 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Language Model-based Caption Evaluation Method Leveraging Visual Context Extraction
Paper and Code
Feb 28, 2024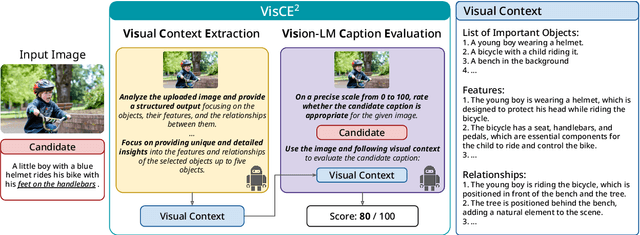
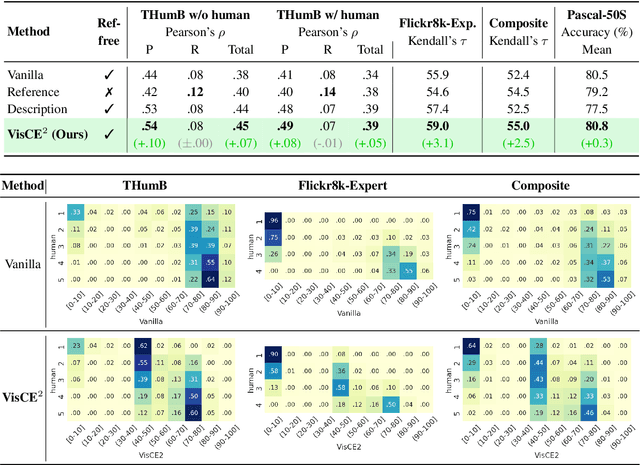
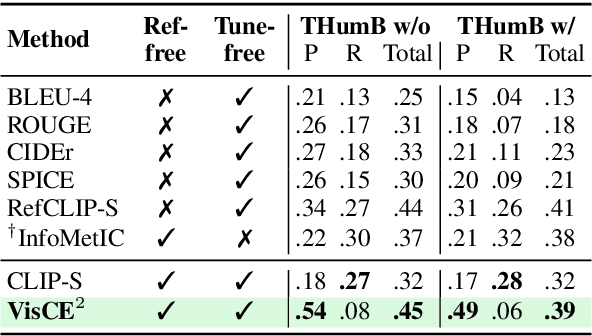
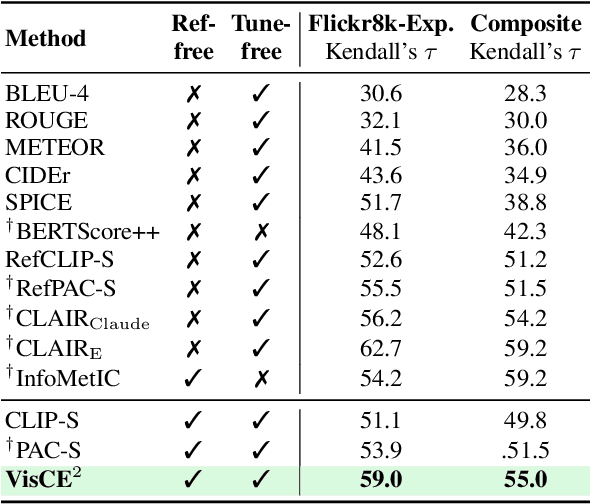
Given the accelerating progress of vision and language modeling, accurate evaluation of machine-generated image captions remains critical. In order to evaluate captions more closely to human preferences, metrics need to discriminate between captions of varying quality and content. However, conventional metrics fail short of comparing beyond superficial matches of words or embedding similarities; thus, they still need improvement. This paper presents VisCE$^2$, a vision language model-based caption evaluation method. Our method focuses on visual context, which refers to the detailed content of images, including objects, attributes, and relationships. By extracting and organizing them into a structured format, we replace the human-written references with visual contexts and help VLMs better understand the image, enhancing evaluation performance. Through meta-evaluation on multiple datasets, we validated that VisCE$^2$ outperforms the conventional pre-trained metrics in capturing caption quality and demonstrates superior consistency with human judgment.