 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNamed Entity Recognition and Relation Extraction using Enhanced Table Filling by Contextualized Representations
Paper and Code
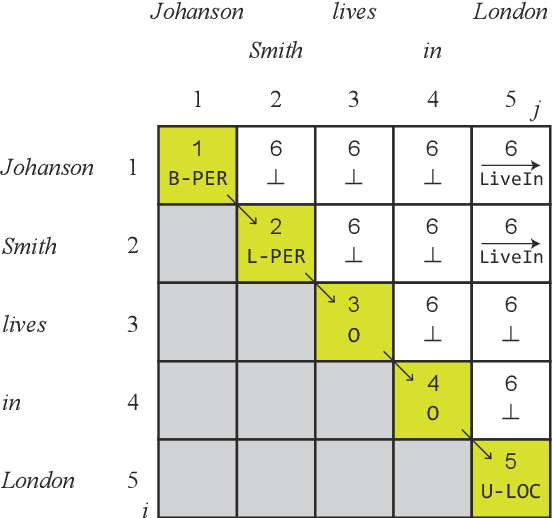
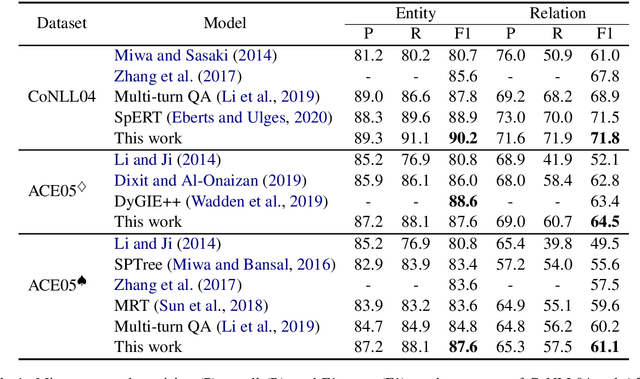
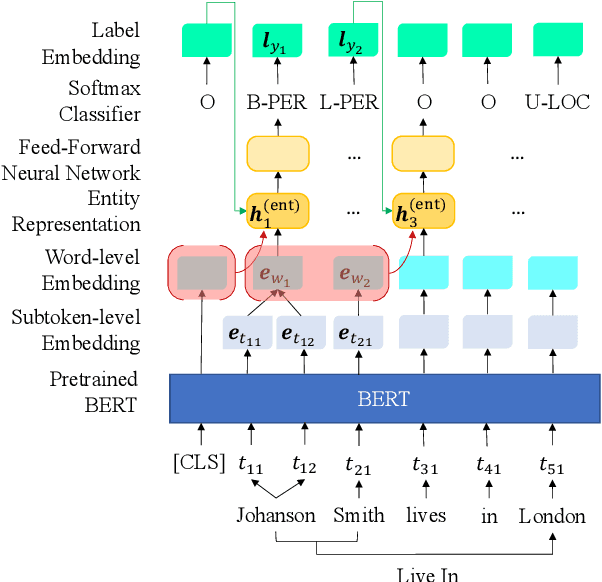
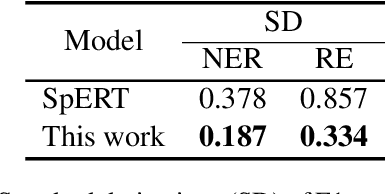
In this study, a novel method for extracting named entities and relations from unstructured text based on the table representation is presented. By using contextualized word embeddings, the proposed method computes representations for entity mentions and long-range dependencies without complicated hand-crafted features or neural-network architectures. We also adapt a tensor dot-product to predict relation labels all at once without resorting to history-based predictions or search strategies. These advances significantly simplify the model and algorithm for the extraction of named entities and relations. Despite its simplicity, the experimental results demonstrate that the proposed method outperforms the state-of-the-art methods on the CoNLL04 and ACE05 English datasets. We also confirm that the proposed method achieves a comparable performance with the state-of-the-art NER models on the ACE05 datasets when multiple sentences are provided for context aggregation.