 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-processing Networks: Method for Optimizing Pipeline Task-oriented Dialogue Systems using Reinforcement Learning
Paper and Code



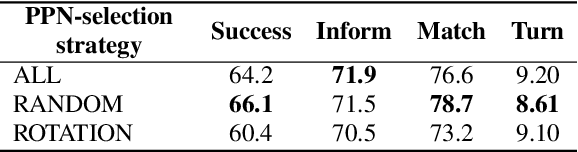
Many studies have proposed methods for optimizing the dialogue performance of an entire pipeline task-oriented dialogue system by jointly training modules in the system using reinforcement learning. However, these methods are limited in that they can only be applied to modules implemented using trainable neural-based methods. To solve this problem, we propose a method for optimizing a pipeline system composed of modules implemented with arbitrary methods for dialogue performance. With our method, neural-based components called post-processing networks (PPNs) are installed inside such a system to post-process the output of each module. All PPNs are updated to improve the overall dialogue performance of the system by using reinforcement learning, not necessitating each module to be differentiable. Through dialogue simulation and human evaluation on the MultiWOZ dataset, we show that our method can improve the dialogue performance of pipeline systems consisting of various modules.