 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Object-Level Reconstruction via Probabilistic Gaussian Splatting
Mar 15, 2026Object-level 3D reconstruction play important roles across domains such as cultural heritage digitization, industrial manufacturing, and virtual reality. However, existing Gaussian Splatting-based approaches generally rely on full-scene reconstruction, in which substantial redundant background information is introduced, leading to increased computational and storage overhead. To address this limitation, we propose an efficient single-object 3D reconstruction method based on 2D Gaussian Splatting. By directly integrating foreground-background probability cues into Gaussian primitives and dynamically pruning low-probability Gaussians during training, the proposed method fundamentally focuses on an object of interest and improves the memory and computational efficiency. Our pipeline leverages probability masks generated by YOLO and SAM to supervise probabilistic Gaussian attributes, replacing binary masks with continuous probability values to mitigate boundary ambiguity. Additionally, we propose a dual-stage filtering strategy for training's startup to suppress background Gaussians. And, during training, rendered probability masks are conversely employed to refine supervision and enhance boundary consistency across views. Experiments conducted on the MIP-360, T&T, and NVOS datasets demonstrate that our method exhibits strong self-correction capability in the presence of mask errors and achieves reconstruction quality comparable to standard 3DGS approaches, while requiring only approximately 1/10 of their Gaussian amount. These results validate the efficiency and robustness of our method for single-object reconstruction and highlight its potential for applications requiring both high fidelity and computational efficiency.
RadarRGBD A Multi-Sensor Fusion Dataset for Perception with RGB-D and mmWave Radar
May 21, 2025Multi-sensor fusion has significant potential in perception tasks for both indoor and outdoor environments. Especially under challenging conditions such as adverse weather and low-light environments, the combined use of millimeter-wave radar and RGB-D sensors has shown distinct advantages. However, existing multi-sensor datasets in the fields of autonomous driving and robotics often lack high-quality millimeter-wave radar data. To address this gap, we present a new multi-sensor dataset:RadarRGBD. This dataset includes RGB-D data, millimeter-wave radar point clouds, and raw radar matrices, covering various indoor and outdoor scenes, as well as low-light environments. Compared to existing datasets, RadarRGBD employs higher-resolution millimeter-wave radar and provides raw data, offering a new research foundation for the fusion of millimeter-wave radar and visual sensors. Furthermore, to tackle the noise and gaps in depth maps captured by Kinect V2 due to occlusions and mismatches, we fine-tune an open-source relative depth estimation framework, incorporating the absolute depth information from the dataset for depth supervision. We also introduce pseudo-relative depth scale information to further optimize the global depth scale estimation. Experimental results demonstrate that the proposed method effectively fills in missing regions in sensor data. Our dataset and related documentation will be publicly available at: https://github.com/song4399/RadarRGBD.
Team Flow at DRC2023: Building Common Ground and Text-based Turn-taking in a Travel Agent Spoken Dialogue System
Dec 21, 2023At the Dialogue Robot Competition 2023 (DRC2023), which was held to improve the capability of dialogue robots, our team developed a system that could build common ground and take more natural turns based on user utterance texts. Our system generated queries for sightseeing spot searches using the common ground and engaged in dialogue while waiting for user comprehension.
Team Flow at DRC2022: Pipeline System for Travel Destination Recommendation Task in Spoken Dialogue
Oct 18, 2022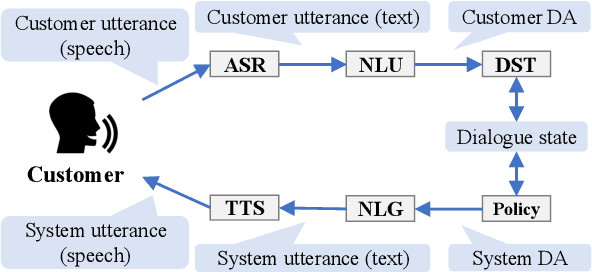



To improve the interactive capabilities of a dialogue system, e.g., to adapt to different customers, the Dialogue Robot Competition (DRC2022) was held. As one of the teams, we built a dialogue system with a pipeline structure containing four modules. The natural language understanding (NLU) and natural language generation (NLG) modules were GPT-2 based models, and the dialogue state tracking (DST) and policy modules were designed on the basis of hand-crafted rules. After the preliminary round of the competition, we found that the low variation in training examples for the NLU and failed recommendation due to the policy used were probably the main reasons for the limited performance of the system.