 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama-Mimi: Speech Language Models with Interleaved Semantic and Acoustic Tokens
Sep 18, 2025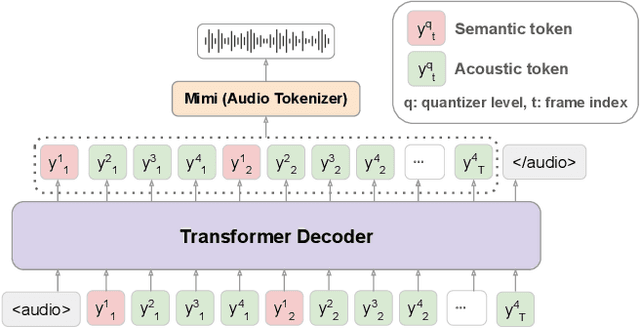
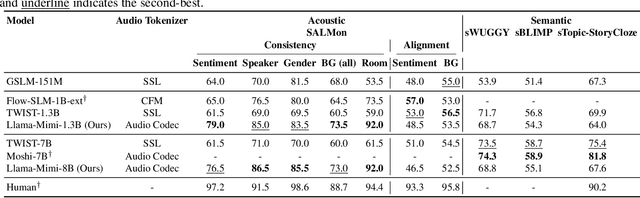

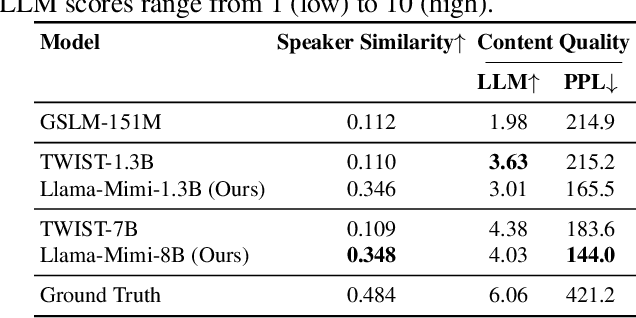
We propose Llama-Mimi, a speech language model that uses a unified tokenizer and a single Transformer decoder to jointly model sequences of interleaved semantic and acoustic tokens. Comprehensive evaluation shows that Llama-Mimi achieves state-of-the-art performance in acoustic consistency and possesses the ability to preserve speaker identity. Our analysis further demonstrates that increasing the number of quantizers improves acoustic fidelity but degrades linguistic performance, highlighting the inherent challenge of maintaining long-term coherence. We additionally introduce an LLM-as-a-Judge-based evaluation to assess the spoken content quality of generated outputs. Our models, code, and speech samples are publicly available.
Universal Post-Processing Networks for Joint Optimization of Modules in Task-Oriented Dialogue Systems
Feb 02, 2025



Post-processing networks (PPNs) are components that modify the outputs of arbitrary modules in task-oriented dialogue systems and are optimized using reinforcement learning (RL) to improve the overall task completion capability of the system. However, previous PPN-based approaches have been limited to handling only a subset of modules within a system, which poses a significant limitation in improving the system performance. In this study, we propose a joint optimization method for post-processing the outputs of all modules using universal post-processing networks (UniPPNs), which are language-model-based networks that can modify the outputs of arbitrary modules in a system as a sequence-transformation task. Moreover, our RL algorithm, which employs a module-level Markov decision process, enables fine-grained value and advantage estimation for each module, thereby stabilizing joint learning for post-processing the outputs of all modules. Through both simulation-based and human evaluation experiments using the MultiWOZ dataset, we demonstrated that UniPPN outperforms conventional PPNs in the task completion capability of task-oriented dialogue systems.
JMultiWOZ: A Large-Scale Japanese Multi-Domain Task-Oriented Dialogue Dataset
Mar 26, 2024



Dialogue datasets are crucial for deep learning-based task-oriented dialogue system research. While numerous English language multi-domain task-oriented dialogue datasets have been developed and contributed to significant advancements in task-oriented dialogue systems, such a dataset does not exist in Japanese, and research in this area is limited compared to that in English. In this study, towards the advancement of research and development of task-oriented dialogue systems in Japanese, we constructed JMultiWOZ, the first Japanese language large-scale multi-domain task-oriented dialogue dataset. Using JMultiWOZ, we evaluated the dialogue state tracking and response generation capabilities of the state-of-the-art methods on the existing major English benchmark dataset MultiWOZ2.2 and the latest large language model (LLM)-based methods. Our evaluation results demonstrated that JMultiWOZ provides a benchmark that is on par with MultiWOZ2.2. In addition, through evaluation experiments of interactive dialogues with the models and human participants, we identified limitations in the task completion capabilities of LLMs in Japanese.
Proceedings of the Dialogue Robot Competition 2023
Jan 15, 2024The Dialogic Robot Competition 2023 (DRC2023) is a competition for humanoid robots (android robots that closely resemble humans) to compete in interactive capabilities. This is the third year of the competition. The top four teams from the preliminary competition held in November 2023 will compete in the final competition on Saturday, December 23. The task for the interactive robots is to recommend a tourism plan for a specific region. The robots can employ multimodal behaviors, such as language and gestures, to engage the user in the sightseeing plan they recommend. In the preliminary round, the interactive robots were stationed in a travel agency office, where visitors conversed with them and rated their performance via a questionnaire. In the final round, dialogue researchers and tourism industry professionals interacted with the robots and evaluated their performance. This event allows visitors to gain insights into the types of dialogue services that future dialogue robots should offer. The proceedings include papers on dialogue systems developed by the 12 teams participating in DRC2023, as well as an overview of the papers provided by all the teams.
Overview of Dialogue Robot Competition 2023
Jan 07, 2024We have held dialogue robot competitions in 2020 and 2022 to compare the performances of interactive robots using an android that closely resembles a human. In 2023, the third competition DRC2023 was held. The task of DRC2023 was designed to be more challenging than the previous travel agent dialogue tasks. Since anyone can now develop a dialogue system using LLMs, the participating teams are required to develop a system that effectively uses information about the situation on the spot (real-time information), which is not handled by ChatGPT and other systems. DRC2023 has two rounds, a preliminary round and the final round as well as the previous competitions. The preliminary round has held on Oct.27 -- Nov.20, 2023 at real travel agency stores. The final round will be held on December 23, 2023. This paper provides an overview of the task settings and evaluation method of DRC2023 and the preliminary round results.
Team Flow at DRC2023: Building Common Ground and Text-based Turn-taking in a Travel Agent Spoken Dialogue System
Dec 21, 2023At the Dialogue Robot Competition 2023 (DRC2023), which was held to improve the capability of dialogue robots, our team developed a system that could build common ground and take more natural turns based on user utterance texts. Our system generated queries for sightseeing spot searches using the common ground and engaged in dialogue while waiting for user comprehension.
Cognitive Architecture Toward Common Ground Sharing Among Humans and Generative AIs: Trial on Model-Model Interactions in Tangram Naming Task
Nov 10, 2023For generative AIs to be trustworthy, establishing transparent common grounding with humans is essential. As a preparation toward human-model common grounding, this study examines the process of model-model common grounding. In this context, common ground is defined as a cognitive framework shared among agents in communication, enabling the connection of symbols exchanged between agents to the meanings inherent in each agent. This connection is facilitated by a shared cognitive framework among the agents involved. In this research, we focus on the tangram naming task (TNT) as a testbed to examine the common-ground-building process. Unlike previous models designed for this task, our approach employs generative AIs to visualize the internal processes of the model. In this task, the sender constructs a metaphorical image of an abstract figure within the model and generates a detailed description based on this image. The receiver interprets the generated description from the partner by constructing another image and reconstructing the original abstract figure. Preliminary results from the study show an improvement in task performance beyond the chance level, indicating the effect of the common cognitive framework implemented in the models. Additionally, we observed that incremental backpropagations leveraging successful communication cases for a component of the model led to a statistically significant increase in performance. These results provide valuable insights into the mechanisms of common grounding made by generative AIs, improving human communication with the evolving intelligent machines in our future society.
Overview of Dialogue Robot Competition 2022
Oct 23, 2022



Although many competitions have been held on dialogue systems in the past, no competition has been organized specifically for dialogue with humanoid robots. As the first such attempt in the world, we held a dialogue robot competition in 2020 to compare the performances of interactive robots using an android that closely resembles a human. Dialogue Robot Competition 2022 (DRC2022) was the second competition, held in August 2022. The task and regulations followed those of the first competition, while the evaluation method was improved and the event was internationalized. The competition has two rounds, a preliminary round and the final round. In the preliminary round, twelve participating teams competed in performance of a dialogue robot in the manner of a field experiment, and then three of those teams were selected as finalists. The final round will be held on October 25, 2022, in the Robot Competition session of IROS2022. This paper provides an overview of the task settings and evaluation method of DRC2022 and the results of the preliminary round.
Team Flow at DRC2022: Pipeline System for Travel Destination Recommendation Task in Spoken Dialogue
Oct 18, 2022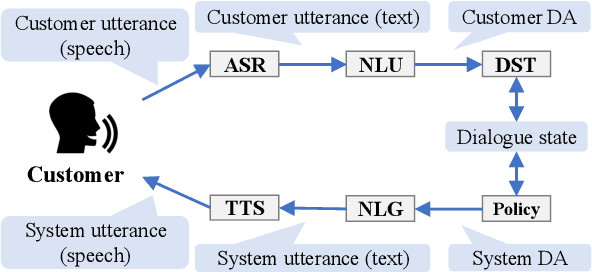



To improve the interactive capabilities of a dialogue system, e.g., to adapt to different customers, the Dialogue Robot Competition (DRC2022) was held. As one of the teams, we built a dialogue system with a pipeline structure containing four modules. The natural language understanding (NLU) and natural language generation (NLG) modules were GPT-2 based models, and the dialogue state tracking (DST) and policy modules were designed on the basis of hand-crafted rules. After the preliminary round of the competition, we found that the low variation in training examples for the NLU and failed recommendation due to the policy used were probably the main reasons for the limited performance of the system.
Adaptive Natural Language Generation for Task-oriented Dialogue via Reinforcement Learning
Sep 16, 2022
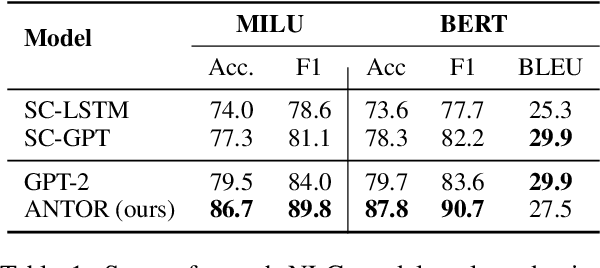
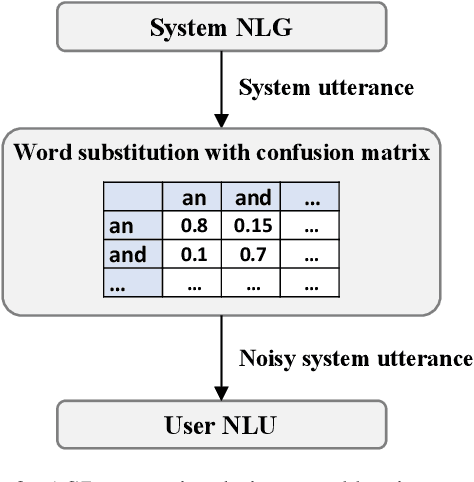
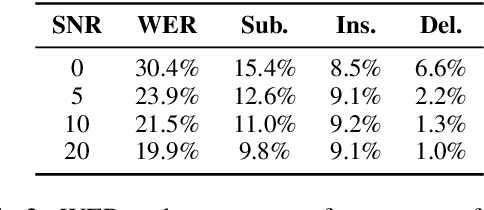
When a natural language generation (NLG) component is implemented in a real-world task-oriented dialogue system, it is necessary to generate not only natural utterances as learned on training data but also utterances adapted to the dialogue environment (e.g., noise from environmental sounds) and the user (e.g., users with low levels of understanding ability). Inspired by recent advances in reinforcement learning (RL) for language generation tasks, we propose ANTOR, a method for Adaptive Natural language generation for Task-Oriented dialogue via Reinforcement learning. In ANTOR, a natural language understanding (NLU) module, which corresponds to the user's understanding of system utterances, is incorporated into the objective function of RL. If the NLG's intentions are correctly conveyed to the NLU, which understands a system's utterances, the NLG is given a positive reward. We conducted experiments on the MultiWOZ dataset, and we confirmed that ANTOR could generate adaptive utterances against speech recognition errors and the different vocabulary levels of users.