 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat-Where Transformer: A Slot-Centric Visual Backbone for Concurrent Representation and Localization
May 12, 2026Many image understanding tasks involve identifying what is present and where it appears. However, tasks that address where, such as object discovery, detection, and segmentation, are often considerably more complex than image classification, which primarily focuses on what. One possible reason is that classification-oriented backbones tend to emphasize semantic information about what, while implicitly entangling or suppressing information about where. In this work, we focus on an inductive bias termed what-where separation, which encourages models to represent object appearance and spatial location in a decomposed manner. To incorporate this bias throughout an attentive backbone in the style of Vision Transformer (ViT), we propose the What-Where Transformer (WWT). Our method introduces two key novel designs: (1) it treats tokens as representations of what and attention maps as representations of where, and processes them in concurrent feed-forward modules via a multi-stream, slot-based architecture; (2) it reuses both the final-layer tokens and attention maps for downstream tasks, and directly exposes them to gradients derived from task losses, thereby facilitating more effective and explicit learning of localization. We demonstrate that even under standard single-label classification-based supervision on ImageNet, WWT exhibits emergent multiple object discovery directly from raw attention maps, rather than via additional postprocessing such as token clustering. Furthermore, WWT achieves superior performance compared to ViT-based methods on zero-shot object discovery and weakly supervised semantic segmentation, and it is transferable to various localization setups with minimal modifications. Code will be published after acceptance.
Teacher-Guided Routing for Sparse Vision Mixture-of-Experts
Apr 23, 2026Recent progress in deep learning has been driven by increasingly large-scale models, but the resulting computational cost has become a critical bottleneck. Sparse Mixture of Experts (MoE) offers an effective solution by activating only a small subset of experts for each input, achieving high scalability without sacrificing inference speed. Although effective, sparse MoE training exhibits characteristic optimization difficulties. Because the router receives informative gradients only through the experts selected in the forward pass, it suffers from gradient blocking and obtains little information from unselected routes. This limited, highly localized feedback makes it difficult for the router to learn appropriate expert-selection scores and often leads to unstable routing dynamics, such as fluctuating expert assignments during training. To address this issue, we propose TGR-MoE: Teacher-Guided Routing for Sparse Vision Mixture-of-Experts, a simple yet effective method that stabilizes router learning using supervision derived from a pretrained dense teacher model. TGR-MoE constructs a teacher router from the teacher's intermediate representations and uses its routing outputs as pseudo-supervision for the student router, suppressing frequent routing fluctuations during training and enabling knowledge-guided expert selection from the early stages of training. Extensive experiments on ImageNet-1K and CIFAR-100 demonstrate that TGR consistently improves both accuracy and routing consistency, while maintaining stable training even under highly sparse configurations.
High-Fidelity 3D Tooth Reconstruction by Fusing Intraoral Scans and CBCT Data via a Deep Implicit Representation
Jan 21, 2026High-fidelity 3D tooth models are essential for digital dentistry, but must capture both the detailed crown and the complete root. Clinical imaging modalities are limited: Cone-Beam Computed Tomography (CBCT) captures the root but has a noisy, low-resolution crown, while Intraoral Scanners (IOS) provide a high-fidelity crown but no root information. A naive fusion of these sources results in unnatural seams and artifacts. We propose a novel, fully-automated pipeline that fuses CBCT and IOS data using a deep implicit representation. Our method first segments and robustly registers the tooth instances, then creates a hybrid proxy mesh combining the IOS crown and the CBCT root. The core of our approach is to use this noisy proxy to guide a class-specific DeepSDF network. This optimization process projects the input onto a learned manifold of ideal tooth shapes, generating a seamless, watertight, and anatomically coherent model. Qualitative and quantitative evaluations show our method uniquely preserves both the high-fidelity crown from IOS and the patient-specific root morphology from CBCT, overcoming the limitations of each modality and naive stitching.
Geometry Meets Light: Leveraging Geometric Priors for Universal Photometric Stereo under Limited Multi-Illumination Cues
Nov 18, 2025
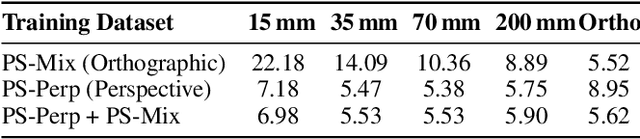
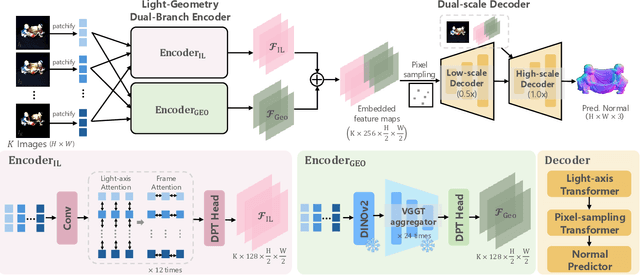
Universal Photometric Stereo is a promising approach for recovering surface normals without strict lighting assumptions. However, it struggles when multi-illumination cues are unreliable, such as under biased lighting or in shadows or self-occluded regions of complex in-the-wild scenes. We propose GeoUniPS, a universal photometric stereo network that integrates synthetic supervision with high-level geometric priors from large-scale 3D reconstruction models pretrained on massive in-the-wild data. Our key insight is that these 3D reconstruction models serve as visual-geometry foundation models, inherently encoding rich geometric knowledge of real scenes. To leverage this, we design a Light-Geometry Dual-Branch Encoder that extracts both multi-illumination cues and geometric priors from the frozen 3D reconstruction model. We also address the limitations of the conventional orthographic projection assumption by introducing the PS-Perp dataset with realistic perspective projection to enable learning of spatially varying view directions. Extensive experiments demonstrate that GeoUniPS delivers state-of-the-arts performance across multiple datasets, both quantitatively and qualitatively, especially in the complex in-the-wild scenes.
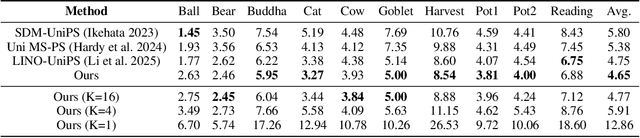
Light of Normals: Unified Feature Representation for Universal Photometric Stereo
Jun 24, 2025
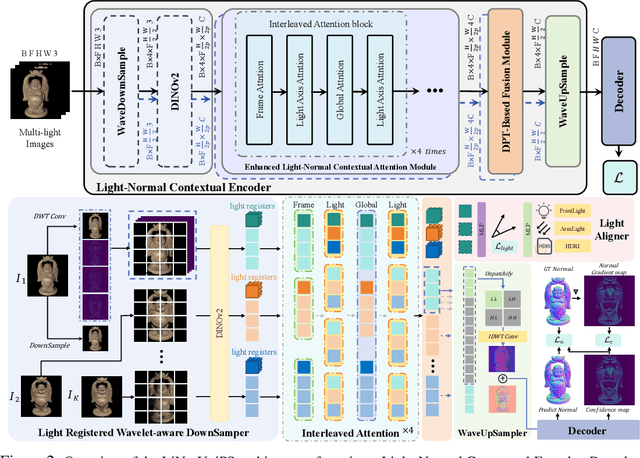
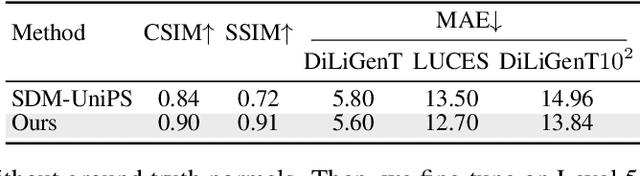

Universal photometric stereo (PS) aims to recover high-quality surface normals from objects under arbitrary lighting conditions without relying on specific illumination models. Despite recent advances such as SDM-UniPS and Uni MS-PS, two fundamental challenges persist: 1) the deep coupling between varying illumination and surface normal features, where ambiguity in observed intensity makes it difficult to determine whether brightness variations stem from lighting changes or surface orientation; and 2) the preservation of high-frequency geometric details in complex surfaces, where intricate geometries create self-shadowing, inter-reflections, and subtle normal variations that conventional feature processing operations struggle to capture accurately.
Rectified Lagrangian for Out-of-Distribution Detection in Modern Hopfield Networks
Feb 19, 2025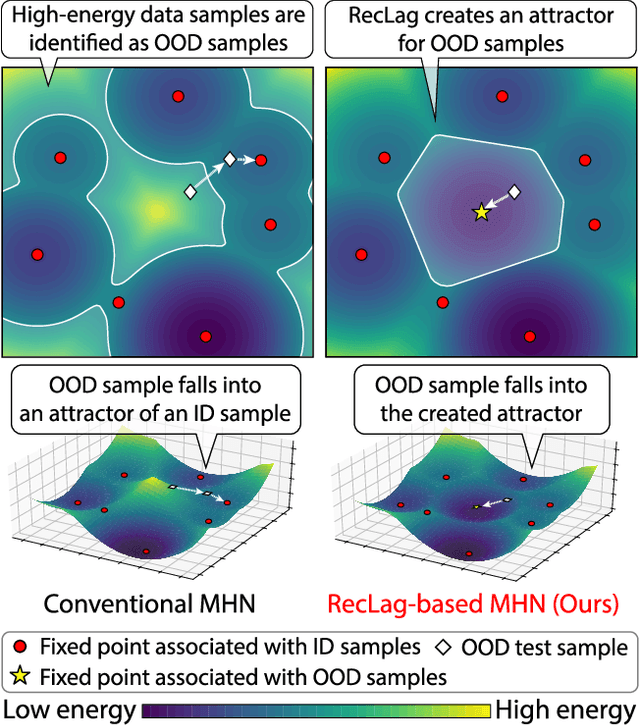
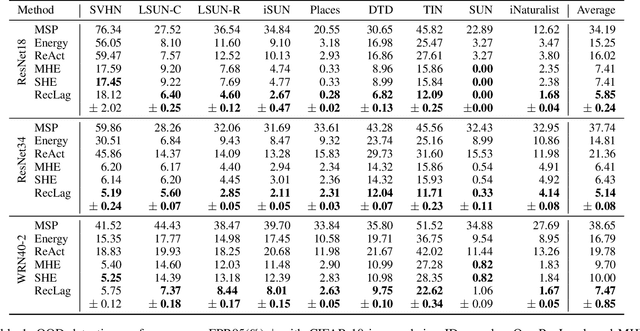
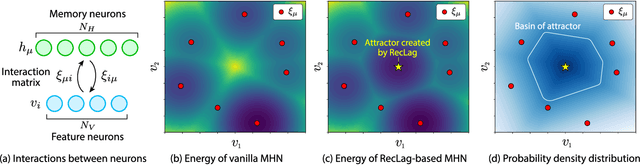
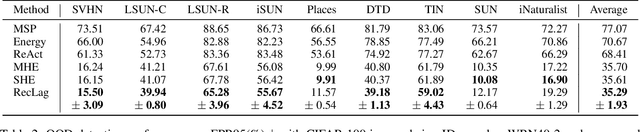
Modern Hopfield networks (MHNs) have recently gained significant attention in the field of artificial intelligence because they can store and retrieve a large set of patterns with an exponentially large memory capacity. A MHN is generally a dynamical system defined with Lagrangians of memory and feature neurons, where memories associated with in-distribution (ID) samples are represented by attractors in the feature space. One major problem in existing MHNs lies in managing out-of-distribution (OOD) samples because it was originally assumed that all samples are ID samples. To address this, we propose the rectified Lagrangian (RegLag), a new Lagrangian for memory neurons that explicitly incorporates an attractor for OOD samples in the dynamical system of MHNs. RecLag creates a trivial point attractor for any interaction matrix, enabling OOD detection by identifying samples that fall into this attractor as OOD. The interaction matrix is optimized so that the probability densities can be estimated to identify ID/OOD. We demonstrate the effectiveness of RecLag-based MHNs compared to energy-based OOD detection methods, including those using state-of-the-art Hopfield energies, across nine image datasets.
Physics-Free Spectrally Multiplexed Photometric Stereo under Unknown Spectral Composition
Oct 28, 2024

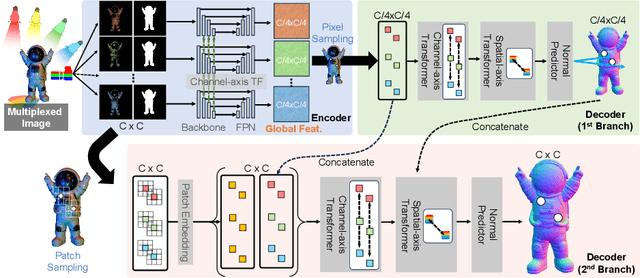

In this paper, we present a groundbreaking spectrally multiplexed photometric stereo approach for recovering surface normals of dynamic surfaces without the need for calibrated lighting or sensors, a notable advancement in the field traditionally hindered by stringent prerequisites and spectral ambiguity. By embracing spectral ambiguity as an advantage, our technique enables the generation of training data without specialized multispectral rendering frameworks. We introduce a unique, physics-free network architecture, SpectraM-PS, that effectively processes multiplexed images to determine surface normals across a wide range of conditions and material types, without relying on specific physically-based knowledge. Additionally, we establish the first benchmark dataset, SpectraM14, for spectrally multiplexed photometric stereo, facilitating comprehensive evaluations against existing calibrated methods. Our contributions significantly enhance the capabilities for dynamic surface recovery, particularly in uncalibrated setups, marking a pivotal step forward in the application of photometric stereo across various domains.
GUMBEL-NERF: Representing Unseen Objects as Part-Compositional Neural Radiance Fields
Oct 27, 2024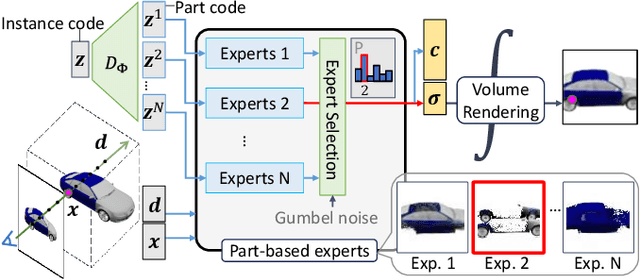
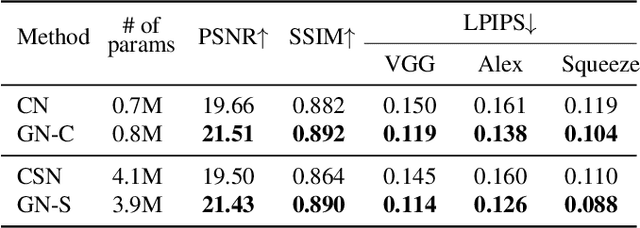
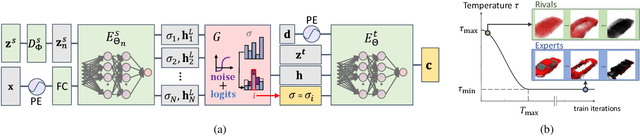
We propose Gumbel-NeRF, a mixture-of-expert (MoE) neural radiance fields (NeRF) model with a hindsight expert selection mechanism for synthesizing novel views of unseen objects. Previous studies have shown that the MoE structure provides high-quality representations of a given large-scale scene consisting of many objects. However, we observe that such a MoE NeRF model often produces low-quality representations in the vicinity of experts' boundaries when applied to the task of novel view synthesis of an unseen object from one/few-shot input. We find that this deterioration is primarily caused by the foresight expert selection mechanism, which may leave an unnatural discontinuity in the object shape near the experts' boundaries. Gumbel-NeRF adopts a hindsight expert selection mechanism, which guarantees continuity in the density field even near the experts' boundaries. Experiments using the SRN cars dataset demonstrate the superiority of Gumbel-NeRF over the baselines in terms of various image quality metrics.
MERLiN: Single-Shot Material Estimation and Relighting for Photometric Stereo
Sep 01, 2024



Photometric stereo typically demands intricate data acquisition setups involving multiple light sources to recover surface normals accurately. In this paper, we propose MERLiN, an attention-based hourglass network that integrates single image-based inverse rendering and relighting within a single unified framework. We evaluate the performance of photometric stereo methods using these relit images and demonstrate how they can circumvent the underlying challenge of complex data acquisition. Our physically-based model is trained on a large synthetic dataset containing complex shapes with spatially varying BRDF and is designed to handle indirect illumination effects to improve material reconstruction and relighting. Through extensive qualitative and quantitative evaluation, we demonstrate that the proposed framework generalizes well to real-world images, achieving high-quality shape, material estimation, and relighting. We assess these synthetically relit images over photometric stereo benchmark methods for their physical correctness and resulting normal estimation accuracy, paving the way towards single-shot photometric stereo through physically-based relighting. This work allows us to address the single image-based inverse rendering problem holistically, applying well to both synthetic and real data and taking a step towards mitigating the challenge of data acquisition in photometric stereo.
Entity-NeRF: Detecting and Removing Moving Entities in Urban Scenes
Mar 24, 2024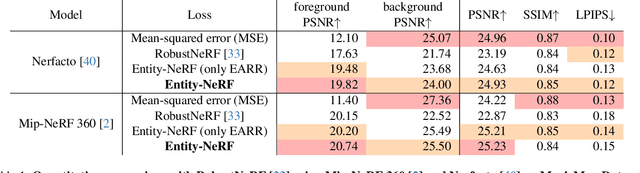



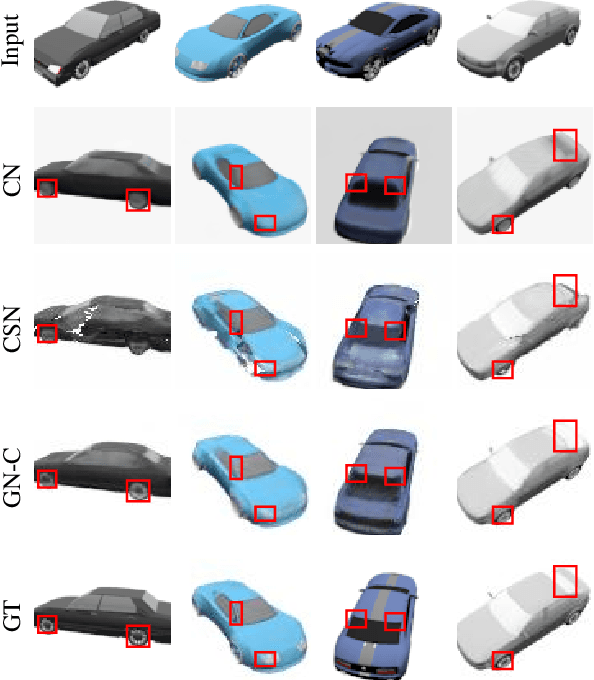
Recent advancements in the study of Neural Radiance Fields (NeRF) for dynamic scenes often involve explicit modeling of scene dynamics. However, this approach faces challenges in modeling scene dynamics in urban environments, where moving objects of various categories and scales are present. In such settings, it becomes crucial to effectively eliminate moving objects to accurately reconstruct static backgrounds. Our research introduces an innovative method, termed here as Entity-NeRF, which combines the strengths of knowledge-based and statistical strategies. This approach utilizes entity-wise statistics, leveraging entity segmentation and stationary entity classification through thing/stuff segmentation. To assess our methodology, we created an urban scene dataset masked with moving objects. Our comprehensive experiments demonstrate that Entity-NeRF notably outperforms existing techniques in removing moving objects and reconstructing static urban backgrounds, both quantitatively and qualitatively.