 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing Multimodal Datasets from Scratch for Rapid Development of a Japanese Visual Language Model
Oct 30, 2024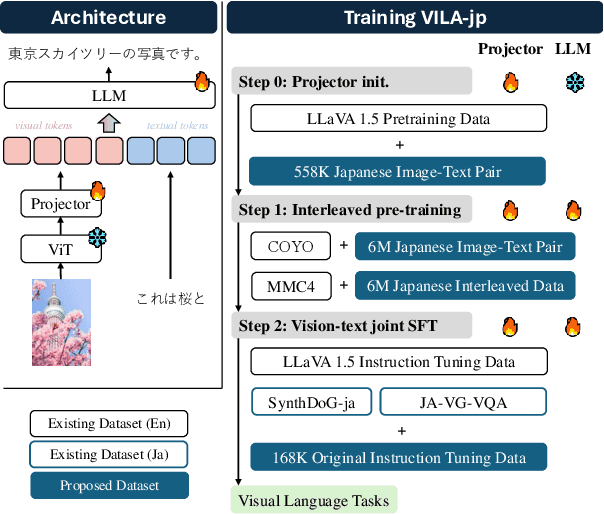
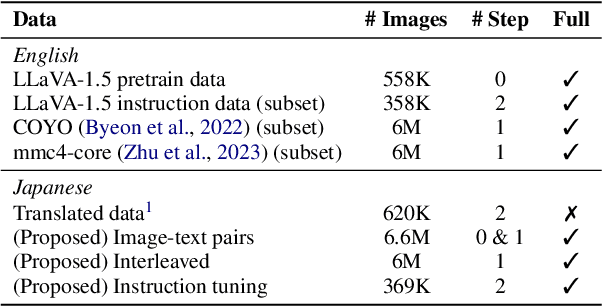
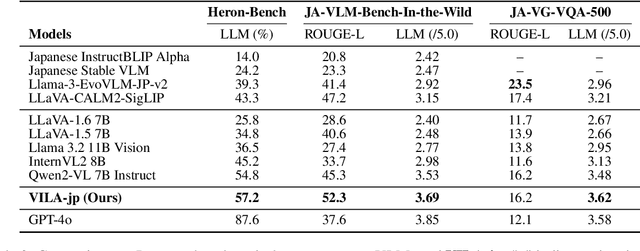

To develop high-performing Visual Language Models (VLMs), it is essential to prepare multimodal resources, such as image-text pairs, interleaved data, and instruction data. While multimodal resources for English are abundant, there is a significant lack of corresponding resources for non-English languages, such as Japanese. To address this problem, we take Japanese as a non-English language and propose a method for rapidly creating Japanese multimodal datasets from scratch. We collect Japanese image-text pairs and interleaved data from web archives and generate Japanese instruction data directly from images using an existing VLM. Our experimental results show that a VLM trained on these native datasets outperforms those relying on machine-translated content.