 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Visual Instruction Tuning
Jun 17, 2024



We propose to use machine-generated instruction-following data to improve the zero-shot capabilities of a large multimodal model with additional support for generative and image editing tasks. We achieve this by curating a new multimodal instruction-following set using GPT-4V and existing datasets for image generation and editing. Using this instruction set and the existing LLaVA-Finetune instruction set for visual understanding tasks, we produce GenLLaVA, a Generative Large Language, and Visual Assistant. GenLLaVA is built through a strategy that combines three types of large pre-trained models through instruction finetuning: LLaMA for language modeling, SigLIP for image-text matching, and StableDiffusion for text-to-image generation. Our model demonstrates visual understanding capabilities on par with LLaVA and additionally demonstrates competitive results with native multimodal models such as Unified-IO 2, paving the way for building advanced general-purpose visual assistants by effectively re-using existing multimodal models. We open-source our dataset, codebase, and model checkpoints to foster further research and application in this domain.
Text Prompting for Multi-Concept Video Customization by Autoregressive Generation
May 22, 2024We present a method for multi-concept customization of pretrained text-to-video (T2V) models. Intuitively, the multi-concept customized video can be derived from the (non-linear) intersection of the video manifolds of the individual concepts, which is not straightforward to find. We hypothesize that sequential and controlled walking towards the intersection of the video manifolds, directed by text prompting, leads to the solution. To do so, we generate the various concepts and their corresponding interactions, sequentially, in an autoregressive manner. Our method can generate videos of multiple custom concepts (subjects, action and background) such as a teddy bear running towards a brown teapot, a dog playing violin and a teddy bear swimming in the ocean. We quantitatively evaluate our method using videoCLIP and DINO scores, in addition to human evaluation. Videos for results presented in this paper can be found at https://github.com/divyakraman/MultiConceptVideo2024.
StoryBench: A Multifaceted Benchmark for Continuous Story Visualization
Aug 22, 2023



Generating video stories from text prompts is a complex task. In addition to having high visual quality, videos need to realistically adhere to a sequence of text prompts whilst being consistent throughout the frames. Creating a benchmark for video generation requires data annotated over time, which contrasts with the single caption used often in video datasets. To fill this gap, we collect comprehensive human annotations on three existing datasets, and introduce StoryBench: a new, challenging multi-task benchmark to reliably evaluate forthcoming text-to-video models. Our benchmark includes three video generation tasks of increasing difficulty: action execution, where the next action must be generated starting from a conditioning video; story continuation, where a sequence of actions must be executed starting from a conditioning video; and story generation, where a video must be generated from only text prompts. We evaluate small yet strong text-to-video baselines, and show the benefits of training on story-like data algorithmically generated from existing video captions. Finally, we establish guidelines for human evaluation of video stories, and reaffirm the need of better automatic metrics for video generation. StoryBench aims at encouraging future research efforts in this exciting new area.
Visual Representation Learning from Unlabeled Video using Contrastive Masked Autoencoders
Mar 21, 2023



Masked Autoencoders (MAEs) learn self-supervised representations by randomly masking input image patches and a reconstruction loss. Alternatively, contrastive learning self-supervised methods encourage two versions of the same input to have a similar representation, while pulling apart the representations for different inputs. We propose ViC-MAE, a general method that combines both MAE and contrastive learning by pooling the local feature representations learned under the MAE reconstruction objective and leveraging this global representation under a contrastive objective across video frames. We show that visual representations learned under ViC-MAE generalize well to both video classification and image classification tasks. Using a backbone ViT-B/16 network pre-trained on the Moments in Time (MiT) dataset, we obtain state-of-the-art transfer learning from video to images on Imagenet-1k by improving 1.58% in absolute top-1 accuracy from a recent previous work. Moreover, our method maintains a competitive transfer-learning performance of 81.50% top-1 accuracy on the Kinetics-400 video classification benchmark. In addition, we show that despite its simplicity, ViC-MAE yields improved results compared to combining MAE pre-training with previously proposed contrastive objectives such as VicReg and SiamSiam.
Phenaki: Variable Length Video Generation From Open Domain Textual Description
Oct 05, 2022
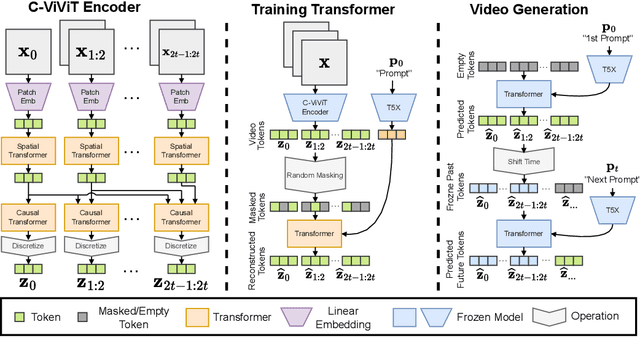


We present Phenaki, a model capable of realistic video synthesis, given a sequence of textual prompts. Generating videos from text is particularly challenging due to the computational cost, limited quantities of high quality text-video data and variable length of videos. To address these issues, we introduce a new model for learning video representation which compresses the video to a small representation of discrete tokens. This tokenizer uses causal attention in time, which allows it to work with variable-length videos. To generate video tokens from text we are using a bidirectional masked transformer conditioned on pre-computed text tokens. The generated video tokens are subsequently de-tokenized to create the actual video. To address data issues, we demonstrate how joint training on a large corpus of image-text pairs as well as a smaller number of video-text examples can result in generalization beyond what is available in the video datasets. Compared to the previous video generation methods, Phenaki can generate arbitrary long videos conditioned on a sequence of prompts (i.e. time variable text or a story) in open domain. To the best of our knowledge, this is the first time a paper studies generating videos from time variable prompts. In addition, compared to the per-frame baselines, the proposed video encoder-decoder computes fewer tokens per video but results in better spatio-temporal consistency.
RiCS: A 2D Self-Occlusion Map for Harmonizing Volumetric Objects
May 14, 2022
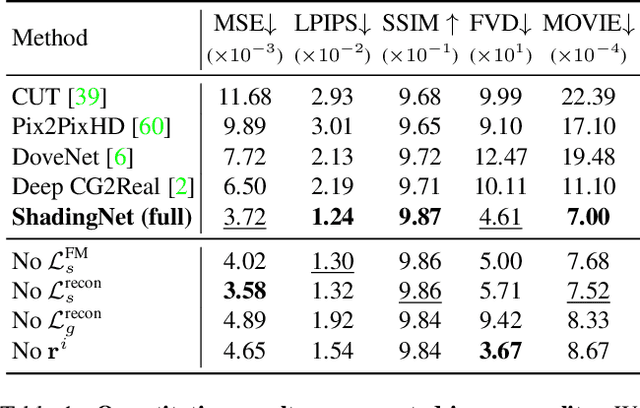
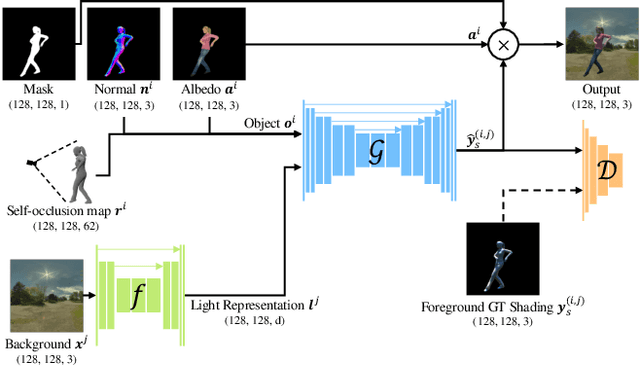
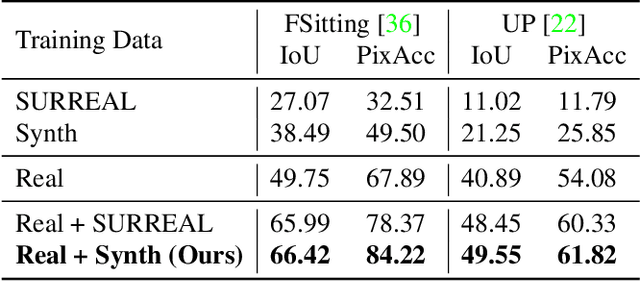
There have been remarkable successes in computer vision with deep learning. While such breakthroughs show robust performance, there have still been many challenges in learning in-depth knowledge, like occlusion or predicting physical interactions. Although some recent works show the potential of 3D data in serving such context, it is unclear how we efficiently provide 3D input to the 2D models due to the misalignment in dimensionality between 2D and 3D. To leverage the successes of 2D models in predicting self-occlusions, we design Ray-marching in Camera Space (RiCS), a new method to represent the self-occlusions of foreground objects in 3D into a 2D self-occlusion map. We test the effectiveness of our representation on the human image harmonization task by predicting shading that is coherent with a given background image. Our experiments demonstrate that our representation map not only allows us to enhance the image quality but also to model temporally coherent complex shadow effects compared with the simulation-to-real and harmonization methods, both quantitatively and qualitatively. We further show that we can significantly improve the performance of human parts segmentation networks trained on existing synthetic datasets by enhancing the harmonization quality with our method.
Contact-Aware Retargeting of Skinned Motion
Sep 15, 2021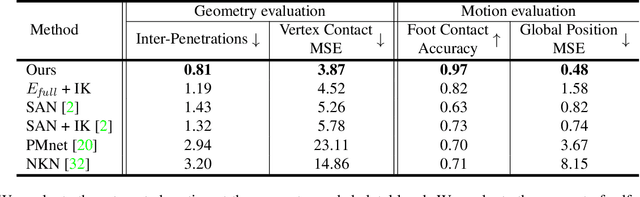
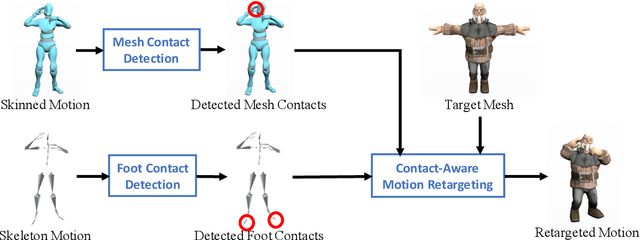

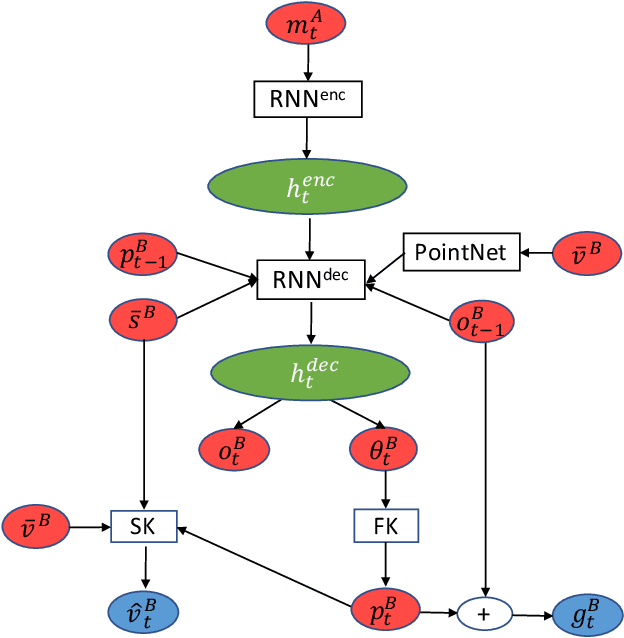
This paper introduces a motion retargeting method that preserves self-contacts and prevents interpenetration. Self-contacts, such as when hands touch each other or the torso or the head, are important attributes of human body language and dynamics, yet existing methods do not model or preserve these contacts. Likewise, interpenetration, such as a hand passing into the torso, are a typical artifact of motion estimation methods. The input to our method is a human motion sequence and a target skeleton and character geometry. The method identifies self-contacts and ground contacts in the input motion, and optimizes the motion to apply to the output skeleton, while preserving these contacts and reducing interpenetration. We introduce a novel geometry-conditioned recurrent network with an encoder-space optimization strategy that achieves efficient retargeting while satisfying contact constraints. In experiments, our results quantitatively outperform previous methods and we conduct a user study where our retargeted motions are rated as higher-quality than those produced by recent works. We also show our method generalizes to motion estimated from human videos where we improve over previous works that produce noticeable interpenetration.
Stochastic Scene-Aware Motion Prediction
Aug 18, 2021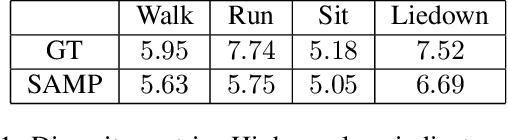

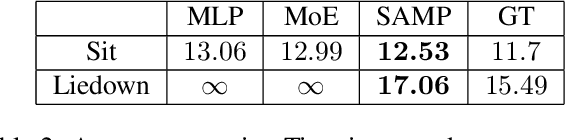

A long-standing goal in computer vision is to capture, model, and realistically synthesize human behavior. Specifically, by learning from data, our goal is to enable virtual humans to navigate within cluttered indoor scenes and naturally interact with objects. Such embodied behavior has applications in virtual reality, computer games, and robotics, while synthesized behavior can be used as a source of training data. This is challenging because real human motion is diverse and adapts to the scene. For example, a person can sit or lie on a sofa in many places and with varying styles. It is necessary to model this diversity when synthesizing virtual humans that realistically perform human-scene interactions. We present a novel data-driven, stochastic motion synthesis method that models different styles of performing a given action with a target object. Our method, called SAMP, for Scene-Aware Motion Prediction, generalizes to target objects of various geometries while enabling the character to navigate in cluttered scenes. To train our method, we collected MoCap data covering various sitting, lying down, walking, and running styles. We demonstrate our method on complex indoor scenes and achieve superior performance compared to existing solutions. Our code and data are available for research at https://samp.is.tue.mpg.de.
Single-image Full-body Human Relighting
Jul 15, 2021


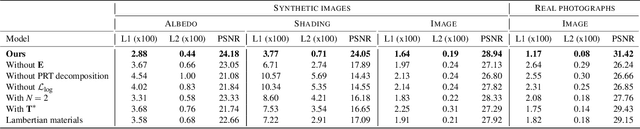
We present a single-image data-driven method to automatically relight images with full-body humans in them. Our framework is based on a realistic scene decomposition leveraging precomputed radiance transfer (PRT) and spherical harmonics (SH) lighting. In contrast to previous work, we lift the assumptions on Lambertian materials and explicitly model diffuse and specular reflectance in our data. Moreover, we introduce an additional light-dependent residual term that accounts for errors in the PRT-based image reconstruction. We propose a new deep learning architecture, tailored to the decomposition performed in PRT, that is trained using a combination of L1, logarithmic, and rendering losses. Our model outperforms the state of the art for full-body human relighting both with synthetic images and photographs.
* 11 pages, 12 figures
Task-Generic Hierarchical Human Motion Prior using VAEs
Jun 07, 2021
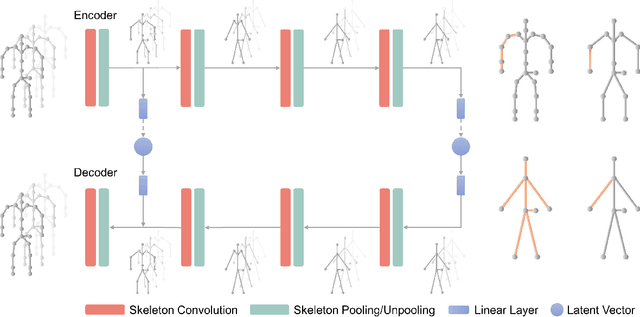

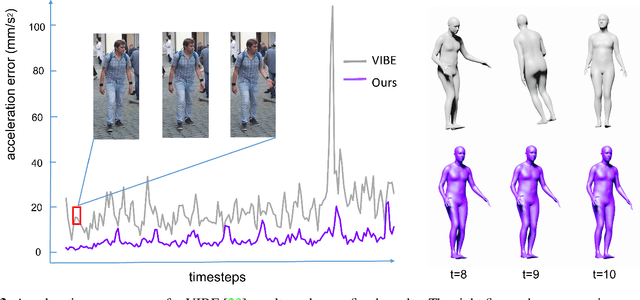
A deep generative model that describes human motions can benefit a wide range of fundamental computer vision and graphics tasks, such as providing robustness to video-based human pose estimation, predicting complete body movements for motion capture systems during occlusions, and assisting key frame animation with plausible movements. In this paper, we present a method for learning complex human motions independent of specific tasks using a combined global and local latent space to facilitate coarse and fine-grained modeling. Specifically, we propose a hierarchical motion variational autoencoder (HM-VAE) that consists of a 2-level hierarchical latent space. While the global latent space captures the overall global body motion, the local latent space enables to capture the refined poses of the different body parts. We demonstrate the effectiveness of our hierarchical motion variational autoencoder in a variety of tasks including video-based human pose estimation, motion completion from partial observations, and motion synthesis from sparse key-frames. Even though, our model has not been trained for any of these tasks specifically, it provides superior performance than task-specific alternatives. Our general-purpose human motion prior model can fix corrupted human body animations and generate complete movements from incomplete observations.