 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential training of GANs against GAN-classifiers reveals correlated "knowledge gaps" present among independently trained GAN instances
Mar 27, 2023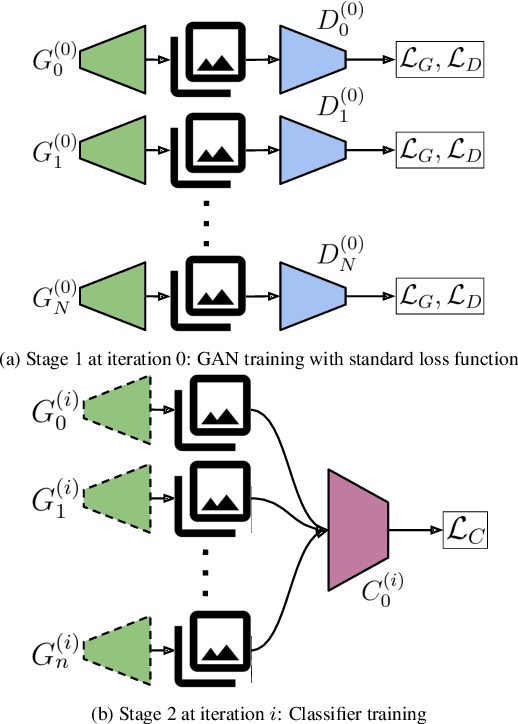

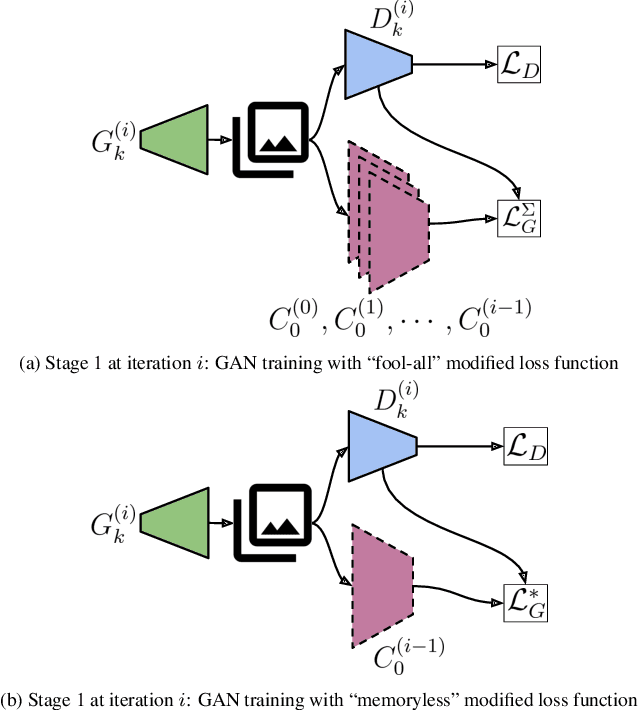
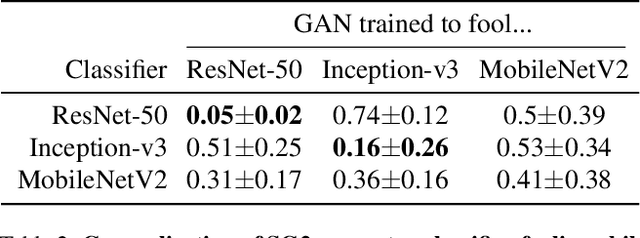
Modern Generative Adversarial Networks (GANs) generate realistic images remarkably well. Previous work has demonstrated the feasibility of "GAN-classifiers" that are distinct from the co-trained discriminator, and operate on images generated from a frozen GAN. That such classifiers work at all affirms the existence of "knowledge gaps" (out-of-distribution artifacts across samples) present in GAN training. We iteratively train GAN-classifiers and train GANs that "fool" the classifiers (in an attempt to fill the knowledge gaps), and examine the effect on GAN training dynamics, output quality, and GAN-classifier generalization. We investigate two settings, a small DCGAN architecture trained on low dimensional images (MNIST), and StyleGAN2, a SOTA GAN architecture trained on high dimensional images (FFHQ). We find that the DCGAN is unable to effectively fool a held-out GAN-classifier without compromising the output quality. However, StyleGAN2 can fool held-out classifiers with no change in output quality, and this effect persists over multiple rounds of GAN/classifier training which appears to reveal an ordering over optima in the generator parameter space. Finally, we study different classifier architectures and show that the architecture of the GAN-classifier has a strong influence on the set of its learned artifacts.
TruFor: Leveraging all-round clues for trustworthy image forgery detection and localization
Dec 21, 2022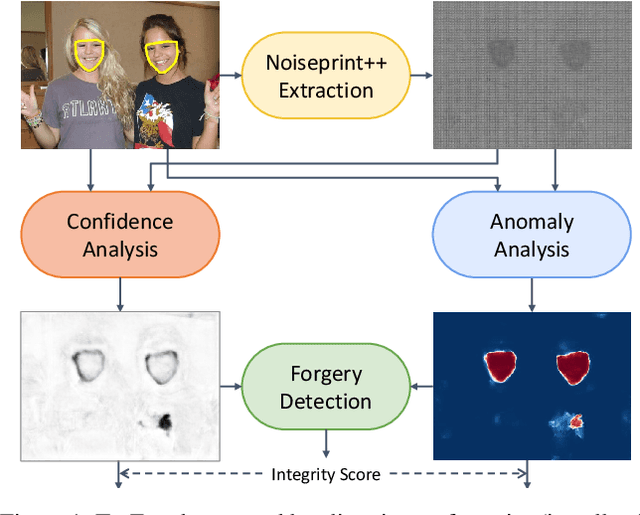
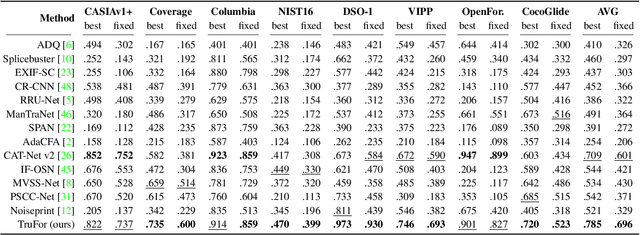

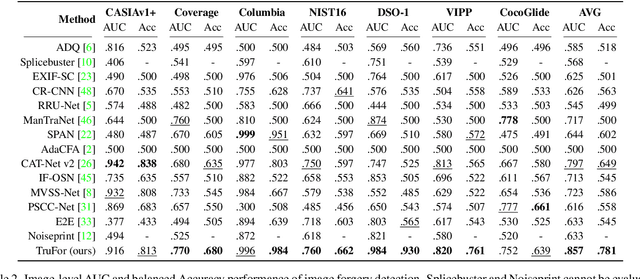
In this paper we present TruFor, a forensic framework that can be applied to a large variety of image manipulation methods, from classic cheapfakes to more recent manipulations based on deep learning. We rely on the extraction of both high-level and low-level traces through a transformer-based fusion architecture that combines the RGB image and a learned noise-sensitive fingerprint. The latter learns to embed the artifacts related to the camera internal and external processing by training only on real data in a self-supervised manner. Forgeries are detected as deviations from the expected regular pattern that characterizes each pristine image. Looking for anomalies makes the approach able to robustly detect a variety of local manipulations, ensuring generalization. In addition to a pixel-level localization map and a whole-image integrity score, our approach outputs a reliability map that highlights areas where localization predictions may be error-prone. This is particularly important in forensic applications in order to reduce false alarms and allow for a large scale analysis. Extensive experiments on several datasets show that our method is able to reliably detect and localize both cheapfakes and deepfakes manipulations outperforming state-of-the-art works. Code will be publicly available at https://grip-unina.github.io/TruFor/