 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Instruction-Tuning Datasets from Human-Written Instructions with Open-Weight Large Language Models
Mar 31, 2025Instruction tuning is crucial for enabling Large Language Models (LLMs) to solve real-world tasks. Prior work has shown the effectiveness of instruction-tuning data synthesized solely from LLMs, raising a fundamental question: Do we still need human-originated signals for instruction tuning? This work answers the question affirmatively: we build state-of-the-art instruction-tuning datasets sourced from human-written instructions, by simply pairing them with LLM-generated responses. LLMs fine-tuned on our datasets consistently outperform those fine-tuned on existing ones. Our data construction approach can be easily adapted to other languages; we build datasets for Japanese and confirm that LLMs tuned with our data reach state-of-the-art performance. Analyses suggest that instruction-tuning in a new language allows LLMs to follow instructions, while the tuned models exhibit a notable lack of culture-specific knowledge in that language. The datasets and fine-tuned models will be publicly available. Our datasets, synthesized with open-weight LLMs, are openly distributed under permissive licenses, allowing for diverse use cases.
LegalViz: Legal Text Visualization by Text To Diagram Generation
Feb 10, 2025Legal documents including judgments and court orders require highly sophisticated legal knowledge for understanding. To disclose expert knowledge for non-experts, we explore the problem of visualizing legal texts with easy-to-understand diagrams and propose a novel dataset of LegalViz with 23 languages and 7,010 cases of legal document and visualization pairs, using the DOT graph description language of Graphviz. LegalViz provides a simple diagram from a complicated legal corpus identifying legal entities, transactions, legal sources, and statements at a glance, that are essential in each judgment. In addition, we provide new evaluation metrics for the legal diagram visualization by considering graph structures, textual similarities, and legal contents. We conducted empirical studies on few-shot and finetuning large language models for generating legal diagrams and evaluated them with these metrics, including legal content-based evaluation within 23 languages. Models trained with LegalViz outperform existing models including GPTs, confirming the effectiveness of our dataset.
Why We Build Local Large Language Models: An Observational Analysis from 35 Japanese and Multilingual LLMs
Dec 19, 2024



Why do we build local large language models (LLMs)? What should a local LLM learn from the target language? Which abilities can be transferred from other languages? Do language-specific scaling laws exist? To explore these research questions, we evaluated 35 Japanese, English, and multilingual LLMs on 19 evaluation benchmarks for Japanese and English, taking Japanese as a local language. Adopting an observational approach, we analyzed correlations of benchmark scores, and conducted principal component analysis (PCA) on the scores to derive \textit{ability factors} of local LLMs. We found that training on English text can improve the scores of academic subjects in Japanese (JMMLU). In addition, it is unnecessary to specifically train on Japanese text to enhance abilities for solving Japanese code generation, arithmetic reasoning, commonsense, and reading comprehension tasks. In contrast, training on Japanese text could improve question-answering tasks about Japanese knowledge and English-Japanese translation, which indicates that abilities for solving these two tasks can be regarded as \textit{Japanese abilities} for LLMs. Furthermore, we confirmed that the Japanese abilities scale with the computational budget for Japanese text.
Constructing Multimodal Datasets from Scratch for Rapid Development of a Japanese Visual Language Model
Oct 30, 2024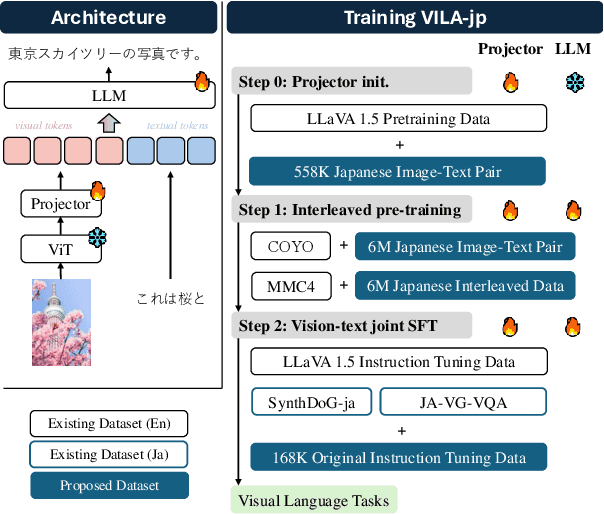
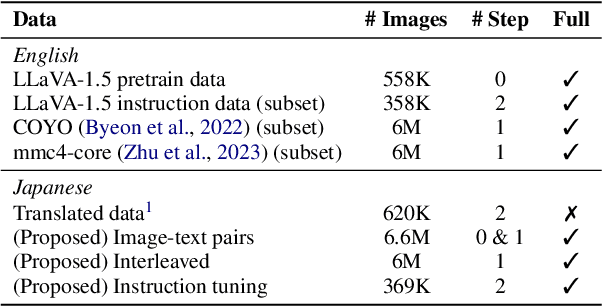
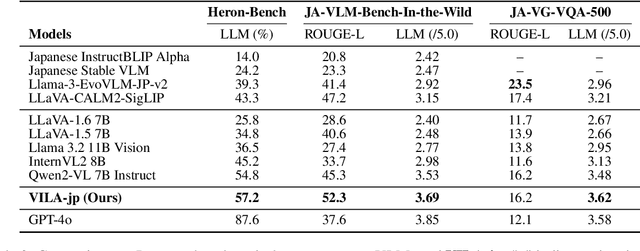

To develop high-performing Visual Language Models (VLMs), it is essential to prepare multimodal resources, such as image-text pairs, interleaved data, and instruction data. While multimodal resources for English are abundant, there is a significant lack of corresponding resources for non-English languages, such as Japanese. To address this problem, we take Japanese as a non-English language and propose a method for rapidly creating Japanese multimodal datasets from scratch. We collect Japanese image-text pairs and interleaved data from web archives and generate Japanese instruction data directly from images using an existing VLM. Our experimental results show that a VLM trained on these native datasets outperforms those relying on machine-translated content.
COM Kitchens: An Unedited Overhead-view Video Dataset as a Vision-Language Benchmark
Aug 05, 2024Procedural video understanding is gaining attention in the vision and language community. Deep learning-based video analysis requires extensive data. Consequently, existing works often use web videos as training resources, making it challenging to query instructional contents from raw video observations. To address this issue, we propose a new dataset, COM Kitchens. The dataset consists of unedited overhead-view videos captured by smartphones, in which participants performed food preparation based on given recipes. Fixed-viewpoint video datasets often lack environmental diversity due to high camera setup costs. We used modern wide-angle smartphone lenses to cover cooking counters from sink to cooktop in an overhead view, capturing activity without in-person assistance. With this setup, we collected a diverse dataset by distributing smartphones to participants. With this dataset, we propose the novel video-to-text retrieval task Online Recipe Retrieval (OnRR) and new video captioning domain Dense Video Captioning on unedited Overhead-View videos (DVC-OV). Our experiments verified the capabilities and limitations of current web-video-based SOTA methods in handling these tasks.
Vision Language Model-based Caption Evaluation Method Leveraging Visual Context Extraction
Feb 28, 2024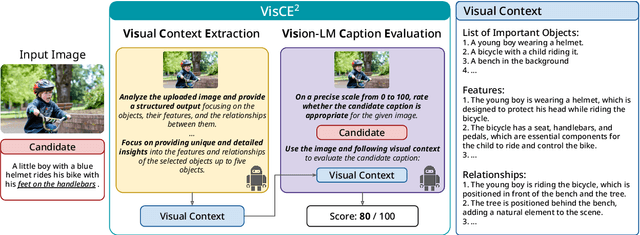
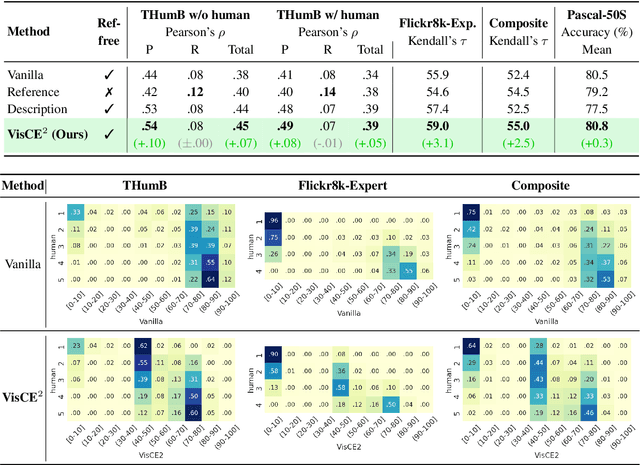
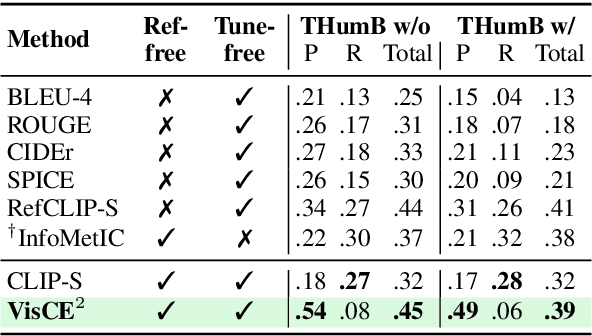
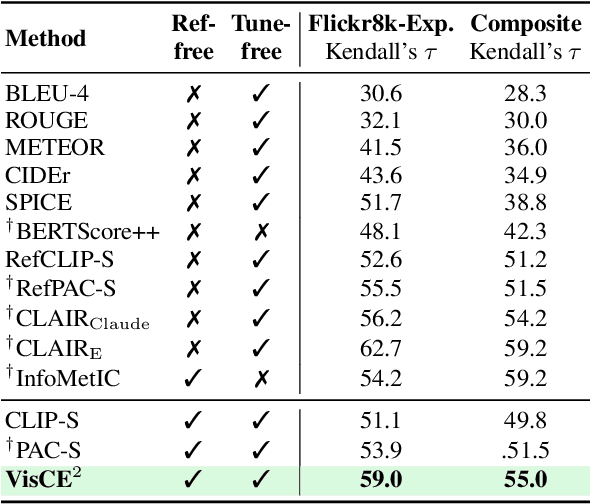
Given the accelerating progress of vision and language modeling, accurate evaluation of machine-generated image captions remains critical. In order to evaluate captions more closely to human preferences, metrics need to discriminate between captions of varying quality and content. However, conventional metrics fail short of comparing beyond superficial matches of words or embedding similarities; thus, they still need improvement. This paper presents VisCE$^2$, a vision language model-based caption evaluation method. Our method focuses on visual context, which refers to the detailed content of images, including objects, attributes, and relationships. By extracting and organizing them into a structured format, we replace the human-written references with visual contexts and help VLMs better understand the image, enhancing evaluation performance. Through meta-evaluation on multiple datasets, we validated that VisCE$^2$ outperforms the conventional pre-trained metrics in capturing caption quality and demonstrates superior consistency with human judgment.