 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Interpretability to Performance: Optimizing Retrieval Heads for Long-Context Language Models
Jan 16, 2026Advances in mechanistic interpretability have identified special attention heads, known as retrieval heads, that are responsible for retrieving information from the context. However, the role of these retrieval heads in improving model performance remains unexplored. This work investigates whether retrieval heads can be leveraged to enhance the long-context capabilities of LLMs. Specifically, we propose RetMask, a method that generates training signals by contrasting normal model outputs with those from an ablated variant in which the retrieval heads are masked. This mechanism-based approach achieves substantial improvements: +2.28 points on HELMET at 128K for Llama-3.1, with +70% gains on generation with citation and +32% on passage re-ranking, while preserving performance on general tasks. Experiments across three model families reveal that the effectiveness depends on retrieval head organization: models with concentrated patterns of retrieval heads respond strongly, while those with distributed patterns show limited gains. This mechanistic relationship validates the function of retrieval heads and demonstrates that mechanistic insights can be transformed into performance enhancements.
Rewriting Pre-Training Data Boosts LLM Performance in Math and Code
May 05, 2025The performance of large language models (LLMs) in program synthesis and mathematical reasoning is fundamentally limited by the quality of their pre-training corpora. We introduce two openly licensed datasets, released under the Llama 3.3 Community License, that significantly enhance LLM performance by systematically rewriting public data. SwallowCode (approximately 16.1 billion tokens) refines Python snippets from The-Stack-v2 through a novel four-stage pipeline: syntax validation, pylint-based style filtering, and a two-stage LLM rewriting process that enforces style conformity and transforms snippets into self-contained, algorithmically efficient examples. Unlike prior methods that rely on exclusionary filtering or limited transformations, our transform-and-retain approach upgrades low-quality code, maximizing data utility. SwallowMath (approximately 2.3 billion tokens) enhances Finemath-4+ by removing boilerplate, restoring context, and reformatting solutions into concise, step-by-step explanations. Within a fixed 50 billion token training budget, continual pre-training of Llama-3.1-8B with SwallowCode boosts pass@1 by +17.0 on HumanEval and +17.7 on HumanEval+ compared to Stack-Edu, surpassing the baseline model's code generation capabilities. Similarly, substituting SwallowMath yields +12.4 accuracy on GSM8K and +7.6 on MATH. Ablation studies confirm that each pipeline stage contributes incrementally, with rewriting delivering the largest gains. All datasets, prompts, and checkpoints are publicly available, enabling reproducible research and advancing LLM pre-training for specialized domains.
Building Instruction-Tuning Datasets from Human-Written Instructions with Open-Weight Large Language Models
Mar 31, 2025Instruction tuning is crucial for enabling Large Language Models (LLMs) to solve real-world tasks. Prior work has shown the effectiveness of instruction-tuning data synthesized solely from LLMs, raising a fundamental question: Do we still need human-originated signals for instruction tuning? This work answers the question affirmatively: we build state-of-the-art instruction-tuning datasets sourced from human-written instructions, by simply pairing them with LLM-generated responses. LLMs fine-tuned on our datasets consistently outperform those fine-tuned on existing ones. Our data construction approach can be easily adapted to other languages; we build datasets for Japanese and confirm that LLMs tuned with our data reach state-of-the-art performance. Analyses suggest that instruction-tuning in a new language allows LLMs to follow instructions, while the tuned models exhibit a notable lack of culture-specific knowledge in that language. The datasets and fine-tuned models will be publicly available. Our datasets, synthesized with open-weight LLMs, are openly distributed under permissive licenses, allowing for diverse use cases.
Why We Build Local Large Language Models: An Observational Analysis from 35 Japanese and Multilingual LLMs
Dec 19, 2024



Why do we build local large language models (LLMs)? What should a local LLM learn from the target language? Which abilities can be transferred from other languages? Do language-specific scaling laws exist? To explore these research questions, we evaluated 35 Japanese, English, and multilingual LLMs on 19 evaluation benchmarks for Japanese and English, taking Japanese as a local language. Adopting an observational approach, we analyzed correlations of benchmark scores, and conducted principal component analysis (PCA) on the scores to derive \textit{ability factors} of local LLMs. We found that training on English text can improve the scores of academic subjects in Japanese (JMMLU). In addition, it is unnecessary to specifically train on Japanese text to enhance abilities for solving Japanese code generation, arithmetic reasoning, commonsense, and reading comprehension tasks. In contrast, training on Japanese text could improve question-answering tasks about Japanese knowledge and English-Japanese translation, which indicates that abilities for solving these two tasks can be regarded as \textit{Japanese abilities} for LLMs. Furthermore, we confirmed that the Japanese abilities scale with the computational budget for Japanese text.
Building a Japanese Document-Level Relation Extraction Dataset Assisted by Cross-Lingual Transfer
Apr 25, 2024



Document-level Relation Extraction (DocRE) is the task of extracting all semantic relationships from a document. While studies have been conducted on English DocRE, limited attention has been given to DocRE in non-English languages. This work delves into effectively utilizing existing English resources to promote DocRE studies in non-English languages, with Japanese as the representative case. As an initial attempt, we construct a dataset by transferring an English dataset to Japanese. However, models trained on such a dataset suffer from low recalls. We investigate the error cases and attribute the failure to different surface structures and semantics of documents translated from English and those written by native speakers. We thus switch to explore if the transferred dataset can assist human annotation on Japanese documents. In our proposal, annotators edit relation predictions from a model trained on the transferred dataset. Quantitative analysis shows that relation recommendations suggested by the model help reduce approximately 50% of the human edit steps compared with the previous approach. Experiments quantify the performance of existing DocRE models on our collected dataset, portraying the challenges of Japanese and cross-lingual DocRE.
Sampling-based Pseudo-Likelihood for Membership Inference Attacks
Apr 17, 2024Large Language Models (LLMs) are trained on large-scale web data, which makes it difficult to grasp the contribution of each text. This poses the risk of leaking inappropriate data such as benchmarks, personal information, and copyrighted texts in the training data. Membership Inference Attacks (MIA), which determine whether a given text is included in the model's training data, have been attracting attention. Previous studies of MIAs revealed that likelihood-based classification is effective for detecting leaks in LLMs. However, the existing methods cannot be applied to some proprietary models like ChatGPT or Claude 3 because the likelihood is unavailable to the user. In this study, we propose a Sampling-based Pseudo-Likelihood (\textbf{SPL}) method for MIA (\textbf{SaMIA}) that calculates SPL using only the text generated by an LLM to detect leaks. The SaMIA treats the target text as the reference text and multiple outputs from the LLM as text samples, calculates the degree of $n$-gram match as SPL, and determines the membership of the text in the training data. Even without likelihoods, SaMIA performed on par with existing likelihood-based methods.
DREEAM: Guiding Attention with Evidence for Improving Document-Level Relation Extraction
Feb 17, 2023

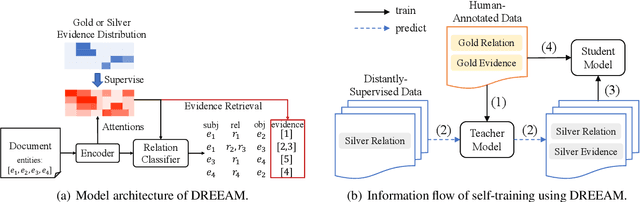
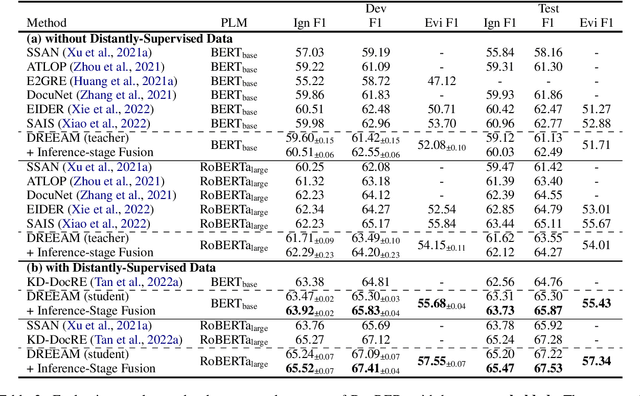
Document-level relation extraction (DocRE) is the task of identifying all relations between each entity pair in a document. Evidence, defined as sentences containing clues for the relationship between an entity pair, has been shown to help DocRE systems focus on relevant texts, thus improving relation extraction. However, evidence retrieval (ER) in DocRE faces two major issues: high memory consumption and limited availability of annotations. This work aims at addressing these issues to improve the usage of ER in DocRE. First, we propose DREEAM, a memory-efficient approach that adopts evidence information as the supervisory signal, thereby guiding the attention modules of the DocRE system to assign high weights to evidence. Second, we propose a self-training strategy for DREEAM to learn ER from automatically-generated evidence on massive data without evidence annotations. Experimental results reveal that our approach exhibits state-of-the-art performance on the DocRED benchmark for both DocRE and ER. To the best of our knowledge, DREEAM is the first approach to employ ER self-training.
Named Entity Recognition and Relation Extraction using Enhanced Table Filling by Contextualized Representations
Oct 15, 2020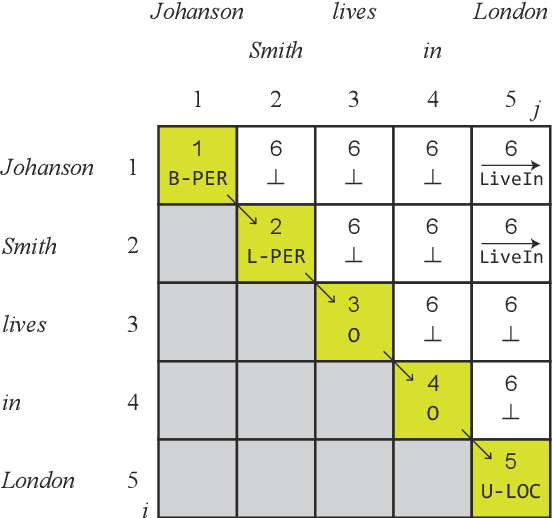
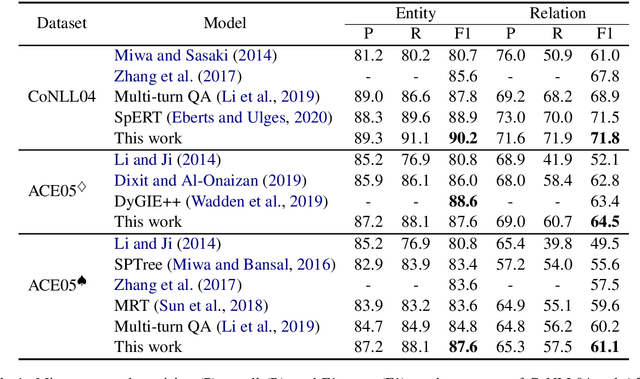
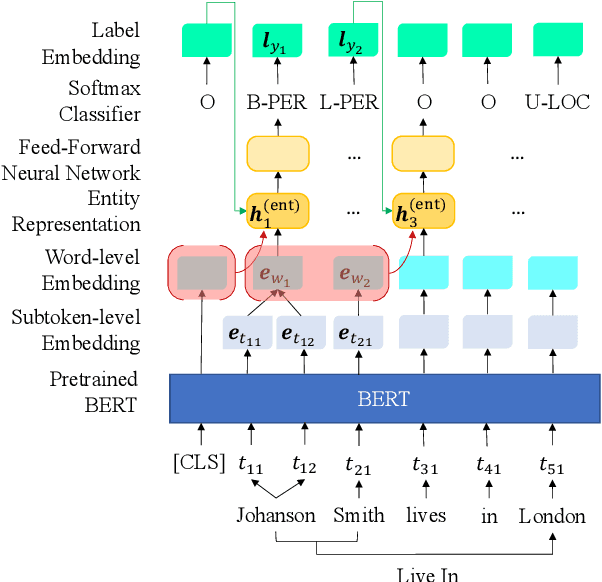
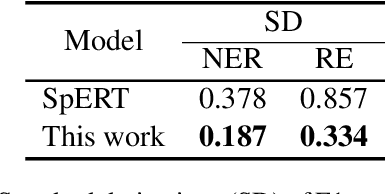
In this study, a novel method for extracting named entities and relations from unstructured text based on the table representation is presented. By using contextualized word embeddings, the proposed method computes representations for entity mentions and long-range dependencies without complicated hand-crafted features or neural-network architectures. We also adapt a tensor dot-product to predict relation labels all at once without resorting to history-based predictions or search strategies. These advances significantly simplify the model and algorithm for the extraction of named entities and relations. Despite its simplicity, the experimental results demonstrate that the proposed method outperforms the state-of-the-art methods on the CoNLL04 and ACE05 English datasets. We also confirm that the proposed method achieves a comparable performance with the state-of-the-art NER models on the ACE05 datasets when multiple sentences are provided for context aggregation.