 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGALA: Geometry-Aware Local Adaptive Grids for Detailed 3D Generation
Oct 13, 2024



We propose GALA, a novel representation of 3D shapes that (i) excels at capturing and reproducing complex geometry and surface details, (ii) is computationally efficient, and (iii) lends itself to 3D generative modelling with modern, diffusion-based schemes. The key idea of GALA is to exploit both the global sparsity of surfaces within a 3D volume and their local surface properties. Sparsity is promoted by covering only the 3D object boundaries, not empty space, with an ensemble of tree root voxels. Each voxel contains an octree to further limit storage and compute to regions that contain surfaces. Adaptivity is achieved by fitting one local and geometry-aware coordinate frame in each non-empty leaf node. Adjusting the orientation of the local grid, as well as the anisotropic scales of its axes, to the local surface shape greatly increases the amount of detail that can be stored in a given amount of memory, which in turn allows for quantization without loss of quality. With our optimized C++/CUDA implementation, GALA can be fitted to an object in less than 10 seconds. Moreover, the representation can efficiently be flattened and manipulated with transformer networks. We provide a cascaded generation pipeline capable of generating 3D shapes with great geometric detail.
BRIGHT: Bi-level Feature Representation of Image Collections using Groups of Hash Tables
May 31, 2023We present BRIGHT, a bi-level feature representation for an image collection, consisting of a per-image latent space on top of a multi-scale feature grid space. Our representation is learned by an autoencoder to encode images into continuous key codes, which are used to retrieve features from groups of multi-resolution hash tables. Our key codes and hash tables are trained together continuously with well-defined gradient flows, leading to high usage of the hash table entries and improved generative modeling compared to discrete Vector Quantization (VQ). Differently from existing continuous representations such as KL-regularized latent codes, our key codes are strictly bounded in scale and variance. Overall, feature encoding by BRIGHT is compact, efficient to train, and enables generative modeling over the image codes using state-of-the-art generators such as latent diffusion models(LDMs). Experimental results show that our method achieves comparable reconstruction results to VQ methods while having a smaller and more efficient decoder network. By applying LDM over our key code space, we achieve state-of-the-art performance on image synthesis on the LSUN-Church and human-face datasets.
AvatarGen: A 3D Generative Model for Animatable Human Avatars
Nov 26, 2022
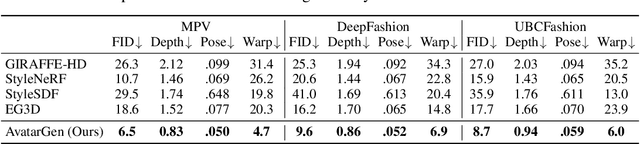
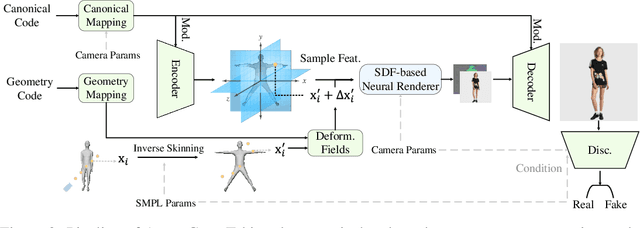
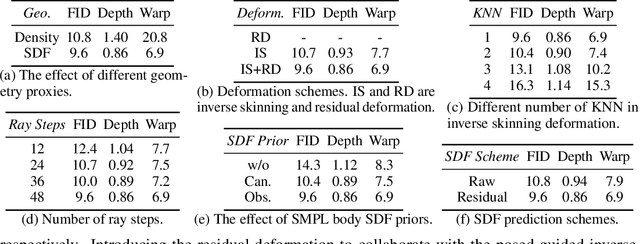
Unsupervised generation of 3D-aware clothed humans with various appearances and controllable geometries is important for creating virtual human avatars and other AR/VR applications. Existing methods are either limited to rigid object modeling, or not generative and thus unable to generate high-quality virtual humans and animate them. In this work, we propose AvatarGen, the first method that enables not only geometry-aware clothed human synthesis with high-fidelity appearances but also disentangled human animation controllability, while only requiring 2D images for training. Specifically, we decompose the generative 3D human synthesis into pose-guided mapping and canonical representation with predefined human pose and shape, such that the canonical representation can be explicitly driven to different poses and shapes with the guidance of a 3D parametric human model SMPL. AvatarGen further introduces a deformation network to learn non-rigid deformations for modeling fine-grained geometric details and pose-dependent dynamics. To improve the geometry quality of the generated human avatars, it leverages the signed distance field as geometric proxy, which allows more direct regularization from the 3D geometric priors of SMPL. Benefiting from these designs, our method can generate animatable 3D human avatars with high-quality appearance and geometry modeling, significantly outperforming previous 3D GANs. Furthermore, it is competent for many applications, e.g., single-view reconstruction, re-animation, and text-guided synthesis/editing. Code and pre-trained model will be available at http://jeff95.me/projects/avatargen.html.
D2HNet: Joint Denoising and Deblurring with Hierarchical Network for Robust Night Image Restoration
Jul 14, 2022
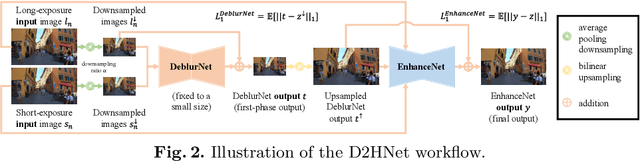
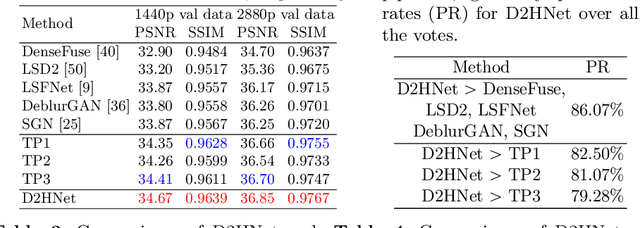
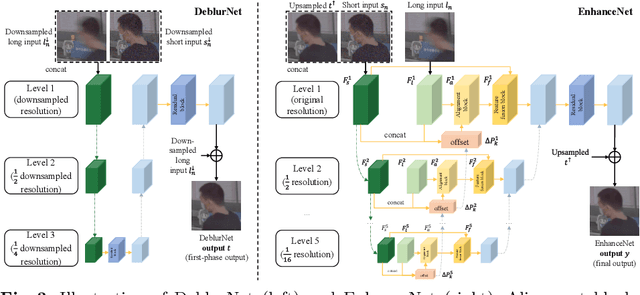
Night imaging with modern smartphone cameras is troublesome due to low photon count and unavoidable noise in the imaging system. Directly adjusting exposure time and ISO ratings cannot obtain sharp and noise-free images at the same time in low-light conditions. Though many methods have been proposed to enhance noisy or blurry night images, their performances on real-world night photos are still unsatisfactory due to two main reasons: 1) Limited information in a single image and 2) Domain gap between synthetic training images and real-world photos (e.g., differences in blur area and resolution). To exploit the information from successive long- and short-exposure images, we propose a learning-based pipeline to fuse them. A D2HNet framework is developed to recover a high-quality image by deblurring and enhancing a long-exposure image under the guidance of a short-exposure image. To shrink the domain gap, we leverage a two-phase DeblurNet-EnhanceNet architecture, which performs accurate blur removal on a fixed low resolution so that it is able to handle large ranges of blur in different resolution inputs. In addition, we synthesize a D2-Dataset from HD videos and experiment on it. The results on the validation set and real photos demonstrate our methods achieve better visual quality and state-of-the-art quantitative scores. The D2HNet codes and D2-Dataset can be found at https://github.com/zhaoyuzhi/D2HNet.
Diversity-Sensitive Conditional Generative Adversarial Networks
Jan 25, 2019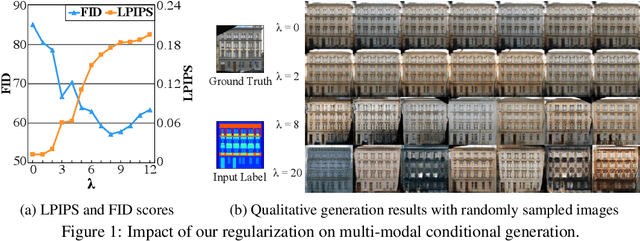
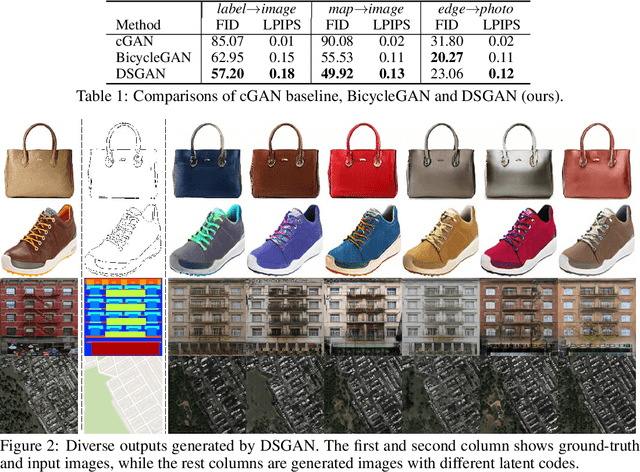
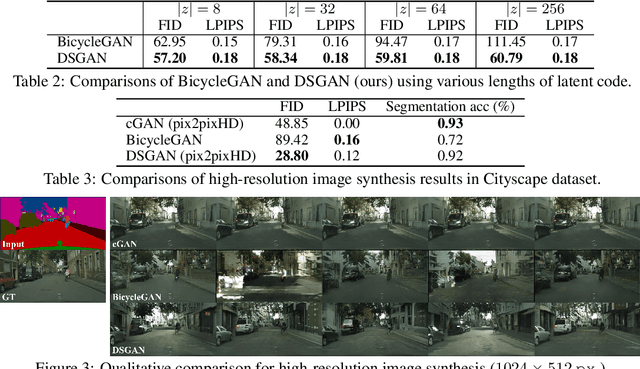

We propose a simple yet highly effective method that addresses the mode-collapse problem in the Conditional Generative Adversarial Network (cGAN). Although conditional distributions are multi-modal (i.e., having many modes) in practice, most cGAN approaches tend to learn an overly simplified distribution where an input is always mapped to a single output regardless of variations in latent code. To address such issue, we propose to explicitly regularize the generator to produce diverse outputs depending on latent codes. The proposed regularization is simple, general, and can be easily integrated into most conditional GAN objectives. Additionally, explicit regularization on generator allows our method to control a balance between visual quality and diversity. We demonstrate the effectiveness of our method on three conditional generation tasks: image-to-image translation, image inpainting, and future video prediction. We show that simple addition of our regularization to existing models leads to surprisingly diverse generations, substantially outperforming the previous approaches for multi-modal conditional generation specifically designed in each individual task.
Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis
Jul 26, 2018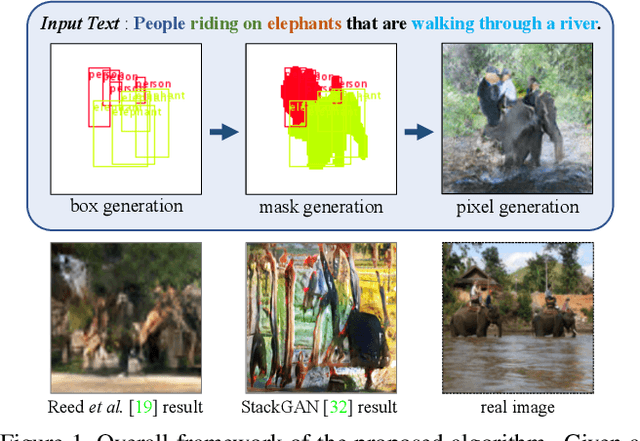
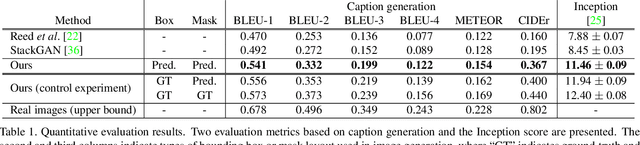
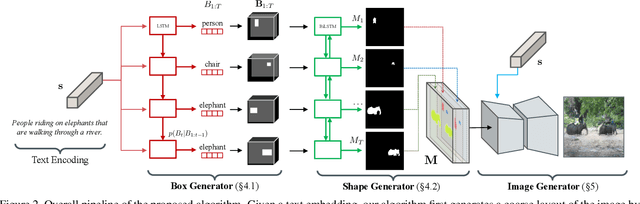
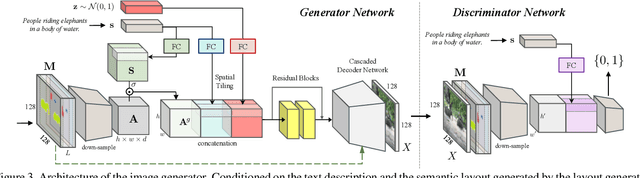
We propose a novel hierarchical approach for text-to-image synthesis by inferring semantic layout. Instead of learning a direct mapping from text to image, our algorithm decomposes the generation process into multiple steps, in which it first constructs a semantic layout from the text by the layout generator and converts the layout to an image by the image generator. The proposed layout generator progressively constructs a semantic layout in a coarse-to-fine manner by generating object bounding boxes and refining each box by estimating object shapes inside the box. The image generator synthesizes an image conditioned on the inferred semantic layout, which provides a useful semantic structure of an image matching with the text description. Our model not only generates semantically more meaningful images, but also allows automatic annotation of generated images and user-controlled generation process by modifying the generated scene layout. We demonstrate the capability of the proposed model on challenging MS-COCO dataset and show that the model can substantially improve the image quality, interpretability of output and semantic alignment to input text over existing approaches.