 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJMultiWOZ: A Large-Scale Japanese Multi-Domain Task-Oriented Dialogue Dataset
Mar 26, 2024Dialogue datasets are crucial for deep learning-based task-oriented dialogue system research. While numerous English language multi-domain task-oriented dialogue datasets have been developed and contributed to significant advancements in task-oriented dialogue systems, such a dataset does not exist in Japanese, and research in this area is limited compared to that in English. In this study, towards the advancement of research and development of task-oriented dialogue systems in Japanese, we constructed JMultiWOZ, the first Japanese language large-scale multi-domain task-oriented dialogue dataset. Using JMultiWOZ, we evaluated the dialogue state tracking and response generation capabilities of the state-of-the-art methods on the existing major English benchmark dataset MultiWOZ2.2 and the latest large language model (LLM)-based methods. Our evaluation results demonstrated that JMultiWOZ provides a benchmark that is on par with MultiWOZ2.2. In addition, through evaluation experiments of interactive dialogues with the models and human participants, we identified limitations in the task completion capabilities of LLMs in Japanese.
Team Flow at DRC2023: Building Common Ground and Text-based Turn-taking in a Travel Agent Spoken Dialogue System
Dec 21, 2023At the Dialogue Robot Competition 2023 (DRC2023), which was held to improve the capability of dialogue robots, our team developed a system that could build common ground and take more natural turns based on user utterance texts. Our system generated queries for sightseeing spot searches using the common ground and engaged in dialogue while waiting for user comprehension.
Team Flow at DRC2022: Pipeline System for Travel Destination Recommendation Task in Spoken Dialogue
Oct 18, 2022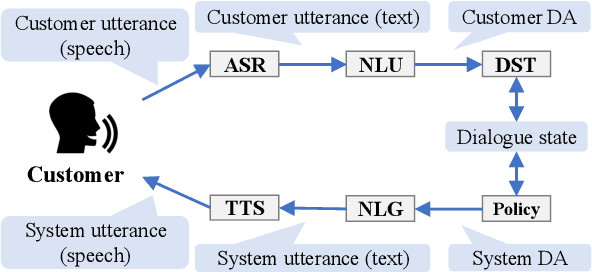



To improve the interactive capabilities of a dialogue system, e.g., to adapt to different customers, the Dialogue Robot Competition (DRC2022) was held. As one of the teams, we built a dialogue system with a pipeline structure containing four modules. The natural language understanding (NLU) and natural language generation (NLG) modules were GPT-2 based models, and the dialogue state tracking (DST) and policy modules were designed on the basis of hand-crafted rules. After the preliminary round of the competition, we found that the low variation in training examples for the NLU and failed recommendation due to the policy used were probably the main reasons for the limited performance of the system.