guided motion generation that aligns with the intent expressed in the multimodal input. We validate our approach through an occlusion-rich manipulation task, specifically object cutting experiments in both simulated and real-world environments, demonstrating superior performance over other DMP-based methods that integrate VLMs support.
Visuo-Tactile Zero-Shot Object Recognition with Vision-Language Model
Sep 14, 2024
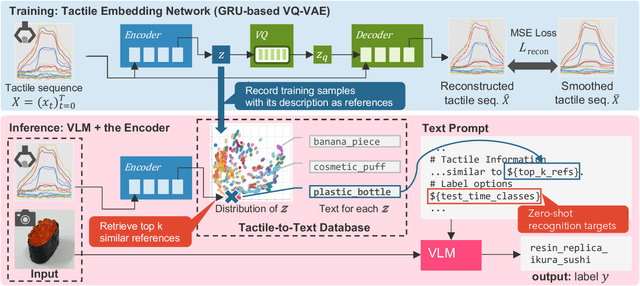
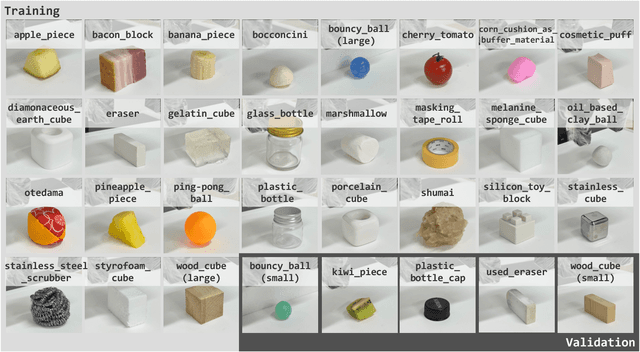
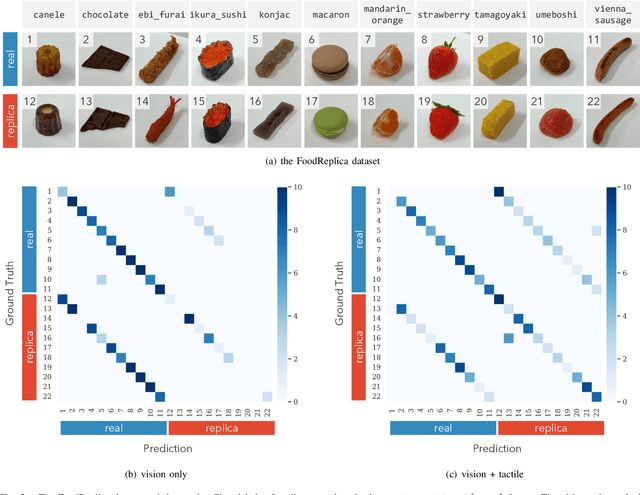
Tactile perception is vital, especially when distinguishing visually similar objects. We propose an approach to incorporate tactile data into a Vision-Language Model (VLM) for visuo-tactile zero-shot object recognition. Our approach leverages the zero-shot capability of VLMs to infer tactile properties from the names of tactilely similar objects. The proposed method translates tactile data into a textual description solely by annotating object names for each tactile sequence during training, making it adaptable to various contexts with low training costs. The proposed method was evaluated on the FoodReplica and Cube datasets, demonstrating its effectiveness in recognizing objects that are difficult to distinguish by vision alone.
COM Kitchens: An Unedited Overhead-view Video Dataset as a Vision-Language Benchmark
Aug 05, 2024Procedural video understanding is gaining attention in the vision and language community. Deep learning-based video analysis requires extensive data. Consequently, existing works often use web videos as training resources, making it challenging to query instructional contents from raw video observations. To address this issue, we propose a new dataset, COM Kitchens. The dataset consists of unedited overhead-view videos captured by smartphones, in which participants performed food preparation based on given recipes. Fixed-viewpoint video datasets often lack environmental diversity due to high camera setup costs. We used modern wide-angle smartphone lenses to cover cooking counters from sink to cooktop in an overhead view, capturing activity without in-person assistance. With this setup, we collected a diverse dataset by distributing smartphones to participants. With this dataset, we propose the novel video-to-text retrieval task Online Recipe Retrieval (OnRR) and new video captioning domain Dense Video Captioning on unedited Overhead-View videos (DVC-OV). Our experiments verified the capabilities and limitations of current web-video-based SOTA methods in handling these tasks.
AdaCoder: Adaptive Prompt Compression for Programmatic Visual Question Answering
Jul 28, 2024Visual question answering aims to provide responses to natural language questions given visual input. Recently, visual programmatic models (VPMs), which generate executable programs to answer questions through large language models (LLMs), have attracted research interest. However, they often require long input prompts to provide the LLM with sufficient API usage details to generate relevant code. To address this limitation, we propose AdaCoder, an adaptive prompt compression framework for VPMs. AdaCoder operates in two phases: a compression phase and an inference phase. In the compression phase, given a preprompt that describes all API definitions in the Python language with example snippets of code, a set of compressed preprompts is generated, each depending on a specific question type. In the inference phase, given an input question, AdaCoder predicts the question type and chooses the appropriate corresponding compressed preprompt to generate code to answer the question. Notably, AdaCoder employs a single frozen LLM and pre-defined prompts, negating the necessity of additional training and maintaining adaptability across different powerful black-box LLMs such as GPT and Claude. In experiments, we apply AdaCoder to ViperGPT and demonstrate that it reduces token length by 71.1%, while maintaining or even improving the performance of visual question answering.
Exo2EgoDVC: Dense Video Captioning of Egocentric Procedural Activities Using Web Instructional Videos
Nov 29, 2023



We propose a novel benchmark for cross-view knowledge transfer of dense video captioning, adapting models from web instructional videos with exocentric views to an egocentric view. While dense video captioning (predicting time segments and their captions) is primarily studied with exocentric videos (e.g., YouCook2), benchmarks with egocentric videos are restricted due to data scarcity. To overcome the limited video availability, transferring knowledge from abundant exocentric web videos is demanded as a practical approach. However, learning the correspondence between exocentric and egocentric views is difficult due to their dynamic view changes. The web videos contain mixed views focusing on either human body actions or close-up hand-object interactions, while the egocentric view is constantly shifting as the camera wearer moves. This necessitates the in-depth study of cross-view transfer under complex view changes. In this work, we first create a real-life egocentric dataset (EgoYC2) whose captions are shared with YouCook2, enabling transfer learning between these datasets assuming their ground-truth is accessible. To bridge the view gaps, we propose a view-invariant learning method using adversarial training in both the pre-training and fine-tuning stages. While the pre-training is designed to learn invariant features against the mixed views in the web videos, the view-invariant fine-tuning further mitigates the view gaps between both datasets. We validate our proposed method by studying how effectively it overcomes the view change problem and efficiently transfers the knowledge to the egocentric domain. Our benchmark pushes the study of the cross-view transfer into a new task domain of dense video captioning and will envision methodologies to describe egocentric videos in natural language.
Vision-Language Interpreter for Robot Task Planning
Nov 02, 2023



Large language models (LLMs) are accelerating the development of language-guided robot planners. Meanwhile, symbolic planners offer the advantage of interpretability. This paper proposes a new task that bridges these two trends, namely, multimodal planning problem specification. The aim is to generate a problem description (PD), a machine-readable file used by the planners to find a plan. By generating PDs from language instruction and scene observation, we can drive symbolic planners in a language-guided framework. We propose a Vision-Language Interpreter (ViLaIn), a new framework that generates PDs using state-of-the-art LLM and vision-language models. ViLaIn can refine generated PDs via error message feedback from the symbolic planner. Our aim is to answer the question: How accurately can ViLaIn and the symbolic planner generate valid robot plans? To evaluate ViLaIn, we introduce a novel dataset called the problem description generation (ProDG) dataset. The framework is evaluated with four new evaluation metrics. Experimental results show that ViLaIn can generate syntactically correct problems with more than 99% accuracy and valid plans with more than 58% accuracy.
WeaveNet for Approximating Two-sided Matching Problems
Oct 19, 2023Matching, a task to optimally assign limited resources under constraints, is a fundamental technology for society. The task potentially has various objectives, conditions, and constraints; however, the efficient neural network architecture for matching is underexplored. This paper proposes a novel graph neural network (GNN), \textit{WeaveNet}, designed for bipartite graphs. Since a bipartite graph is generally dense, general GNN architectures lose node-wise information by over-smoothing when deeply stacked. Such a phenomenon is undesirable for solving matching problems. WeaveNet avoids it by preserving edge-wise information while passing messages densely to reach a better solution. To evaluate the model, we approximated one of the \textit{strongly NP-hard} problems, \textit{fair stable matching}. Despite its inherent difficulties and the network's general purpose design, our model reached a comparative performance with state-of-the-art algorithms specially designed for stable matching for small numbers of agents.