 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABMAMBA: Multimodal Large Language Model with Aligned Hierarchical Bidirectional Scan for Efficient Video Captioning
Apr 09, 2026In this study, we focus on video captioning by fully open multimodal large language models (MLLMs). The comprehension of visual sequences is challenging because of their intricate temporal dependencies and substantial sequence length. The core attention mechanisms of existing Transformer-based approaches scale quadratically with the sequence length, making them computationally prohibitive. To address these limitations, we propose Aligned Hierarchical Bidirectional Scan Mamba (ABMamba), a fully open MLLM with linear computational complexity that enables the scalable processing of video sequences. ABMamba extends Deep State Space Models as its language backbone, replacing the costly quadratic attention mechanisms, and employs a novel Aligned Hierarchical Bidirectional Scan module that processes videos across multiple temporal resolutions. On standard video captioning benchmarks such as VATEX and MSR-VTT, ABMamba demonstrates competitive performance compared to typical MLLMs while achieving approximately three times higher throughput.
Jagle: Building a Large-Scale Japanese Multimodal Post-Training Dataset for Vision-Language Models
Apr 02, 2026Developing vision-language models (VLMs) that generalize across diverse tasks requires large-scale training datasets with diverse content. In English, such datasets are typically constructed by aggregating and curating numerous existing visual question answering (VQA) resources. However, this strategy does not readily extend to other languages, where VQA datasets remain limited in both scale and domain coverage, posing a major obstacle to building high-quality multilingual and non-English VLMs. In this work, we introduce Jagle, the largest Japanese multimodal post-training dataset to date, comprising approximately 9.2 million instances across diverse tasks. Rather than relying on existing VQA datasets, we collect heterogeneous source data, including images, image-text pairs, and PDF documents, and generate VQA pairs through multiple strategies such as VLM-based QA generation, translation, and text rendering. Experiments demonstrate that a 2.2B model trained with Jagle achieves strong performance on Japanese tasks, surpassing InternVL3.5-2B in average score across ten Japanese evaluation tasks and approaching within five points of Qwen3-VL-2B-Instruct. Furthermore, combining Jagle with FineVision does not degrade English performance; instead, it improves English performance compared to training with FineVision alone. To facilitate reproducibility and future research, we release the dataset, trained models, and code.
JAMMEval: A Refined Collection of Japanese Benchmarks for Reliable VLM Evaluation
Apr 01, 2026Reliable evaluation is essential for the development of vision-language models (VLMs). However, Japanese VQA benchmarks have undergone far less iterative refinement than their English counterparts. As a result, many existing benchmarks contain issues such as ambiguous questions, incorrect answers, and instances that can be solved without visual grounding, undermining evaluation reliability and leading to misleading conclusions in model comparisons. To address these limitations, we introduce JAMMEval, a refined collection of Japanese benchmarks for reliable VLM evaluation. It is constructed by systematically refining seven existing Japanese benchmark datasets through two rounds of human annotation, improving both data quality and evaluation reliability. In our experiments, we evaluate open-weight and proprietary VLMs on JAMMEval and analyze the capabilities of recent models on Japanese VQA. We further demonstrate the effectiveness of our refinement by showing that the resulting benchmarks yield evaluation scores that better reflect model capability, exhibit lower run-to-run variance, and improve the ability to distinguish between models of different capability levels. We release our dataset and code to advance reliable evaluation of VLMs.
EC-Bench: Enumeration and Counting Benchmark for Ultra-Long Videos
Mar 31, 2026Counting in long videos remains a fundamental yet underexplored challenge in computer vision. Real-world recordings often span tens of minutes or longer and contain sparse, diverse events, making long-range temporal reasoning particularly difficult. However, most existing video counting benchmarks focus on short clips and evaluate only the final numerical answer, providing little insight into what should be counted or whether models consistently identify relevant instances across time. We introduce EC-Bench, a benchmark that jointly evaluates enumeration, counting, and temporal evidence grounding in long-form videos. EC-Bench contains 152 videos longer than 30 minutes and 1,699 queries paired with explicit evidence spans. Across 22 multimodal large language models (MLLMs), the best model achieves only 29.98% accuracy on Enumeration and 23.74% on Counting, while human performance reaches 78.57% and 82.97%, respectively. Our analysis reveals strong relationships between enumeration accuracy, temporal grounding, and counting performance. These results highlight fundamental limitations of current MLLMs and establish EC-Bench as a challenging benchmark for long-form quantitative video reasoning.
HiFlow: Tokenization-Free Scale-Wise Autoregressive Policy Learning via Flow Matching
Mar 28, 2026Coarse-to-fine autoregressive modeling has recently shown strong promise for visuomotor policy learning, combining the inference efficiency of autoregressive methods with the global trajectory coherence of diffusion-based policies. However, existing approaches rely on discrete action tokenizers that map continuous action sequences to codebook indices, a design inherited from image generation where learned compression is necessary for high-dimensional pixel data. We observe that robot actions are inherently low-dimensional continuous vectors, for which such tokenization introduces unnecessary quantization error and a multi-stage training pipeline. In this work, we propose Hierarchical Flow Policy (HiFlow), a tokenization-free coarse-to-fine autoregressive policy that operates directly on raw continuous actions. HiFlow constructs multi-scale continuous action targets from each action chunk via simple temporal pooling. Specifically, it averages contiguous action windows to produce coarse summaries that are refined at finer temporal resolutions. The entire model is trained end-to-end in a single stage, eliminating the need for a separate tokenizer. Experiments on MimicGen, RoboTwin 2.0, and real-world environments demonstrate that HiFlow consistently outperforms existing methods including diffusion-based and tokenization-based autoregressive policies.
PhysQuantAgent: An Inference Pipeline of Mass Estimation for Vision-Language Models
Mar 17, 2026Vision-Language Models (VLMs) are increasingly applied to robotic perception and manipulation, yet their ability to infer physical properties required for manipulation remains limited. In particular, estimating the mass of real-world objects is essential for determining appropriate grasp force and ensuring safe interaction. However, current VLMs lack reliable mass reasoning capabilities, and most existing benchmarks do not explicitly evaluate physical quantity estimation under realistic sensing conditions. In this work, we propose PhysQuantAgent, a framework for real-world object mass estimation using VLMs, together with VisPhysQuant, a new benchmark dataset for evaluation. VisPhysQuant consists of RGB-D videos of real objects captured from multiple viewpoints, annotated with precise mass measurements. To improve estimation accuracy, we introduce three visual prompting methods that enhance the input image with object detection, scale estimation, and cross-sectional image generation to help the model comprehend the size and internal structure of the target object. Experiments show that visual prompting significantly improves mass estimation accuracy on real-world data, suggesting the efficacy of integrating spatial reasoning with VLM knowledge for physical inference.
From Dialogue to Execution: Mixture-of-Agents Assisted Interactive Planning for Behavior Tree-Based Long-Horizon Robot Execution
Mar 01, 2026Interactive task planning with large language models (LLMs) enables robots to generate high-level action plans from natural language instructions. However, in long-horizon tasks, such approaches often require many questions, increasing user burden. Moreover, flat plan representations become difficult to manage as task complexity grows. We propose a framework that integrates Mixture-of-Agents (MoA)-based proxy answering into interactive planning and generates Behavior Trees (BTs) for structured long-term execution. The MoA consists of multiple LLM-based expert agents that answer general or domain-specific questions when possible, reducing unnecessary human intervention. The resulting BT hierarchically represents task logic and enables retry mechanisms and dynamic switching among multiple robot policies. Experiments on cocktail-making tasks show that the proposed method reduces human response requirements by approximately 27% while maintaining structural and semantic similarity to fully human-answered BTs. Real-robot experiments on a smoothie-making task further demonstrate successful long-horizon execution with adaptive policy switching and recovery from action failures. These results indicate that MoA-assisted interactive planning improves dialogue efficiency while preserving execution quality in real-world robotic tasks.
ReMoRa: Multimodal Large Language Model based on Refined Motion Representation for Long-Video Understanding
Feb 18, 2026While multimodal large language models (MLLMs) have shown remarkable success across a wide range of tasks, long-form video understanding remains a significant challenge. In this study, we focus on video understanding by MLLMs. This task is challenging because processing a full stream of RGB frames is computationally intractable and highly redundant, as self-attention have quadratic complexity with sequence length. In this paper, we propose ReMoRa, a video MLLM that processes videos by operating directly on their compressed representations. A sparse set of RGB keyframes is retained for appearance, while temporal dynamics are encoded as a motion representation, removing the need for sequential RGB frames. These motion representations act as a compact proxy for optical flow, capturing temporal dynamics without full frame decoding. To refine the noise and low fidelity of block-based motions, we introduce a module to denoise and generate a fine-grained motion representation. Furthermore, our model compresses these features in a way that scales linearly with sequence length. We demonstrate the effectiveness of ReMoRa through extensive experiments across a comprehensive suite of long-video understanding benchmarks. ReMoRa outperformed baseline methods on multiple challenging benchmarks, including LongVideoBench, NExT-QA, and MLVU.
STATUS Bench: A Rigorous Benchmark for Evaluating Object State Understanding in Vision-Language Models
Oct 26, 2025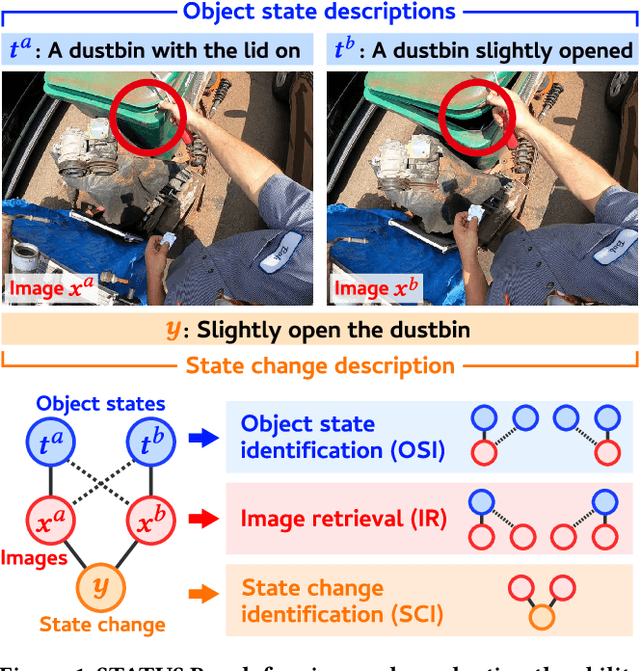



Object state recognition aims to identify the specific condition of objects, such as their positional states (e.g., open or closed) and functional states (e.g., on or off). While recent Vision-Language Models (VLMs) are capable of performing a variety of multimodal tasks, it remains unclear how precisely they can identify object states. To alleviate this issue, we introduce the STAte and Transition UnderStanding Benchmark (STATUS Bench), the first benchmark for rigorously evaluating the ability of VLMs to understand subtle variations in object states in diverse situations. Specifically, STATUS Bench introduces a novel evaluation scheme that requires VLMs to perform three tasks simultaneously: object state identification (OSI), image retrieval (IR), and state change identification (SCI). These tasks are defined over our fully hand-crafted dataset involving image pairs, their corresponding object state descriptions and state change descriptions. Furthermore, we introduce a large-scale training dataset, namely STATUS Train, which consists of 13 million semi-automatically created descriptions. This dataset serves as the largest resource to facilitate further research in this area. In our experiments, we demonstrate that STATUS Bench enables rigorous consistency evaluation and reveal that current state-of-the-art VLMs still significantly struggle to capture subtle object state distinctions. Surprisingly, under the proposed rigorous evaluation scheme, most open-weight VLMs exhibited chance-level zero-shot performance. After fine-tuning on STATUS Train, Qwen2.5-VL achieved performance comparable to Gemini 2.0 Flash. These findings underscore the necessity of STATUS Bench and Train for advancing object state recognition in VLM research.
Developing Vision-Language-Action Model from Egocentric Videos
Sep 26, 2025Egocentric videos capture how humans manipulate objects and tools, providing diverse motion cues for learning object manipulation. Unlike the costly, expert-driven manual teleoperation commonly used in training Vision-Language-Action models (VLAs), egocentric videos offer a scalable alternative. However, prior studies that leverage such videos for training robot policies typically rely on auxiliary annotations, such as detailed hand-pose recordings. Consequently, it remains unclear whether VLAs can be trained directly from raw egocentric videos. In this work, we address this challenge by leveraging EgoScaler, a framework that extracts 6DoF object manipulation trajectories from egocentric videos without requiring auxiliary recordings. We apply EgoScaler to four large-scale egocentric video datasets and automatically refine noisy or incomplete trajectories, thereby constructing a new large-scale dataset for VLA pre-training. Our experiments with a state-of-the-art $\pi_0$ architecture in both simulated and real-robot environments yield three key findings: (i) pre-training on our dataset improves task success rates by over 20\% compared to training from scratch, (ii) the performance is competitive with that achieved using real-robot datasets, and (iii) combining our dataset with real-robot data yields further improvements. These results demonstrate that egocentric videos constitute a promising and scalable resource for advancing VLA research.