 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Video-to-Dataset Generation for Cross-Platform Mobile Agents
May 19, 2025Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have sparked significant interest in developing GUI visual agents. We introduce MONDAY (Mobile OS Navigation Task Dataset for Agents from YouTube), a large-scale dataset of 313K annotated frames from 20K instructional videos capturing diverse real-world mobile OS navigation across multiple platforms. Models that include MONDAY in their pre-training phases demonstrate robust cross-platform generalization capabilities, consistently outperforming models trained on existing single OS datasets while achieving an average performance gain of 18.11%p on an unseen mobile OS platform. To enable continuous dataset expansion as mobile platforms evolve, we present an automated framework that leverages publicly available video content to create comprehensive task datasets without manual annotation. Our framework comprises robust OCR-based scene detection (95.04% F1score), near-perfect UI element detection (99.87% hit ratio), and novel multi-step action identification to extract reliable action sequences across diverse interface configurations. We contribute both the MONDAY dataset and our automated collection framework to facilitate future research in mobile OS navigation.
YTCommentQA: Video Question Answerability in Instructional Videos
Jan 30, 2024



Instructional videos provide detailed how-to guides for various tasks, with viewers often posing questions regarding the content. Addressing these questions is vital for comprehending the content, yet receiving immediate answers is difficult. While numerous computational models have been developed for Video Question Answering (Video QA) tasks, they are primarily trained on questions generated based on video content, aiming to produce answers from within the content. However, in real-world situations, users may pose questions that go beyond the video's informational boundaries, highlighting the necessity to determine if a video can provide the answer. Discerning whether a question can be answered by video content is challenging due to the multi-modal nature of videos, where visual and verbal information are intertwined. To bridge this gap, we present the YTCommentQA dataset, which contains naturally-generated questions from YouTube, categorized by their answerability and required modality to answer -- visual, script, or both. Experiments with answerability classification tasks demonstrate the complexity of YTCommentQA and emphasize the need to comprehend the combined role of visual and script information in video reasoning. The dataset is available at https://github.com/lgresearch/YTCommentQA.
Multimodal Subtask Graph Generation from Instructional Videos
Feb 17, 2023



Real-world tasks consist of multiple inter-dependent subtasks (e.g., a dirty pan needs to be washed before it can be used for cooking). In this work, we aim to model the causal dependencies between such subtasks from instructional videos describing the task. This is a challenging problem since complete information about the world is often inaccessible from videos, which demands robust learning mechanisms to understand the causal structure of events. We present Multimodal Subtask Graph Generation (MSG2), an approach that constructs a Subtask Graph defining the dependency between a task's subtasks relevant to a task from noisy web videos. Graphs generated by our multimodal approach are closer to human-annotated graphs compared to prior approaches. MSG2 further performs the downstream task of next subtask prediction 85% and 30% more accurately than recent video transformer models in the ProceL and CrossTask datasets, respectively.
Unsupervised Task Graph Generation from Instructional Video Transcripts
Feb 17, 2023This work explores the problem of generating task graphs of real-world activities. Different from prior formulations, we consider a setting where text transcripts of instructional videos performing a real-world activity (e.g., making coffee) are provided and the goal is to identify the key steps relevant to the task as well as the dependency relationship between these key steps. We propose a novel task graph generation approach that combines the reasoning capabilities of instruction-tuned language models along with clustering and ranking components to generate accurate task graphs in a completely unsupervised manner. We show that the proposed approach generates more accurate task graphs compared to a supervised learning approach on tasks from the ProceL and CrossTask datasets.
RiCS: A 2D Self-Occlusion Map for Harmonizing Volumetric Objects
May 14, 2022
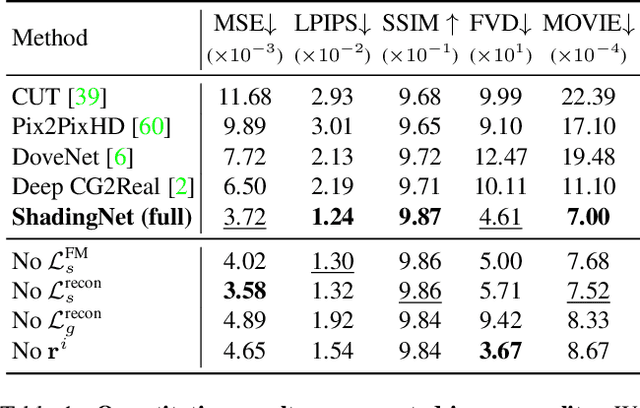
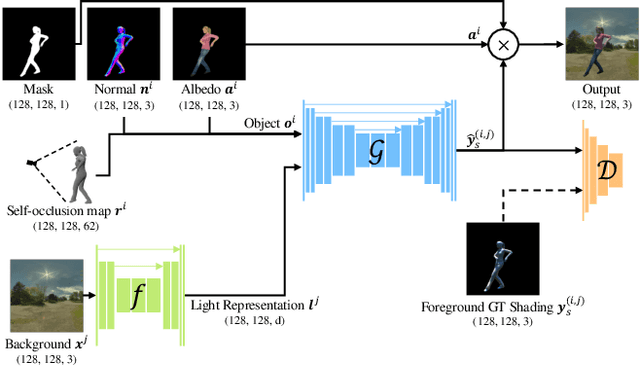
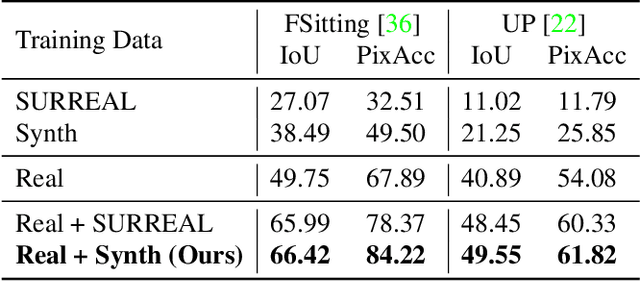
There have been remarkable successes in computer vision with deep learning. While such breakthroughs show robust performance, there have still been many challenges in learning in-depth knowledge, like occlusion or predicting physical interactions. Although some recent works show the potential of 3D data in serving such context, it is unclear how we efficiently provide 3D input to the 2D models due to the misalignment in dimensionality between 2D and 3D. To leverage the successes of 2D models in predicting self-occlusions, we design Ray-marching in Camera Space (RiCS), a new method to represent the self-occlusions of foreground objects in 3D into a 2D self-occlusion map. We test the effectiveness of our representation on the human image harmonization task by predicting shading that is coherent with a given background image. Our experiments demonstrate that our representation map not only allows us to enhance the image quality but also to model temporally coherent complex shadow effects compared with the simulation-to-real and harmonization methods, both quantitatively and qualitatively. We further show that we can significantly improve the performance of human parts segmentation networks trained on existing synthetic datasets by enhancing the harmonization quality with our method.
Diversity-Sensitive Conditional Generative Adversarial Networks
Jan 25, 2019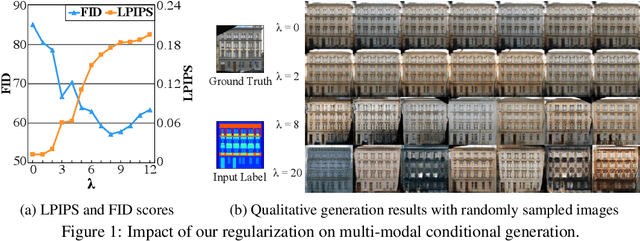
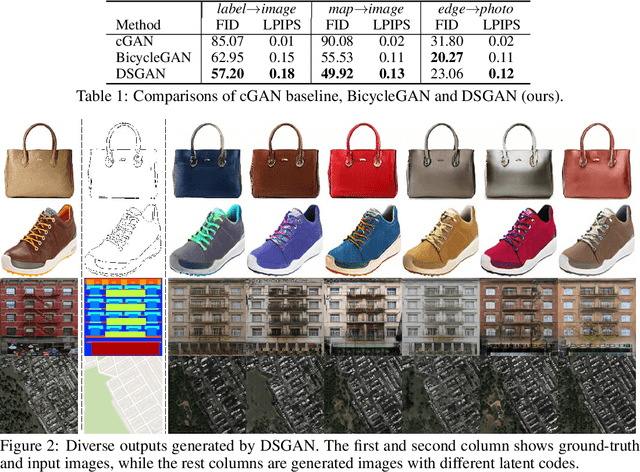
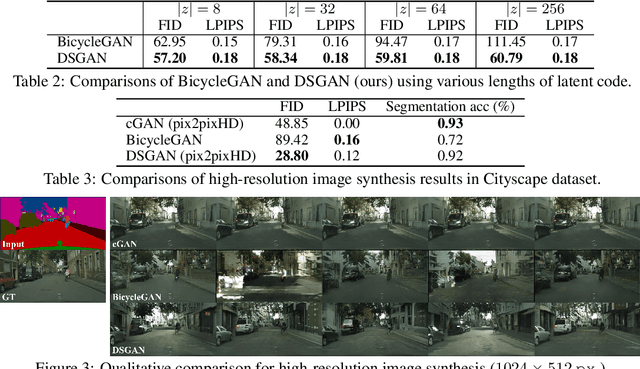

We propose a simple yet highly effective method that addresses the mode-collapse problem in the Conditional Generative Adversarial Network (cGAN). Although conditional distributions are multi-modal (i.e., having many modes) in practice, most cGAN approaches tend to learn an overly simplified distribution where an input is always mapped to a single output regardless of variations in latent code. To address such issue, we propose to explicitly regularize the generator to produce diverse outputs depending on latent codes. The proposed regularization is simple, general, and can be easily integrated into most conditional GAN objectives. Additionally, explicit regularization on generator allows our method to control a balance between visual quality and diversity. We demonstrate the effectiveness of our method on three conditional generation tasks: image-to-image translation, image inpainting, and future video prediction. We show that simple addition of our regularization to existing models leads to surprisingly diverse generations, substantially outperforming the previous approaches for multi-modal conditional generation specifically designed in each individual task.
Video Prediction with Appearance and Motion Conditions
Jul 07, 2018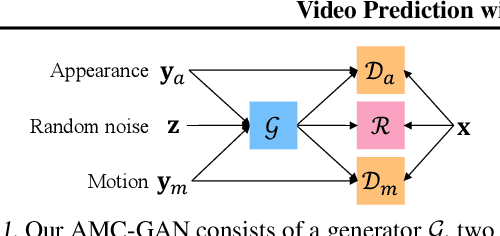
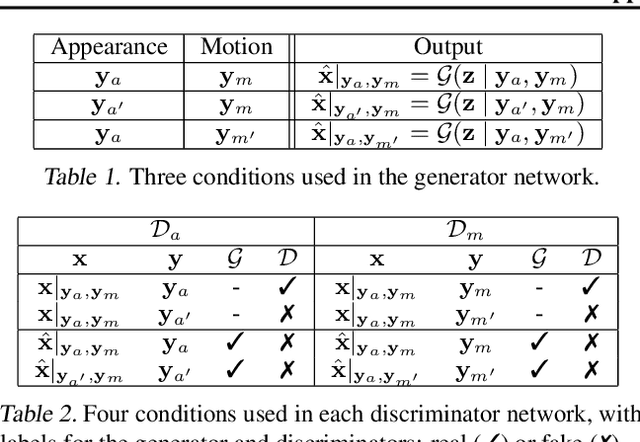
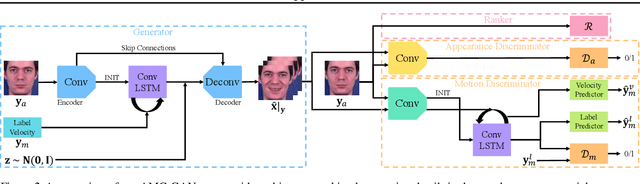

Video prediction aims to generate realistic future frames by learning dynamic visual patterns. One fundamental challenge is to deal with future uncertainty: How should a model behave when there are multiple correct, equally probable future? We propose an Appearance-Motion Conditional GAN to address this challenge. We provide appearance and motion information as conditions that specify how the future may look like, reducing the level of uncertainty. Our model consists of a generator, two discriminators taking charge of appearance and motion pathways, and a perceptual ranking module that encourages videos of similar conditions to look similar. To train our model, we develop a novel conditioning scheme that consists of different combinations of appearance and motion conditions. We evaluate our model using facial expression and human action datasets and report favorable results compared to existing methods.