 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegalViz: Legal Text Visualization by Text To Diagram Generation
Feb 10, 2025Legal documents including judgments and court orders require highly sophisticated legal knowledge for understanding. To disclose expert knowledge for non-experts, we explore the problem of visualizing legal texts with easy-to-understand diagrams and propose a novel dataset of LegalViz with 23 languages and 7,010 cases of legal document and visualization pairs, using the DOT graph description language of Graphviz. LegalViz provides a simple diagram from a complicated legal corpus identifying legal entities, transactions, legal sources, and statements at a glance, that are essential in each judgment. In addition, we provide new evaluation metrics for the legal diagram visualization by considering graph structures, textual similarities, and legal contents. We conducted empirical studies on few-shot and finetuning large language models for generating legal diagrams and evaluated them with these metrics, including legal content-based evaluation within 23 languages. Models trained with LegalViz outperform existing models including GPTs, confirming the effectiveness of our dataset.
Answerability Fields: Answerable Location Estimation via Diffusion Models
Jul 26, 2024



In an era characterized by advancements in artificial intelligence and robotics, enabling machines to interact with and understand their environment is a critical research endeavor. In this paper, we propose Answerability Fields, a novel approach to predicting answerability within complex indoor environments. Leveraging a 3D question answering dataset, we construct a comprehensive Answerability Fields dataset, encompassing diverse scenes and questions from ScanNet. Using a diffusion model, we successfully infer and evaluate these Answerability Fields, demonstrating the importance of objects and their locations in answering questions within a scene. Our results showcase the efficacy of Answerability Fields in guiding scene-understanding tasks, laying the foundation for their application in enhancing interactions between intelligent agents and their environments.
CityNav: Language-Goal Aerial Navigation Dataset with Geographic Information
Jun 20, 2024Vision-and-language navigation (VLN) aims to guide autonomous agents through real-world environments by integrating visual and linguistic cues. While substantial progress has been made in understanding these interactive modalities in ground-level navigation, aerial navigation remains largely underexplored. This is primarily due to the scarcity of resources suitable for real-world, city-scale aerial navigation studies. To bridge this gap, we introduce CityNav, a new dataset for language-goal aerial navigation using a 3D point cloud representation from real-world cities. CityNav includes 32,637 natural language descriptions paired with human demonstration trajectories, collected from participants via a new web-based 3D simulator developed for this research. Each description specifies a navigation goal, leveraging the names and locations of landmarks within real-world cities. We also provide baseline models of navigation agents that incorporate an internal 2D spatial map representing landmarks referenced in the descriptions. We benchmark the latest aerial navigation baselines and our proposed model on the CityNav dataset. The results using this dataset reveal the following key findings: (i) Our aerial agent models trained on human demonstration trajectories outperform those trained on shortest path trajectories, highlighting the importance of human-driven navigation strategies; (ii) The integration of a 2D spatial map significantly enhances navigation efficiency at city scale. Our dataset and code are available at https://water-cookie.github.io/city-nav-proj/
Map-based Modular Approach for Zero-shot Embodied Question Answering
May 26, 2024Building robots capable of interacting with humans through natural language in the visual world presents a significant challenge in the field of robotics. To overcome this challenge, Embodied Question Answering (EQA) has been proposed as a benchmark task to measure the ability to identify an object navigating through a previously unseen environment in response to human-posed questions. Although some methods have been proposed, their evaluations have been limited to simulations, without experiments in real-world scenarios. Furthermore, all of these methods are constrained by a limited vocabulary for question-and-answer interactions, making them unsuitable for practical applications. In this work, we propose a map-based modular EQA method that enables real robots to navigate unknown environments through frontier-based map creation and address unknown QA pairs using foundation models that support open vocabulary. Unlike the questions of the previous EQA dataset on Matterport 3D (MP3D), questions in our real-world experiments contain various question formats and vocabularies not included in the training data. We conduct comprehensive experiments on virtual environments (MP3D-EQA) and two real-world house environments and demonstrate that our method can perform EQA even in the real world.
JDocQA: Japanese Document Question Answering Dataset for Generative Language Models
Mar 28, 2024



Document question answering is a task of question answering on given documents such as reports, slides, pamphlets, and websites, and it is a truly demanding task as paper and electronic forms of documents are so common in our society. This is known as a quite challenging task because it requires not only text understanding but also understanding of figures and tables, and hence visual question answering (VQA) methods are often examined in addition to textual approaches. We introduce Japanese Document Question Answering (JDocQA), a large-scale document-based QA dataset, essentially requiring both visual and textual information to answer questions, which comprises 5,504 documents in PDF format and annotated 11,600 question-and-answer instances in Japanese. Each QA instance includes references to the document pages and bounding boxes for the answer clues. We incorporate multiple categories of questions and unanswerable questions from the document for realistic question-answering applications. We empirically evaluate the effectiveness of our dataset with text-based large language models (LLMs) and multimodal models. Incorporating unanswerable questions in finetuning may contribute to harnessing the so-called hallucination generation.
Vision Language Model-based Caption Evaluation Method Leveraging Visual Context Extraction
Feb 28, 2024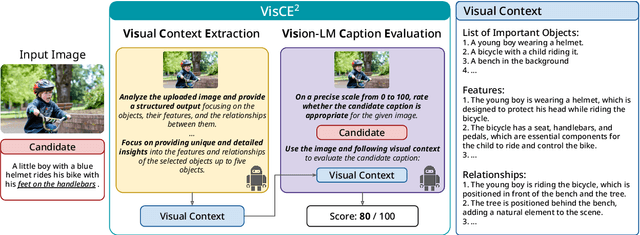
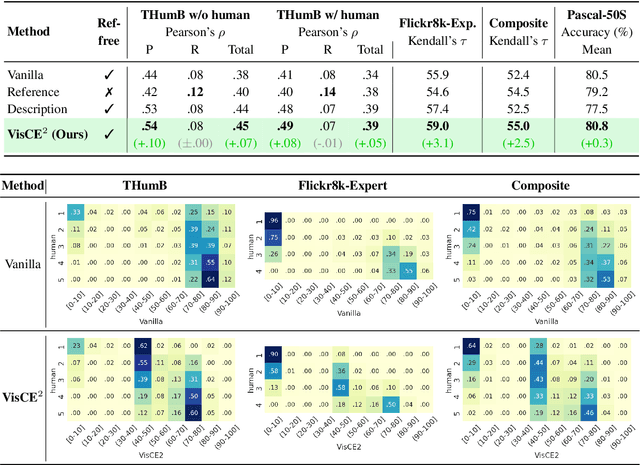
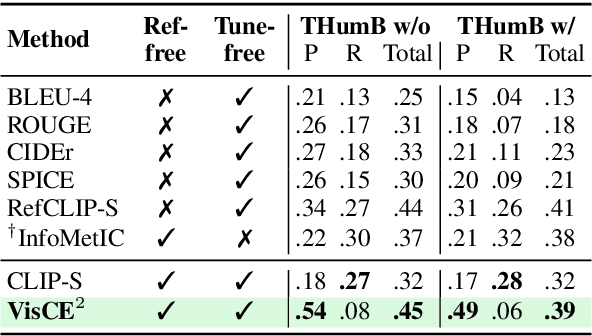
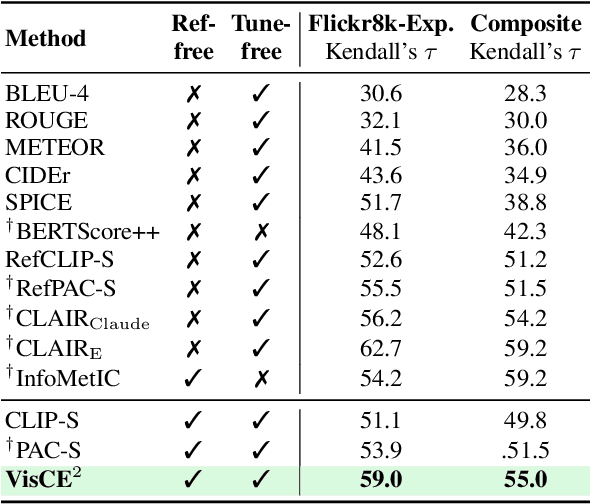
Given the accelerating progress of vision and language modeling, accurate evaluation of machine-generated image captions remains critical. In order to evaluate captions more closely to human preferences, metrics need to discriminate between captions of varying quality and content. However, conventional metrics fail short of comparing beyond superficial matches of words or embedding similarities; thus, they still need improvement. This paper presents VisCE$^2$, a vision language model-based caption evaluation method. Our method focuses on visual context, which refers to the detailed content of images, including objects, attributes, and relationships. By extracting and organizing them into a structured format, we replace the human-written references with visual contexts and help VLMs better understand the image, enhancing evaluation performance. Through meta-evaluation on multiple datasets, we validated that VisCE$^2$ outperforms the conventional pre-trained metrics in capturing caption quality and demonstrates superior consistency with human judgment.
CityRefer: Geography-aware 3D Visual Grounding Dataset on City-scale Point Cloud Data
Oct 28, 2023City-scale 3D point cloud is a promising way to express detailed and complicated outdoor structures. It encompasses both the appearance and geometry features of segmented city components, including cars, streets, and buildings, that can be utilized for attractive applications such as user-interactive navigation of autonomous vehicles and drones. However, compared to the extensive text annotations available for images and indoor scenes, the scarcity of text annotations for outdoor scenes poses a significant challenge for achieving these applications. To tackle this problem, we introduce the CityRefer dataset for city-level visual grounding. The dataset consists of 35k natural language descriptions of 3D objects appearing in SensatUrban city scenes and 5k landmarks labels synchronizing with OpenStreetMap. To ensure the quality and accuracy of the dataset, all descriptions and labels in the CityRefer dataset are manually verified. We also have developed a baseline system that can learn encoded language descriptions, 3D object instances, and geographical information about the city's landmarks to perform visual grounding on the CityRefer dataset. To the best of our knowledge, the CityRefer dataset is the largest city-level visual grounding dataset for localizing specific 3D objects.
Cross3DVG: Baseline and Dataset for Cross-Dataset 3D Visual Grounding on Different RGB-D Scans
May 23, 2023We present Cross3DVG, a novel task for cross-dataset visual grounding in 3D scenes, revealing the limitations of existing 3D visual grounding models using restricted 3D resources and thus easily overfit to a specific 3D dataset. To facilitate Cross3DVG, we have created a large-scale 3D visual grounding dataset containing more than 63k diverse descriptions of 3D objects within 1,380 indoor RGB-D scans from 3RScan with human annotations, paired with the existing 52k descriptions on ScanRefer. We perform Cross3DVG by training a model on the source 3D visual grounding dataset and then evaluating it on the target dataset constructed in different ways (e.g., different sensors, 3D reconstruction methods, and language annotators) without using target labels. We conduct comprehensive experiments using established visual grounding models, as well as a CLIP-based 2D-3D integration method, designed to bridge the gaps between 3D datasets. By performing Cross3DVG tasks, we found that (i) cross-dataset 3D visual grounding has significantly lower performance than learning and evaluation with a single dataset, suggesting much room for improvement in cross-dataset generalization of 3D visual grounding, (ii) better detectors and transformer-based localization modules for 3D grounding are beneficial for enhancing 3D grounding performance and (iii) fusing 2D-3D data using CLIP demonstrates further performance improvements. Our Cross3DVG task will provide a benchmark for developing robust 3D visual grounding models capable of handling diverse 3D scenes while leveraging deep language understanding.
ScanQA: 3D Question Answering for Spatial Scene Understanding
Dec 20, 2021



We propose a new 3D spatial understanding task of 3D Question Answering (3D-QA). In the 3D-QA task, models receive visual information from the entire 3D scene of the rich RGB-D indoor scan and answer the given textual questions about the 3D scene. Unlike the 2D-question answering of VQA, the conventional 2D-QA models suffer from problems with spatial understanding of object alignment and directions and fail the object localization from the textual questions in 3D-QA. We propose a baseline model for 3D-QA, named ScanQA model, where the model learns a fused descriptor from 3D object proposals and encoded sentence embeddings. This learned descriptor correlates the language expressions with the underlying geometric features of the 3D scan and facilitates the regression of 3D bounding boxes to determine described objects in textual questions. We collected human-edited question-answer pairs with free-form answers that are grounded to 3D objects in each 3D scene. Our new ScanQA dataset contains over 41K question-answer pairs from the 800 indoor scenes drawn from the ScanNet dataset. To the best of our knowledge, ScanQA is the first large-scale effort to perform object-grounded question-answering in 3D environments.