 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISCODE: Distribution-Aware Score Decoder for Robust Automatic Evaluation of Image Captioning
Dec 16, 2025Large vision-language models (LVLMs) have shown impressive performance across a broad range of multimodal tasks. However, robust image caption evaluation using LVLMs remains challenging, particularly under domain-shift scenarios. To address this issue, we introduce the Distribution-Aware Score Decoder (DISCODE), a novel finetuning-free method that generates robust evaluation scores better aligned with human judgments across diverse domains. The core idea behind DISCODE lies in its test-time adaptive evaluation approach, which introduces the Adaptive Test-Time (ATT) loss, leveraging a Gaussian prior distribution to improve robustness in evaluation score estimation. This loss is efficiently minimized at test time using an analytical solution that we derive. Furthermore, we introduce the Multi-domain Caption Evaluation (MCEval) benchmark, a new image captioning evaluation benchmark covering six distinct domains, designed to assess the robustness of evaluation metrics. In our experiments, we demonstrate that DISCODE achieves state-of-the-art performance as a reference-free evaluation metric across MCEval and four representative existing benchmarks.
GUMBEL-NERF: Representing Unseen Objects as Part-Compositional Neural Radiance Fields
Oct 27, 2024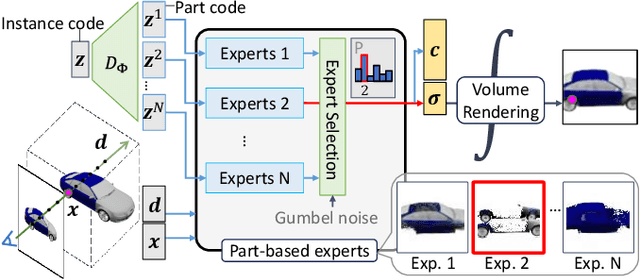
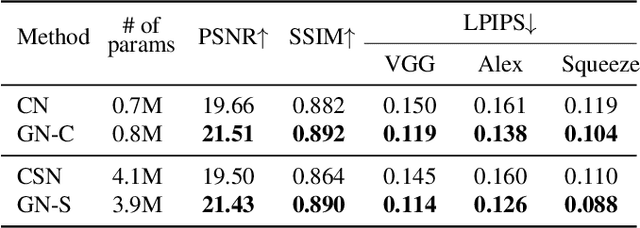
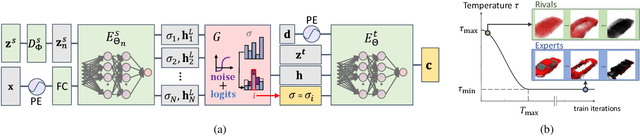
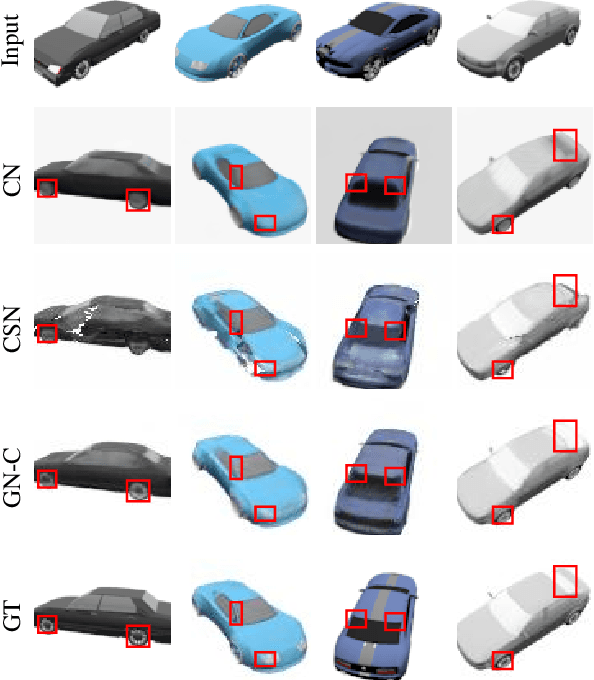
We propose Gumbel-NeRF, a mixture-of-expert (MoE) neural radiance fields (NeRF) model with a hindsight expert selection mechanism for synthesizing novel views of unseen objects. Previous studies have shown that the MoE structure provides high-quality representations of a given large-scale scene consisting of many objects. However, we observe that such a MoE NeRF model often produces low-quality representations in the vicinity of experts' boundaries when applied to the task of novel view synthesis of an unseen object from one/few-shot input. We find that this deterioration is primarily caused by the foresight expert selection mechanism, which may leave an unnatural discontinuity in the object shape near the experts' boundaries. Gumbel-NeRF adopts a hindsight expert selection mechanism, which guarantees continuity in the density field even near the experts' boundaries. Experiments using the SRN cars dataset demonstrate the superiority of Gumbel-NeRF over the baselines in terms of various image quality metrics.
Event-based Camera Tracker by $ abla$t NeRF
Apr 07, 2023When a camera travels across a 3D world, only a fraction of pixel value changes; an event-based camera observes the change as sparse events. How can we utilize sparse events for efficient recovery of the camera pose? We show that we can recover the camera pose by minimizing the error between sparse events and the temporal gradient of the scene represented as a neural radiance field (NeRF). To enable the computation of the temporal gradient of the scene, we augment NeRF's camera pose as a time function. When the input pose to the NeRF coincides with the actual pose, the output of the temporal gradient of NeRF equals the observed intensity changes on the event's points. Using this principle, we propose an event-based camera pose tracking framework called TeGRA which realizes the pose update by using the sparse event's observation. To the best of our knowledge, this is the first camera pose estimation algorithm using the scene's implicit representation and the sparse intensity change from events.
Toward Unsupervised 3D Point Cloud Anomaly Detection using Variational Autoencoder
Apr 07, 2023



In this paper, we present an end-to-end unsupervised anomaly detection framework for 3D point clouds. To the best of our knowledge, this is the first work to tackle the anomaly detection task on a general object represented by a 3D point cloud. We propose a deep variational autoencoder-based unsupervised anomaly detection network adapted to the 3D point cloud and an anomaly score specifically for 3D point clouds. To verify the effectiveness of the model, we conducted extensive experiments on the ShapeNet dataset. Through quantitative and qualitative evaluation, we demonstrate that the proposed method outperforms the baseline method. Our code is available at https://github.com/llien30/point_cloud_anomaly_detection.
Implicit Neural Representations for Variable Length Human Motion Generation
Mar 25, 2022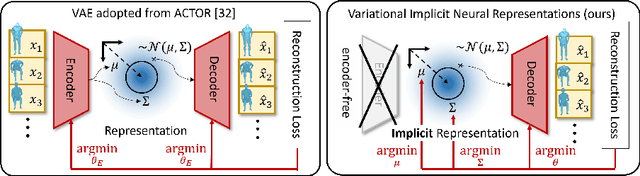
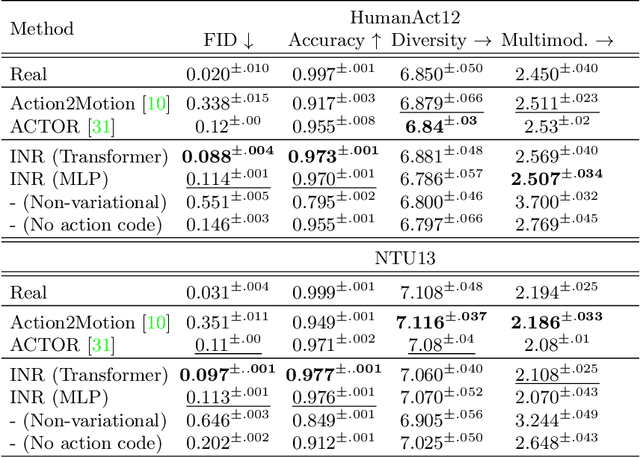
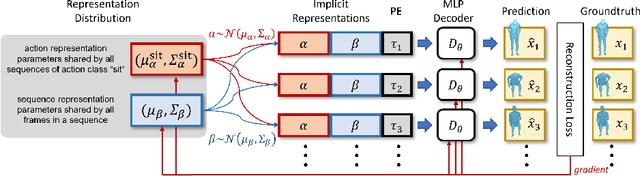

We propose an action-conditional human motion generation method using variational implicit neural representations (INR). The variational formalism enables action-conditional distributions of INRs, from which one can easily sample representations to generate novel human motion sequences. Our method offers variable-length sequence generation by construction because a part of INR is optimized for a whole sequence of arbitrary length with temporal embeddings. In contrast, previous works reported difficulties with modeling variable-length sequences. We confirm that our method with a Transformer decoder outperforms all relevant methods on HumanAct12, NTU-RGBD, and UESTC datasets in terms of realism and diversity of generated motions. Surprisingly, even our method with an MLP decoder consistently outperforms the state-of-the-art Transformer-based auto-encoder. In particular, we show that variable-length motions generated by our method are better than fixed-length motions generated by the state-of-the-art method in terms of realism and diversity.
Neural Implicit Event Generator for Motion Tracking
Nov 06, 2021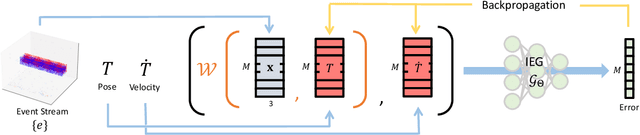



We present a novel framework of motion tracking from event data using implicit expression. Our framework use pre-trained event generation MLP named implicit event generator (IEG) and does motion tracking by updating its state (position and velocity) based on the difference between the observed event and generated event from the current state estimate. The difference is computed implicitly by the IEG. Unlike the conventional explicit approach, which requires dense computation to evaluate the difference, our implicit approach realizes efficient state update directly from sparse event data. Our sparse algorithm is especially suitable for mobile robotics applications where computational resources and battery life are limited. To verify the effectiveness of our method on real-world data, we applied it to the AR marker tracking application. We have confirmed that our framework works well in real-world environments in the presence of noise and background clutter.
Irregularly Tabulated MLP for Fast Point Feature Embedding
Nov 13, 2020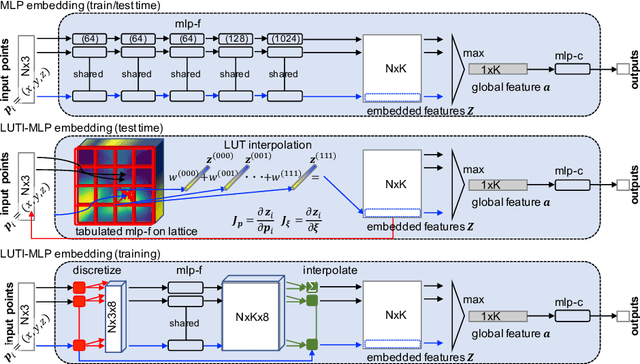
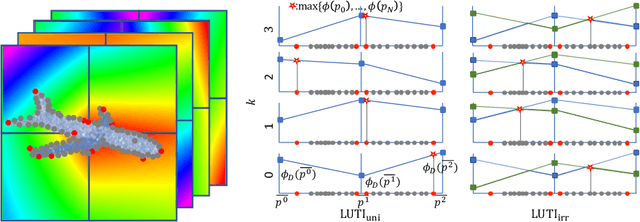
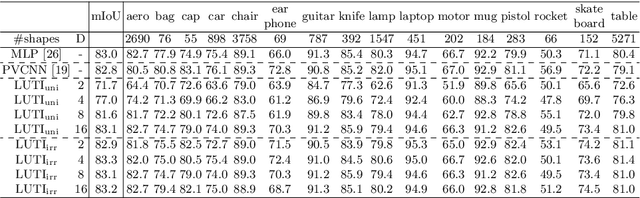
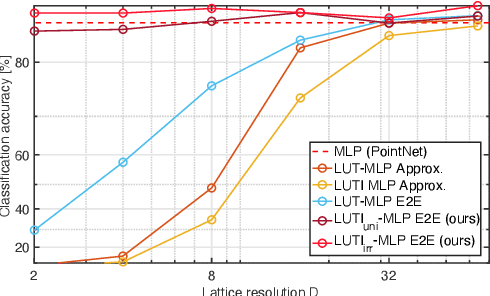
Aiming at drastic speedup for point-feature embeddings at test time, we propose a new framework that uses a pair of multi-layer perceptrons (MLP) and a lookup table (LUT) to transform point-coordinate inputs into high-dimensional features. When compared with PointNet's feature embedding part realized by MLP that requires millions of dot products, the proposed framework at test time requires no such layers of matrix-vector products but requires only looking up the nearest entities from the tabulated MLP followed by interpolation, defined over discrete inputs on a 3D lattice that is substantially arranged irregularly. We call this framework LUTI-MLP: LUT Interpolation ML that provides a way to train end-to-end irregularly tabulated MLP coupled to a LUT in a specific manner without the need for any approximation at test time. LUTI-MLP also provides significant speedup for Jacobian computation of the embedding function wrt global pose coordinate on Lie algebra $\mathfrak{se}(3)$ at test time, which could be used for point-set registration problems. After extensive evaluation using the ModelNet40, we confirmed that the LUTI-MLP even with a small (e.g., $4^3$) lattice yields performance comparable to that of the MLP while achieving significant speedup: $100\times$ for the embedding, $12\times$ for the approximate Jacobian, and $860\times$ for the canonical Jacobian.
Rethinking PointNet Embedding for Faster and Compact Model
Jul 31, 2020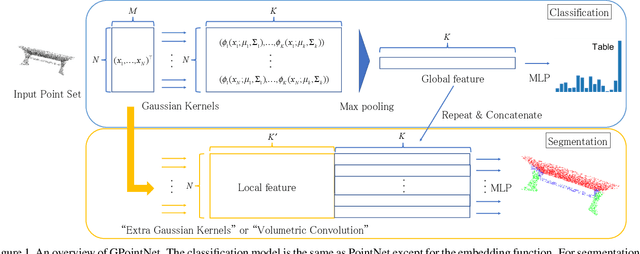
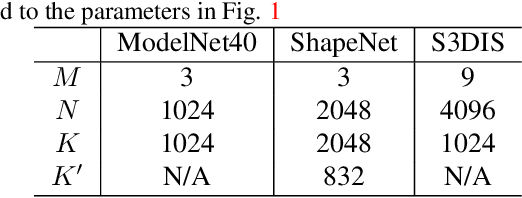
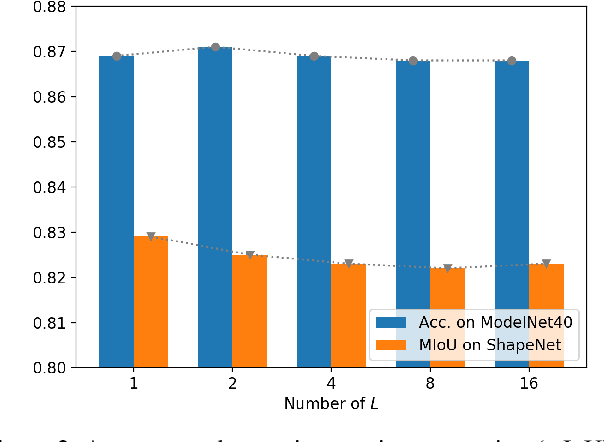
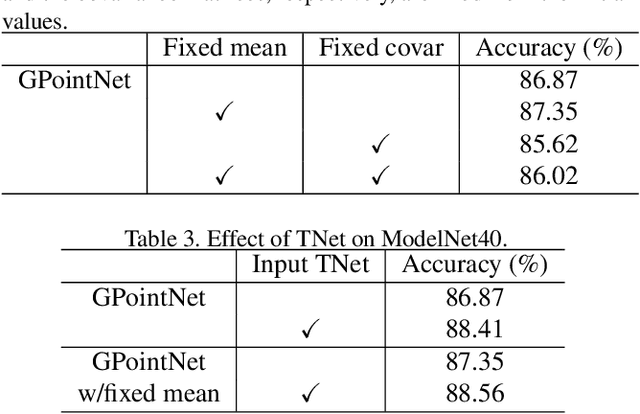
PointNet, which is the widely used point-wise embedding method and known as a universal approximator for continuous set functions, can process one million points per second. Nevertheless, real-time inference for the recent development of high-performing sensors is still challenging with existing neural network-based methods, including PointNet. In ordinary cases, the embedding function of PointNet behaves like a soft-indicator function that is activated when the input points exist in a certain local region of the input space. Leveraging this property, we reduce the computational costs of point-wise embedding by replacing the embedding function of PointNet with the soft-indicator function by Gaussian kernels. Moreover, we show that the Gaussian kernels also satisfy the universal approximation theorem that PointNet satisfies. In experiments, we verify that our model using the Gaussian kernels achieves comparable results to baseline methods, but with much fewer floating-point operations per sample up to 92\% reduction from PointNet.
Tabulated MLP for Fast Point Feature Embedding
Nov 23, 2019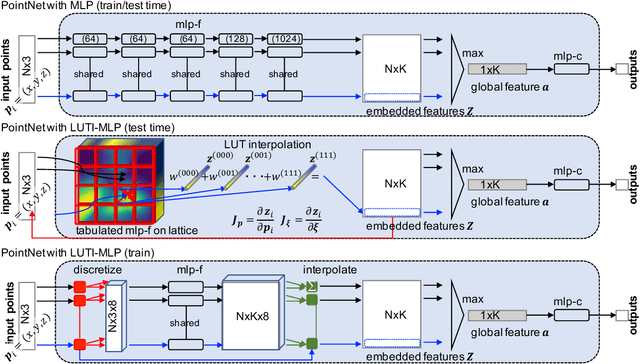
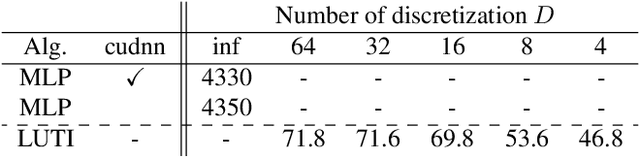
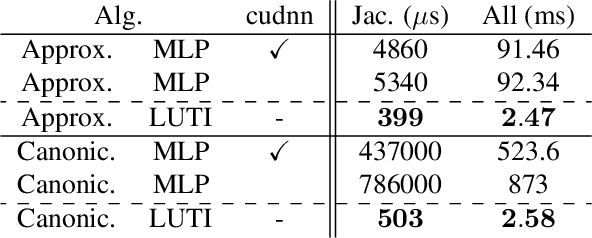
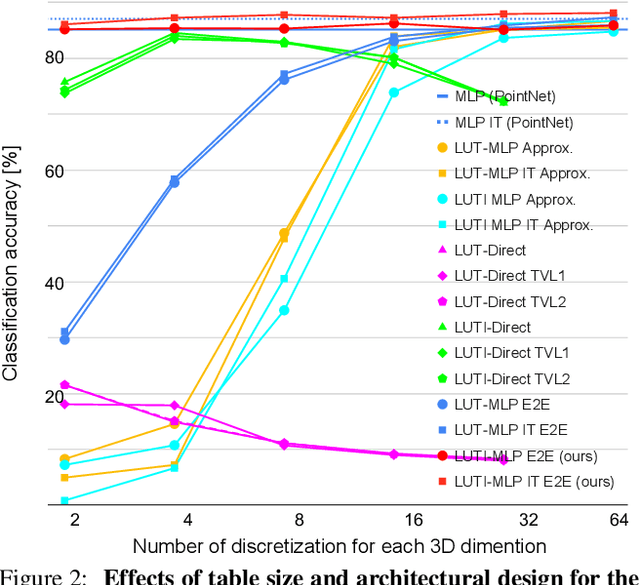
Aiming at a drastic speedup for point-data embeddings at test time, we propose a new framework that uses a pair of multi-layer perceptron (MLP) and look-up table (LUT) to transform point-coordinate inputs into high-dimensional features. When compared with PointNet's feature embedding part realized by MLP that requires millions of dot products, ours at test time requires no such layers of matrix-vector products but requires only looking up the nearest entities followed by interpolation, from the tabulated MLP defined over discrete inputs on a 3D lattice. We call this framework as "LUTI-MLP: LUT Interpolation MLP" that provides a way to train end-to-end tabulated MLP coupled to a LUT in a specific manner without the need for any approximation at test time. LUTI-MLP also provides significant speedup for Jacobian computation of the embedding function wrt global pose coordinate on Lie algebra $\mathfrak{se}(3)$ at test time, which could be used for point-set registration problems. After extensive architectural analysis using ModelNet40 dataset, we confirmed that our LUTI-MLP even with a small-sized table ($8\times 8\times 8$) yields performance comparable to that of MLP while achieving significant speedup: $80\times$ for embedding, $12\times$ for approximate Jacobian, and $860\times$ for canonical Jacobian.
EventNet: Asynchronous recursive event processing
Dec 07, 2018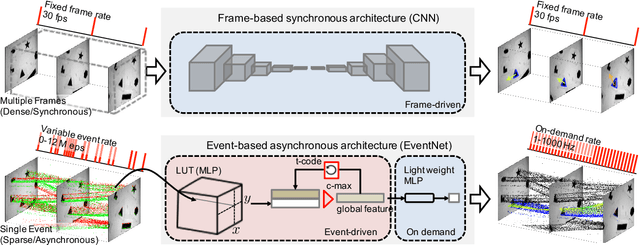
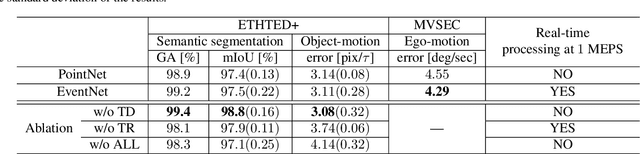
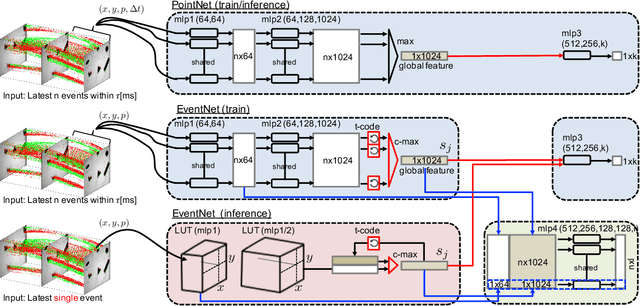
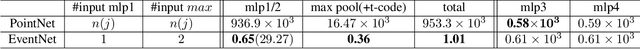
Event cameras are bio-inspired vision sensors which mimic retinas to asynchronously report per-pixel intensity change rather than outputting an actual intensity image at regular interval. This new paradigm of image sensor offers significant potential advantages: namely sparse and non-redundant data representation. Unfortunately, however, most of the existing artificial neural network architecture, such as CNN, requires dense synchronous input data, thereby cannot make use of the sparseness of the data. Here, we propose EventNet, to the best of our knowledge, the first trainable neural network architecture, which can directly process asynchronous sparse event signals recursively in an event-wise manner. EventNet models dependence of the output on tens of thousands of causal event recursively by the novel temporal coding scheme. As a result, at inference time, our network operates in the event-wise manner which is realized by very few sum-of-the-product operations---table look-up and temporal feature aggregation---which enabled processing of $1$ mega or more event per second on standard CPU. In experiments using real data, we demonstrate the real-time performance and robustness of our framework.