 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISCODE: Distribution-Aware Score Decoder for Robust Automatic Evaluation of Image Captioning
Dec 16, 2025Large vision-language models (LVLMs) have shown impressive performance across a broad range of multimodal tasks. However, robust image caption evaluation using LVLMs remains challenging, particularly under domain-shift scenarios. To address this issue, we introduce the Distribution-Aware Score Decoder (DISCODE), a novel finetuning-free method that generates robust evaluation scores better aligned with human judgments across diverse domains. The core idea behind DISCODE lies in its test-time adaptive evaluation approach, which introduces the Adaptive Test-Time (ATT) loss, leveraging a Gaussian prior distribution to improve robustness in evaluation score estimation. This loss is efficiently minimized at test time using an analytical solution that we derive. Furthermore, we introduce the Multi-domain Caption Evaluation (MCEval) benchmark, a new image captioning evaluation benchmark covering six distinct domains, designed to assess the robustness of evaluation metrics. In our experiments, we demonstrate that DISCODE achieves state-of-the-art performance as a reference-free evaluation metric across MCEval and four representative existing benchmarks.
STATUS Bench: A Rigorous Benchmark for Evaluating Object State Understanding in Vision-Language Models
Oct 26, 2025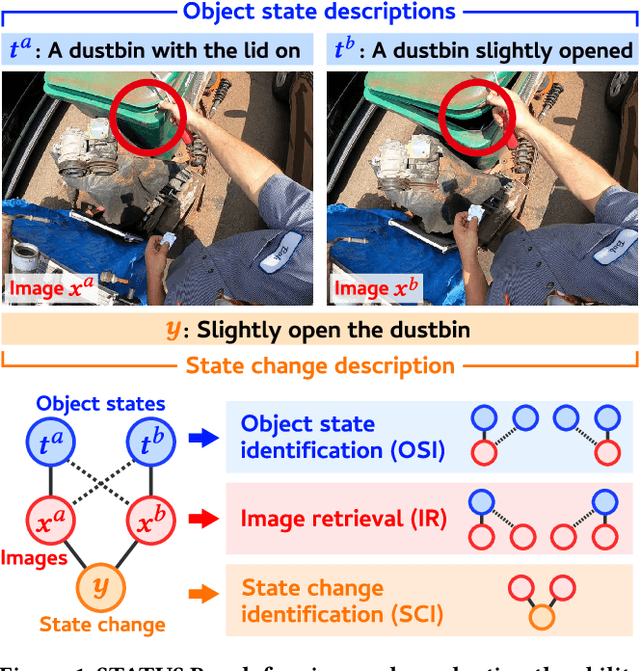



Object state recognition aims to identify the specific condition of objects, such as their positional states (e.g., open or closed) and functional states (e.g., on or off). While recent Vision-Language Models (VLMs) are capable of performing a variety of multimodal tasks, it remains unclear how precisely they can identify object states. To alleviate this issue, we introduce the STAte and Transition UnderStanding Benchmark (STATUS Bench), the first benchmark for rigorously evaluating the ability of VLMs to understand subtle variations in object states in diverse situations. Specifically, STATUS Bench introduces a novel evaluation scheme that requires VLMs to perform three tasks simultaneously: object state identification (OSI), image retrieval (IR), and state change identification (SCI). These tasks are defined over our fully hand-crafted dataset involving image pairs, their corresponding object state descriptions and state change descriptions. Furthermore, we introduce a large-scale training dataset, namely STATUS Train, which consists of 13 million semi-automatically created descriptions. This dataset serves as the largest resource to facilitate further research in this area. In our experiments, we demonstrate that STATUS Bench enables rigorous consistency evaluation and reveal that current state-of-the-art VLMs still significantly struggle to capture subtle object state distinctions. Surprisingly, under the proposed rigorous evaluation scheme, most open-weight VLMs exhibited chance-level zero-shot performance. After fine-tuning on STATUS Train, Qwen2.5-VL achieved performance comparable to Gemini 2.0 Flash. These findings underscore the necessity of STATUS Bench and Train for advancing object state recognition in VLM research.
AdaCoder: Adaptive Prompt Compression for Programmatic Visual Question Answering
Jul 28, 2024Visual question answering aims to provide responses to natural language questions given visual input. Recently, visual programmatic models (VPMs), which generate executable programs to answer questions through large language models (LLMs), have attracted research interest. However, they often require long input prompts to provide the LLM with sufficient API usage details to generate relevant code. To address this limitation, we propose AdaCoder, an adaptive prompt compression framework for VPMs. AdaCoder operates in two phases: a compression phase and an inference phase. In the compression phase, given a preprompt that describes all API definitions in the Python language with example snippets of code, a set of compressed preprompts is generated, each depending on a specific question type. In the inference phase, given an input question, AdaCoder predicts the question type and chooses the appropriate corresponding compressed preprompt to generate code to answer the question. Notably, AdaCoder employs a single frozen LLM and pre-defined prompts, negating the necessity of additional training and maintaining adaptability across different powerful black-box LLMs such as GPT and Claude. In experiments, we apply AdaCoder to ViperGPT and demonstrate that it reduces token length by 71.1%, while maintaining or even improving the performance of visual question answering.