 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential training of GANs against GAN-classifiers reveals correlated "knowledge gaps" present among independently trained GAN instances
Mar 27, 2023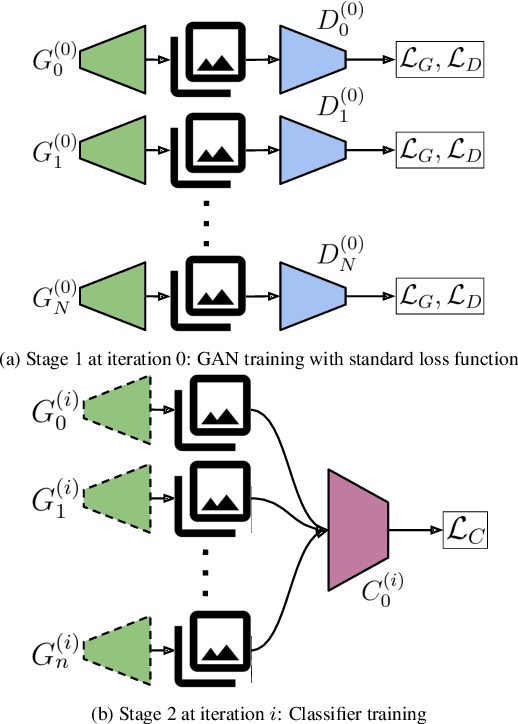

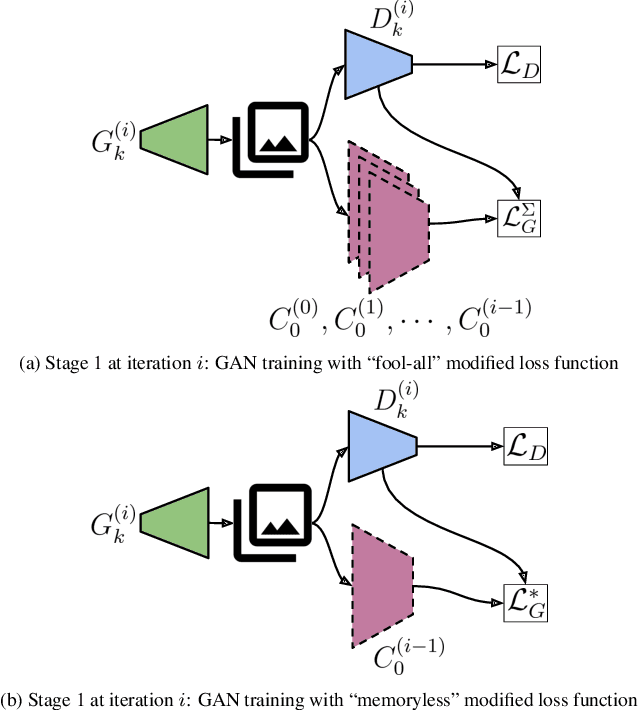
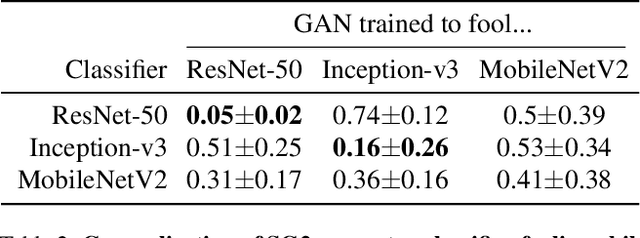
Modern Generative Adversarial Networks (GANs) generate realistic images remarkably well. Previous work has demonstrated the feasibility of "GAN-classifiers" that are distinct from the co-trained discriminator, and operate on images generated from a frozen GAN. That such classifiers work at all affirms the existence of "knowledge gaps" (out-of-distribution artifacts across samples) present in GAN training. We iteratively train GAN-classifiers and train GANs that "fool" the classifiers (in an attempt to fill the knowledge gaps), and examine the effect on GAN training dynamics, output quality, and GAN-classifier generalization. We investigate two settings, a small DCGAN architecture trained on low dimensional images (MNIST), and StyleGAN2, a SOTA GAN architecture trained on high dimensional images (FFHQ). We find that the DCGAN is unable to effectively fool a held-out GAN-classifier without compromising the output quality. However, StyleGAN2 can fool held-out classifiers with no change in output quality, and this effect persists over multiple rounds of GAN/classifier training which appears to reveal an ordering over optima in the generator parameter space. Finally, we study different classifier architectures and show that the architecture of the GAN-classifier has a strong influence on the set of its learned artifacts.
High Fidelity Video Prediction with Large Stochastic Recurrent Neural Networks
Nov 05, 2019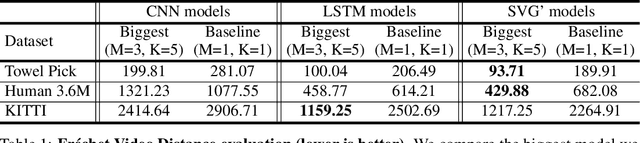
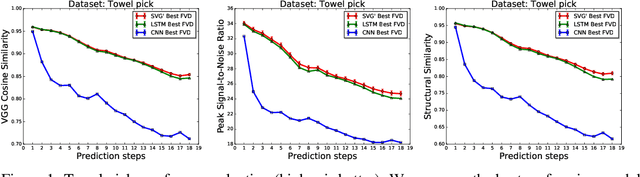
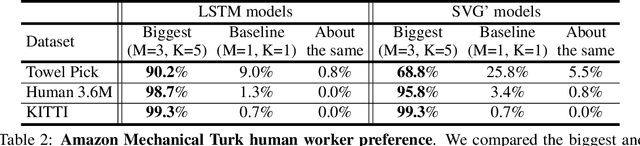

Predicting future video frames is extremely challenging, as there are many factors of variation that make up the dynamics of how frames change through time. Previously proposed solutions require complex inductive biases inside network architectures with highly specialized computation, including segmentation masks, optical flow, and foreground and background separation. In this work, we question if such handcrafted architectures are necessary and instead propose a different approach: finding minimal inductive bias for video prediction while maximizing network capacity. We investigate this question by performing the first large-scale empirical study and demonstrate state-of-the-art performance by learning large models on three different datasets: one for modeling object interactions, one for modeling human motion, and one for modeling car driving.
Learning 6-DOF Grasping Interaction via Deep Geometry-aware 3D Representations
Jun 15, 2018
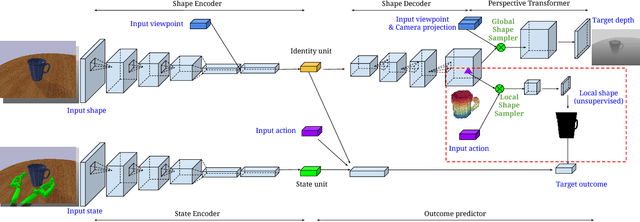
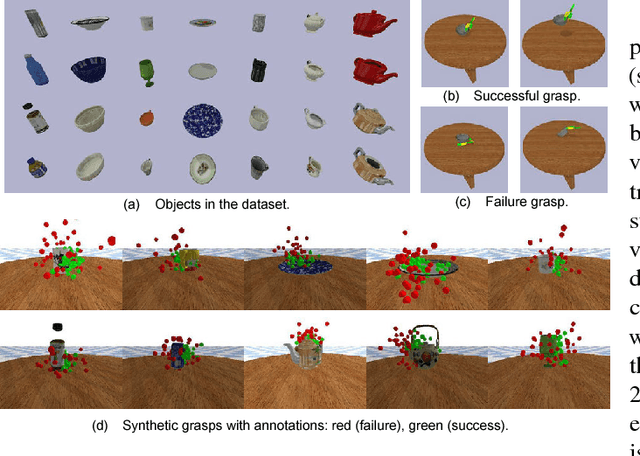
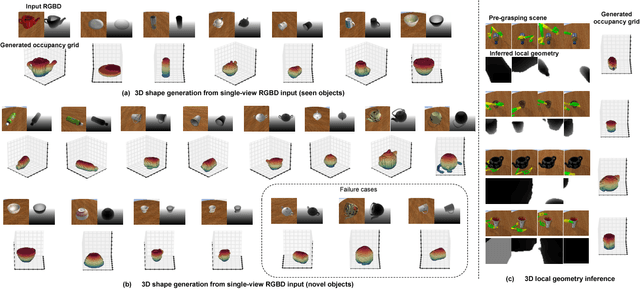
This paper focuses on the problem of learning 6-DOF grasping with a parallel jaw gripper in simulation. We propose the notion of a geometry-aware representation in grasping based on the assumption that knowledge of 3D geometry is at the heart of interaction. Our key idea is constraining and regularizing grasping interaction learning through 3D geometry prediction. Specifically, we formulate the learning of deep geometry-aware grasping model in two steps: First, we learn to build mental geometry-aware representation by reconstructing the scene (i.e., 3D occupancy grid) from RGBD input via generative 3D shape modeling. Second, we learn to predict grasping outcome with its internal geometry-aware representation. The learned outcome prediction model is used to sequentially propose grasping solutions via analysis-by-synthesis optimization. Our contributions are fourfold: (1) To best of our knowledge, we are presenting for the first time a method to learn a 6-DOF grasping net from RGBD input; (2) We build a grasping dataset from demonstrations in virtual reality with rich sensory and interaction annotations. This dataset includes 101 everyday objects spread across 7 categories, additionally, we propose a data augmentation strategy for effective learning; (3) We demonstrate that the learned geometry-aware representation leads to about 10 percent relative performance improvement over the baseline CNN on grasping objects from our dataset. (4) We further demonstrate that the model generalizes to novel viewpoints and object instances.
A Two-Phase Approach Towards Identifying Argument Structure in Natural Language
Dec 16, 2016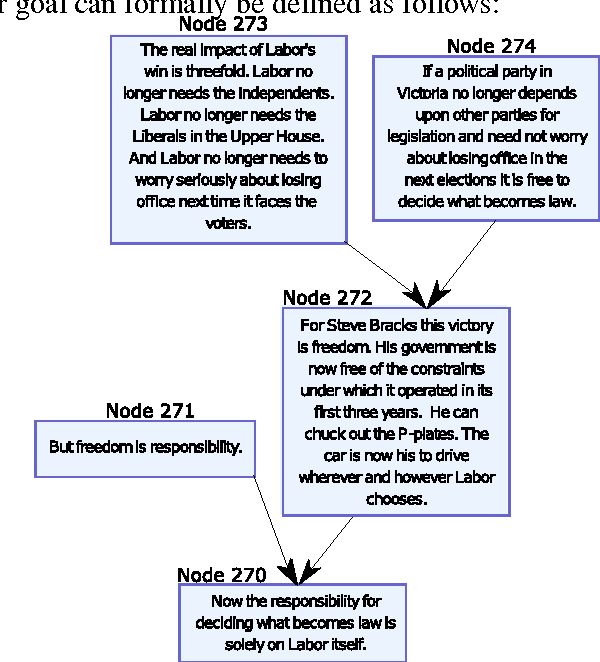
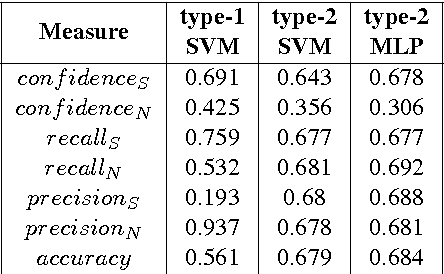
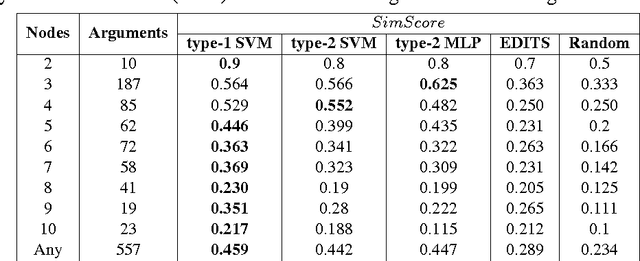
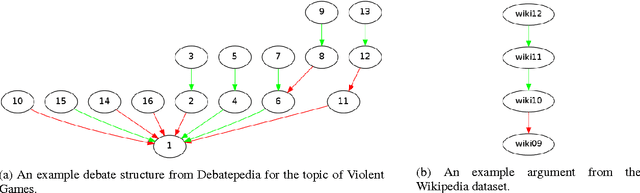
We propose a new approach for extracting argument structure from natural language texts that contain an underlying argument. Our approach comprises of two phases: Score Assignment and Structure Prediction. The Score Assignment phase trains models to classify relations between argument units (Support, Attack or Neutral). To that end, different training strategies have been explored. We identify different linguistic and lexical features for training the classifiers. Through ablation study, we observe that our novel use of word-embedding features is most effective for this task. The Structure Prediction phase makes use of the scores from the Score Assignment phase to arrive at the optimal structure. We perform experiments on three argumentation datasets, namely, AraucariaDB, Debatepedia and Wikipedia. We also propose two baselines and observe that the proposed approach outperforms baseline systems for the final task of Structure Prediction.