 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Object States from Actions via Large Language Models
May 02, 2024



Temporally localizing the presence of object states in videos is crucial in understanding human activities beyond actions and objects. This task has suffered from a lack of training data due to object states' inherent ambiguity and variety. To avoid exhaustive annotation, learning from transcribed narrations in instructional videos would be intriguing. However, object states are less described in narrations compared to actions, making them less effective. In this work, we propose to extract the object state information from action information included in narrations, using large language models (LLMs). Our observation is that LLMs include world knowledge on the relationship between actions and their resulting object states, and can infer the presence of object states from past action sequences. The proposed LLM-based framework offers flexibility to generate plausible pseudo-object state labels against arbitrary categories. We evaluate our method with our newly collected Multiple Object States Transition (MOST) dataset including dense temporal annotation of 60 object state categories. Our model trained by the generated pseudo-labels demonstrates significant improvement of over 29% in mAP against strong zero-shot vision-language models, showing the effectiveness of explicitly extracting object state information from actions through LLMs.
FineBio: A Fine-Grained Video Dataset of Biological Experiments with Hierarchical Annotation
Feb 01, 2024



In the development of science, accurate and reproducible documentation of the experimental process is crucial. Automatic recognition of the actions in experiments from videos would help experimenters by complementing the recording of experiments. Towards this goal, we propose FineBio, a new fine-grained video dataset of people performing biological experiments. The dataset consists of multi-view videos of 32 participants performing mock biological experiments with a total duration of 14.5 hours. One experiment forms a hierarchical structure, where a protocol consists of several steps, each further decomposed into a set of atomic operations. The uniqueness of biological experiments is that while they require strict adherence to steps described in each protocol, there is freedom in the order of atomic operations. We provide hierarchical annotation on protocols, steps, atomic operations, object locations, and their manipulation states, providing new challenges for structured activity understanding and hand-object interaction recognition. To find out challenges on activity understanding in biological experiments, we introduce baseline models and results on four different tasks, including (i) step segmentation, (ii) atomic operation detection (iii) object detection, and (iv) manipulated/affected object detection. Dataset and code are available from https://github.com/aistairc/FineBio.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Exo2EgoDVC: Dense Video Captioning of Egocentric Procedural Activities Using Web Instructional Videos
Nov 29, 2023



We propose a novel benchmark for cross-view knowledge transfer of dense video captioning, adapting models from web instructional videos with exocentric views to an egocentric view. While dense video captioning (predicting time segments and their captions) is primarily studied with exocentric videos (e.g., YouCook2), benchmarks with egocentric videos are restricted due to data scarcity. To overcome the limited video availability, transferring knowledge from abundant exocentric web videos is demanded as a practical approach. However, learning the correspondence between exocentric and egocentric views is difficult due to their dynamic view changes. The web videos contain mixed views focusing on either human body actions or close-up hand-object interactions, while the egocentric view is constantly shifting as the camera wearer moves. This necessitates the in-depth study of cross-view transfer under complex view changes. In this work, we first create a real-life egocentric dataset (EgoYC2) whose captions are shared with YouCook2, enabling transfer learning between these datasets assuming their ground-truth is accessible. To bridge the view gaps, we propose a view-invariant learning method using adversarial training in both the pre-training and fine-tuning stages. While the pre-training is designed to learn invariant features against the mixed views in the web videos, the view-invariant fine-tuning further mitigates the view gaps between both datasets. We validate our proposed method by studying how effectively it overcomes the view change problem and efficiently transfers the knowledge to the egocentric domain. Our benchmark pushes the study of the cross-view transfer into a new task domain of dense video captioning and will envision methodologies to describe egocentric videos in natural language.
Fine-grained Affordance Annotation for Egocentric Hand-Object Interaction Videos
Feb 10, 2023



Object affordance is an important concept in hand-object interaction, providing information on action possibilities based on human motor capacity and objects' physical property thus benefiting tasks such as action anticipation and robot imitation learning. However, the definition of affordance in existing datasets often: 1) mix up affordance with object functionality; 2) confuse affordance with goal-related action; and 3) ignore human motor capacity. This paper proposes an efficient annotation scheme to address these issues by combining goal-irrelevant motor actions and grasp types as affordance labels and introducing the concept of mechanical action to represent the action possibilities between two objects. We provide new annotations by applying this scheme to the EPIC-KITCHENS dataset and test our annotation with tasks such as affordance recognition, hand-object interaction hotspots prediction, and cross-domain evaluation of affordance. The results show that models trained with our annotation can distinguish affordance from other concepts, predict fine-grained interaction possibilities on objects, and generalize through different domains.
Precise Affordance Annotation for Egocentric Action Video Datasets
Jun 11, 2022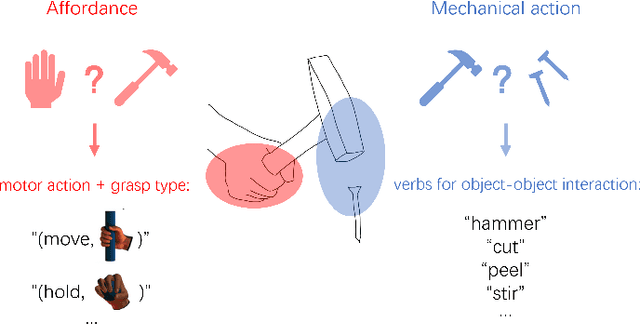


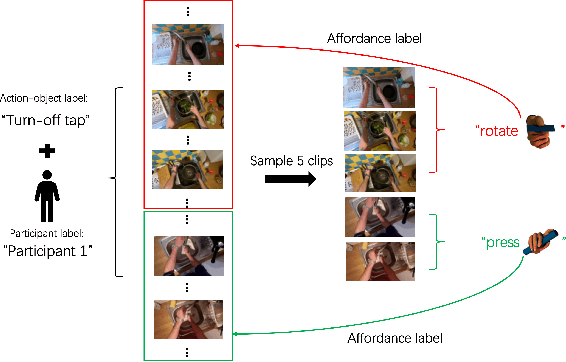
Object affordance is an important concept in human-object interaction, providing information on action possibilities based on human motor capacity and objects' physical property thus benefiting tasks such as action anticipation and robot imitation learning. However, existing datasets often: 1) mix up affordance with object functionality; 2) confuse affordance with goal-related action; and 3) ignore human motor capacity. This paper proposes an efficient annotation scheme to address these issues by combining goal-irrelevant motor actions and grasp types as affordance labels and introducing the concept of mechanical action to represent the action possibilities between two objects. We provide new annotations by applying this scheme to the EPIC-KITCHENS dataset and test our annotation with tasks such as affordance recognition. We qualitatively verify that models trained with our annotation can distinguish affordance and mechanical actions.
Object Instance Identification in Dynamic Environments
Jun 10, 2022
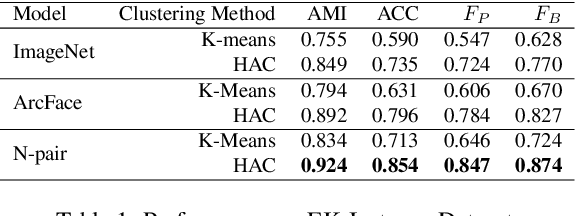
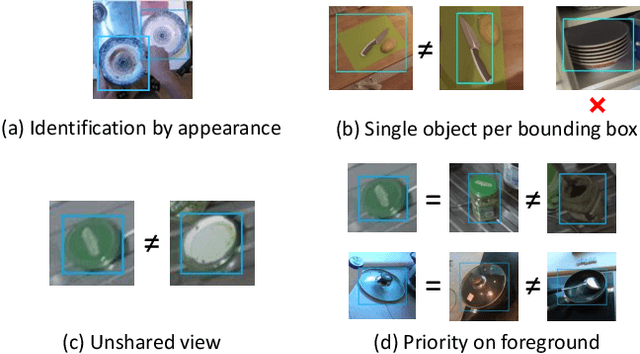

We study the problem of identifying object instances in a dynamic environment where people interact with the objects. In such an environment, objects' appearance changes dynamically by interaction with other entities, occlusion by hands, background change, etc. This leads to a larger intra-instance variation of appearance than in static environments. To discover the challenges in this setting, we newly built a benchmark of more than 1,500 instances built on the EPIC-KITCHENS dataset which includes natural activities and conducted an extensive analysis of it. Experimental results suggest that (i) robustness against instance-specific appearance change (ii) integration of low-level (e.g., color, texture) and high-level (e.g., object category) features (iii) foreground feature selection on overlapping objects are required for further improvement.
Hand-Object Contact Prediction via Motion-Based Pseudo-Labeling and Guided Progressive Label Correction
Oct 19, 2021
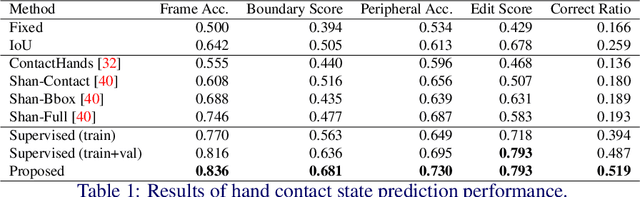

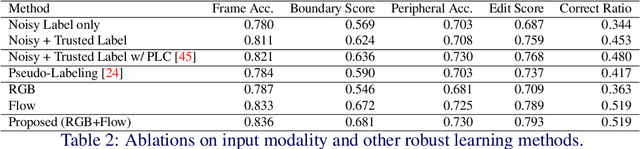
Every hand-object interaction begins with contact. Despite predicting the contact state between hands and objects is useful in understanding hand-object interactions, prior methods on hand-object analysis have assumed that the interacting hands and objects are known, and were not studied in detail. In this study, we introduce a video-based method for predicting contact between a hand and an object. Specifically, given a video and a pair of hand and object tracks, we predict a binary contact state (contact or no-contact) for each frame. However, annotating a large number of hand-object tracks and contact labels is costly. To overcome the difficulty, we propose a semi-supervised framework consisting of (i) automatic collection of training data with motion-based pseudo-labels and (ii) guided progressive label correction (gPLC), which corrects noisy pseudo-labels with a small amount of trusted data. We validated our framework's effectiveness on a newly built benchmark dataset for hand-object contact prediction and showed superior performance against existing baseline methods. Code and data are available at https://github.com/takumayagi/hand_object_contact_prediction.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021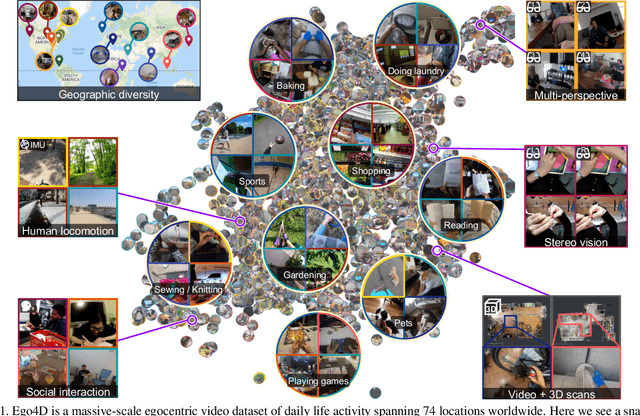
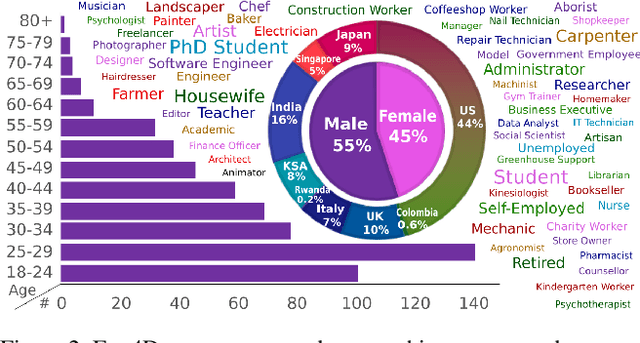

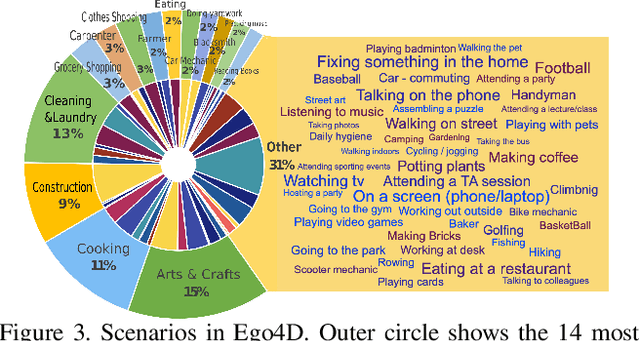
We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Foreground-Aware Stylization and Consensus Pseudo-Labeling for Domain Adaptation of First-Person Hand Segmentation
Jul 11, 2021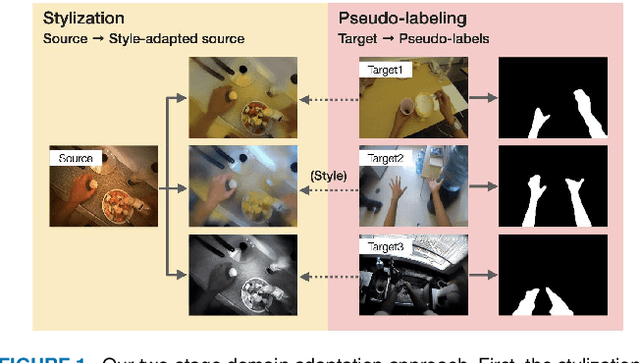
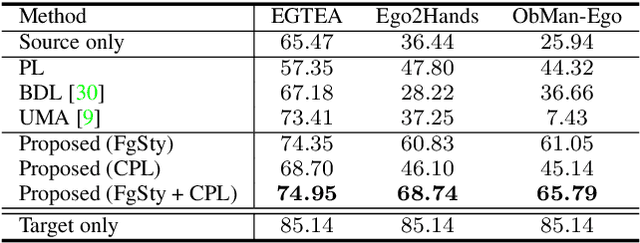


Hand segmentation is a crucial task in first-person vision. Since first-person images exhibit strong bias in appearance among different environments, adapting a pre-trained segmentation model to a new domain is required in hand segmentation. Here, we focus on appearance gaps for hand regions and backgrounds separately. We propose (i) foreground-aware image stylization and (ii) consensus pseudo-labeling for domain adaptation of hand segmentation. We stylize source images independently for the foreground and background using target images as style. To resolve the domain shift that the stylization has not addressed, we apply careful pseudo-labeling by taking a consensus between the models trained on the source and stylized source images. We validated our method on domain adaptation of hand segmentation from real and simulation images. Our method achieved state-of-the-art performance in both settings. We also demonstrated promising results in challenging multi-target domain adaptation and domain generalization settings. Code is available at https://github.com/ut-vision/FgSty-CPL.